

Python文檔字符串生成器:基于CodeBERT,支持Google、Numpy等多種輸出格式
原標題:Python文檔字符串生成器:基于CodeBERT,支持Google、Numpy等多種輸出格式 來源:量子位
關注前沿科技
木易 發(fā)自 凹非寺?
量子位 報道 | 公眾號 QbitAI
木易 發(fā)自 凹非寺?
量子位 報道 | 公眾號 QbitAI
又一款懶人神器問世了:
Visual Studio Code的擴展,基于CodeBERT的Python文檔字符串生成器。
看來現(xiàn)在,這群偷「懶」的程序員們連文檔字符串都不想自己寫了。
基于CodeBERT的生成器
跟正常的DocStrings用法一樣,你只需要輸入三引號「“””」,之后按Enter,便能調(diào)用這個工具。就像這樣:
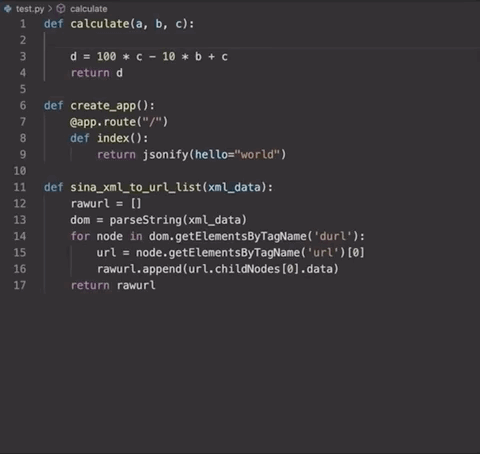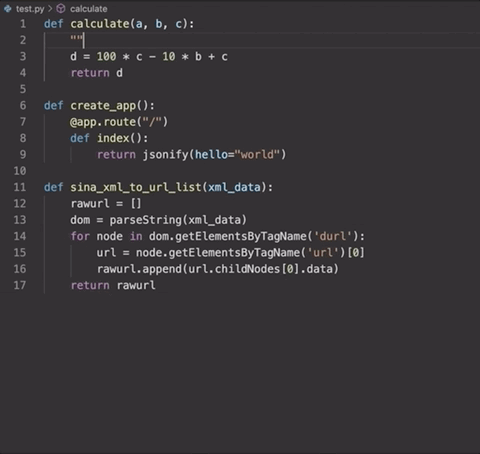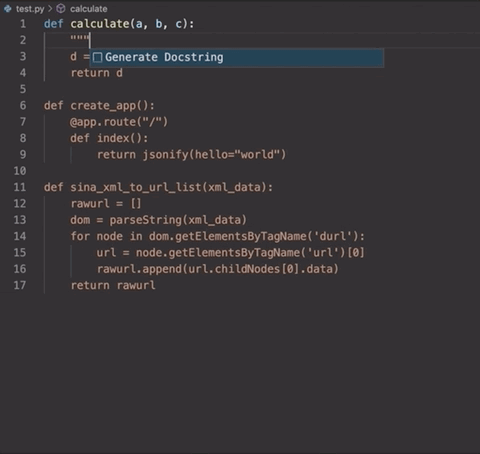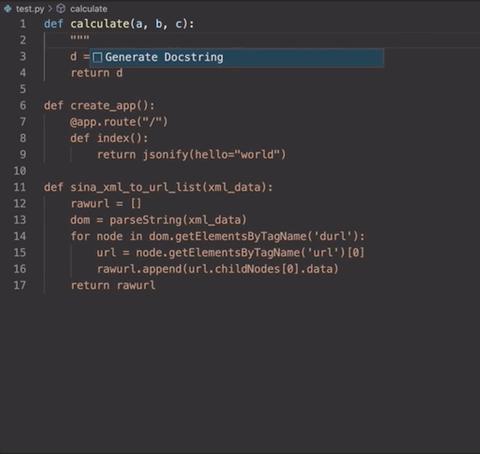
并且,這個生成器還可以在幾種不同類型的文檔字符串格式之間進行選擇。
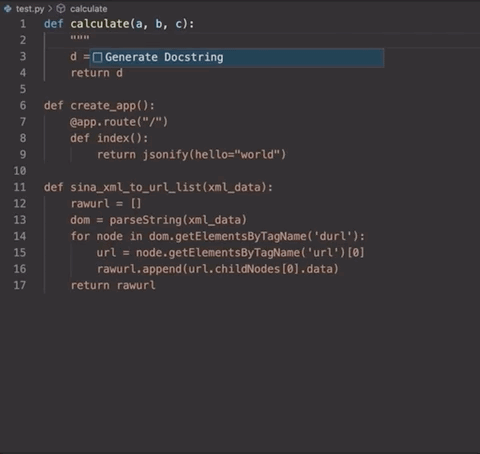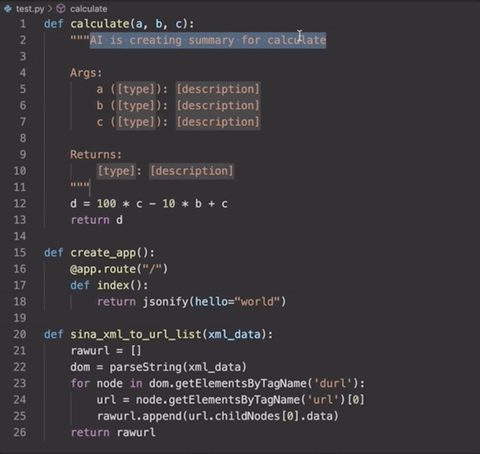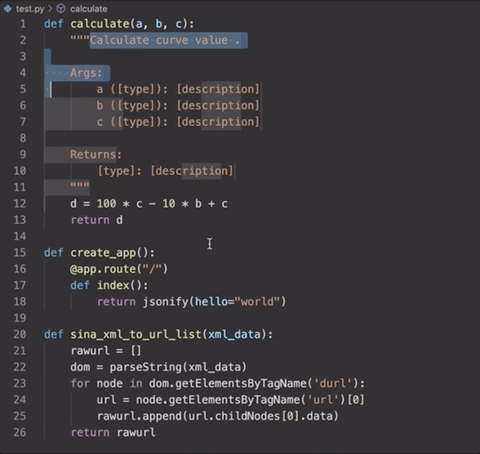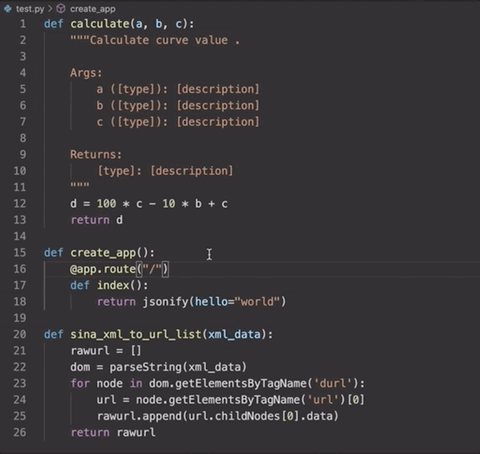
而這個工具,不僅僅能夠幫助寫代碼的人,還可以方便后來人讀代碼。可以說是非常方便的一個擴展了。
