


來源:新智元
最近,IBM推出一款14nm模擬AI芯片,能效已達最先進GPU的14倍。英偉達的芯片壟斷,或許有望被打破了?
最近,IBM推出一款全新的14nm模擬AI芯片,效率達到了最領先GPU的14倍,可以讓H100物有所值。

論文地址:https://www.nature.com/articles/s41928-023-01010-1
目前,生成式AI發展道路上最大的攔路虎,就是它驚人的耗電量。AI所需的資源,是不可持續增長的。
而IBM,一直在研究重塑AI計算的方法。他們的一大成就,就是模擬內存計算/模擬人工智能方法,就可以借助神經網絡在生物大腦中運行的關鍵特征,來減少能耗。
這種方法,可以最大限度地減少我們在計算上花費的時間和精力。
英偉達的壟斷,要被顛覆了?

IBM AI未來的最新藍圖:模擬AI芯片能效高出14倍
根據外媒Insider的報道,半導體研究公司SemiAnalysis的首席分析師Dylan Patel分析,ChatGPT每天的運行成本超過了70萬美元。
ChatGPT需要大量算力,才能根據用戶的提示生成回答。絕大部分成本,都是在昂貴的服務器上產生的。
在往后,訓練模型和運行基礎設施的成本只會越來越飆升。

IBM在Nature上發文表示,這款全新芯片能夠通過削減能耗,來緩解構建和運營Midjourney或GPT-4等生成式AI企業的壓力。
這些模擬芯片與數字芯片有不同的構建方式,數字芯片可以操作模擬信號,理解0到1之間的漸變,但只適用于不同的二進制信號。
模擬內存計算/模擬AI
而IBM的全新方法,就是模擬內存計算,或簡稱模擬AI。它借助神經網絡在生物大腦中運行的關鍵特征,來減輕了能耗。
在人類和其他動物的大腦中,突觸的強度(或‘權重’)決定了神經元之間的交流。
對于模擬AI系統,IBM將這些突觸權重存儲在納米級電阻存儲器器件(如相變存儲器PCM)的電導值中,并利用電路定律,減少在存儲器和處理器之間不斷發送數據的需求,執行乘法累加(MAC)運算——DNN中的主要運算。
現在為很多生成式AI平臺提供動力的,是英偉達的H100和A100。
然而,如果IBM對芯片原型進行迭代,并且成功推向了大眾市場,這種新型芯片就很有可能取代英偉達,成為全新的支柱。
這款14nm模擬AI芯片,可以為每個組件編碼3500萬個相變存儲設備,可以模擬多達1700萬個參數。
并且,這款芯片模仿了人腦的運作方式,由微芯片直接在內存中執行計算。
這款芯片的系統能夠實現高效的語音識別和轉錄,準確性接近了數字硬件設施。
而這款芯片大約達到了14倍,而之前的模擬表明,這種硬件的能效甚至達到了當今最領先GPU的40倍到140倍。