這個工具的本質(zhì),就是一個自然語言識別的AI,它能夠識別你所寫代碼的內(nèi)容,然后輸出對應的字符串。
具體是如何識別的,該AI的作者是這么介紹的:
參數(shù)類型是通過PEP 484類型、默認值和var標簽進行識別的。
識別輸入之后便是推斷,這之間進行訓練的方法,也并不復雜,通過CodeBERT便可以實現(xiàn)。
CodeBERT是一種雙模預訓練模型,它可以捕捉自然語言和編程語言之間的語義連接,是目前已知的第一個大型 NL-PL(自然語言-編程語言)預訓練模型。
在訓練過程中,使用 CodeSearchNet 語料庫作為訓練數(shù)據(jù),并使用 CodeBERT 中的 Code2NL微調(diào)任務。
之后,進行的推斷基準測試如下:
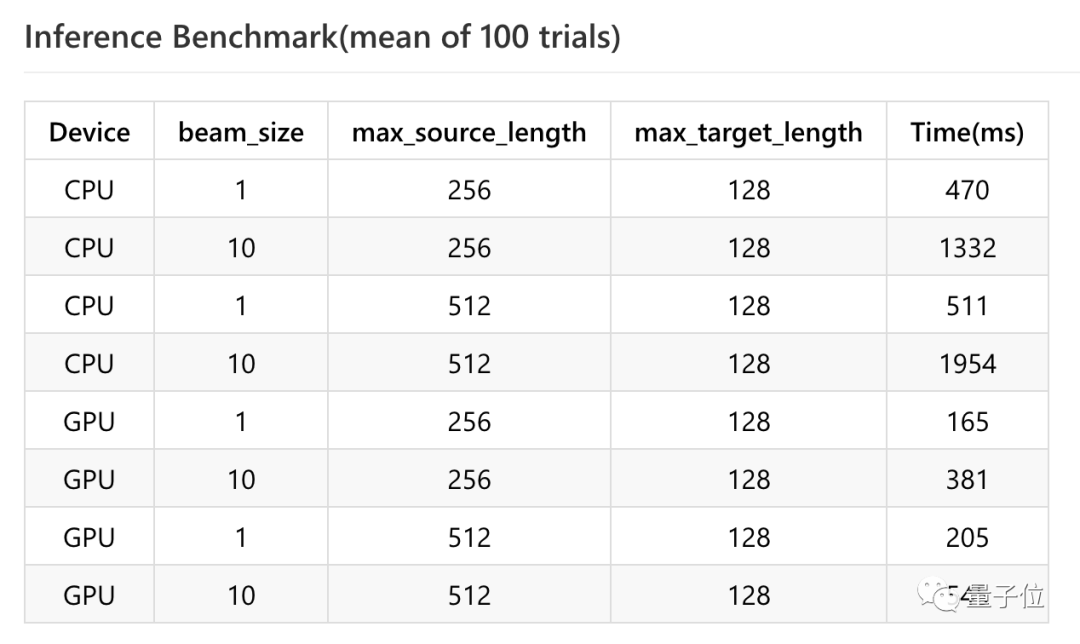
從上圖也能看出,在不同的推斷基準測試中,所需要的生成時間都很短(2s內(nèi)),這體現(xiàn)在操作上的話,就是延遲。
目前,這個生成器可以支持識別args、kwargs、decorators和errors等參數(shù)類型。
此外,還可以輸出Google、docBlockr、Numpy、Sphinx等Docstring格式,PEP0257類型的格式,也即將上線。
使用方法
1、從容器中運行模型推斷服務
具有GPU的話:在安裝nvidia-docker后,運行docker run-it-d-GPU 0-p 5000:5000 gray kode/ai-docstring。
只有CPU:運行docker run-it-d-p 5000:5000 gray kode/ai-docstring。
2、在VSCode中安裝擴展并使用
光標必須在定義正下方的行上,以生成完全自動填充的文檔字符串。
用三重引號「“””或‘’’」打開文檔字符串后,按Enter鍵;
鍵盤快捷鍵是ctrl+shift+2,Mac為cmd+shift+2。
網(wǎng)友討論
該生成器一經(jīng)發(fā)布,便引起了網(wǎng)友們的討論。
有網(wǎng)友認為這是一項非常便利的技術,非常期待:

不過,也有網(wǎng)友認為這項技術仍具有不小的局限性:

比如這位網(wǎng)友認為:更常見的注釋,是在代碼中沒有立即出現(xiàn)的上下文之間添加內(nèi)容。
不過,雖然有局限,但是人總是在「懶」的過程中變得更「懶」(狗頭)。
比如jQuery的流行,是因為開發(fā)者懶得為DOM編寫跨瀏覽器兼容性代碼;
而之后Angular.js的流行,是因為開發(fā)者連DOM都懶得操作。
所以,還是非常期待這個擴展的后續(xù),這些程序員能不能針對這些局限性進一步偷懶的。
獲取資源
目前這個擴展已經(jīng)在Visual Studio Code上免費上線。
進入鏈接即可獲取資源:
https://marketplace.visualstudio.com/items?itemName=graykode.ai-docstring
也可以通過Github獲取源文件:
https://github.com/graykode/ai-docstring
本文系網(wǎng)易新聞?網(wǎng)易號特色內(nèi)容激勵計劃簽約賬號【量子位】原創(chuàng)內(nèi)容,未經(jīng)賬號授權,禁止隨意轉(zhuǎn)載。
「MEET 2021智能未來大會」啟幕,
早鳥票限時搶購中,掃碼預定席位!
李開復博士、尹浩院士、清華唐杰教授,以及來自小米、美團、愛奇藝、小冰、亞信、浪潮、容聯(lián)、澎思、地平線、G7等知名AI大廠的大咖嘉賓齊