這場生成式AI革命,才剛剛開始。而深度神經網絡(DNN)徹底改變了AI領域,隨著基礎模型和生成式AI的發展而日益突出。
然而,在傳統的數學計算架構上運行這些模型,會限制它們的性能和能源效率。
雖然在開發用于AI推理的硬件方面,也取得了不少進展,但其中許多架構,在物理上拆分了內存和處理單元。
這就意味著,AI模型通常存儲在離散的內存位置,要完成計算任務,就需要在內存和處理單元之間不斷打亂數據。這個過程會大大減慢計算速度,限制可實現的最大能效。
PCM設備的性能特點、使用相位配置和導納來存儲模擬式的突觸權重
IBM的基于相變存儲器(PCM)的人工智能加速芯片,擺脫了這種限制。
相變存儲器(PCM)可以實現計算存儲融合,在存儲器內直接進行矩陣向量乘法,避免了數據傳輸的問題。
同時,IBM的模擬AI芯片通過硬件級的計算存儲融合,實現了高效的人工智能推理加速,是這一領域的重要進展。
模擬AI的兩大關鍵挑戰
為了將模擬AI的概念變為現實,需要克服兩個關鍵挑戰:
1. 存儲器陣列的計算精度必須與現有數字系統相當
2. 存儲器陣列能與其他數字計算單元以及模擬人工智能芯片上的數字通信結構無縫對接
IBM在Albany Nano的技術中心制造了著這種基于相變內存的人工智能加速芯片。
該芯片由64個模擬內存計算內核組成,每個內核包含256×256的交叉條陣突觸單元。
并且,每個芯片中都集成了緊湊的時基模數轉換器,用于在模擬和數字世界之間進行轉換。
而芯片中的輕量級數字處理單元,也可執行簡單的非線性神經元激活函數和縮放操作。
每個核心可看作一個tile,可以進行與深度神經網絡(DNN)模型的一個層(比如卷積層)相關的矩陣向量乘法及其他運算。
權重矩陣被編碼成PCM器件的模擬電導值存于芯片上。
在芯片的核心陣列中間集成了一個全局數字處理單元,用來實現一些比矩陣向量乘法更復雜的運算,這對某些類型的神經網絡(如LSTM)執行是關鍵的。
芯片上在所有核心以及全局數字處理單元之間集成了數字通信通路,用于核心之間以及核心與全局單元之間的數據傳輸。
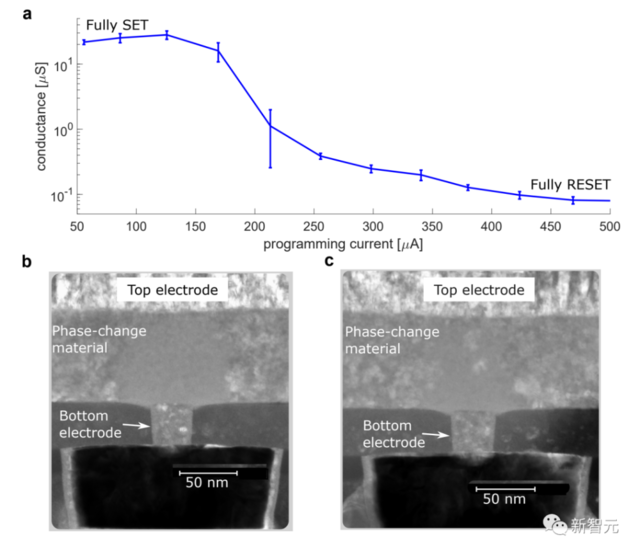
用該芯片,IBM對模擬內存計算的計算精度進行了全面的研究,并在CIFAR-10圖像數據集上獲得了92.81%的精確度。
這是目前所報道的使用類似技術的芯片中精度最高的。
IBM還將模擬內存計算與多個數字處理單元和數字通信結構無縫結合。
該芯片8位輸入輸出矩陣乘法的單位面積吞吐量為400 GOPS/mm2,比以前基于電阻式存儲器的多核內存計算芯片高出15倍以上,同時實現了相當的能效。
而在字符預測任務和圖像標注生成任務中,IBM通過在硬件上測量的結果與其他方法的比較,展示了相關任務在模擬AI芯片上運行的網絡結構、權重編程以及測量結果的信息。
權重編程過程
英偉達的護城河深不見底?
英偉達的壟斷,有這么容易打破嗎?
Naveen Rao是一名神經科學出身的科技企業家,他曾試圖與全球領先的人工智能制造商英偉達競爭。
‘每個人都是基于英偉達進行開發的。’Rao說,‘如果你想推出新的硬件,你就得趕上去和英偉達競爭。’
Rao在英特爾收購的一家初創企業中致力開發旨在取代英偉達GPU的芯片,但在離開英特爾后,他在自己領導的軟件初創公司MosaicML里使用了英偉達的芯片。
Rao表示,英偉達不僅在芯片上與其他產品拉開了巨大的差距,還通過創建一個大型的AI程序員社區,實現了芯片之外的差異化——
AI程序員一直在使用該公司的技術進行創新。
十多年來,英偉達在生產能夠執行復雜AI任務(如圖像、面部和語音識別)以及為ChatGPT等聊天機器人生成文本的芯片方面,建立了幾乎無法撼動的領先地位。
這家曾經的行業新貴之所以能夠取得AI芯片制造的主導地位,是因為它很早就認識到了AI發展的趨勢,為這些任務專門定制了芯片,并開發了促進AI開發的關鍵軟件。
從那時起,英偉達的聯合創始人兼CEO黃仁勛,就在不斷地提高英偉達標準。
這使得英偉達成為了人工智能開發的一站式供應商。
據研究公司Omdia調查,雖然谷歌、亞馬遜、Meta、IBM和其他公司也生產人工智能芯片,但到目前,英偉達占人工智能芯片銷售額的70%以上。
今年6月,英偉達的市值已突破1萬億美元,成為全球市值最高的芯片制造商。
FuturumGroup分析師表示:‘客戶會等18個月才購買英偉達系統,而不是從初創企業或其他競爭對手那里購買現成的芯片。這太不可思議了。’
英偉達,重塑計算方式
1993年,黃仁勛聯合創立了英偉達,主要的業務是制造在電子游戲中渲染圖像的芯片。當時的標準微處理器擅長按順序執行復雜的計算,但英偉達生產的GPU可以同時處理多個簡單任務。
2006年,黃仁勛進一步推進了這一進程。他發布了名為CUDA的軟件技術,該技術可幫助GPU為新任務編程,使GPU從單一用途的芯片轉變為更通用的芯片,能承擔物理和化學模擬等領域的其他工作。
2012年,研究人員利用GPU在識別圖像中的貓等任務中實現了與人類相似的準確度,這是一項重大突破,也是根據文本提示生成圖像等最新發展的先驅。
而據該英偉達估計,這項工作在十年間耗資超過300億美元,使英偉達不再僅僅是一個零部件供應商。除了與頂尖科學家和初創企業合作,公司還組建了一支團隊,直接參與人工智能活動,如創建和訓練語言模型。
此外,從業者的需要導致英偉達開發了CUDA以外的多層關鍵軟件,其中也包括數百條預構建代碼的庫。
在硬件方面,英偉達因每兩三年就能持續提供更快的芯片而贏得聲譽。2017年英偉達開始調整GPU以處理特定的AI計算。
去年9月,英偉達宣布生產名為H100的新型芯片,并對其進行了改進,以處理所謂的Transformer運算。這種運算被證明是ChatGPT等服務的基礎,黃仁勛稱之為生成式人工智能的‘iPhone時刻’。

如今,除非有其他廠家的產品能和英偉達的GPU形成正面競爭,才有可能打破目前英偉達對AI算力的壟斷格局。
IBM的模擬AI芯片,有這個可能嗎?
本文來自新智元,原文標題:《挑戰英偉達H100霸權!IBM模擬人腦造神經網絡芯片,效率提升14倍,破解AI模型耗電難題》
風險提示及免責條款
市場有風險,投資需謹慎。本文不構成個人投資建議,也未考慮到個別用戶特殊的投資目標、財務狀況或需要。用戶應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。


責任編輯:周唯


VIP課程推薦
APP專享直播
熱門推薦
收起
24小時滾動播報最新的財經資訊和視頻,更多粉絲福利掃描二維碼關注(sinafinance)




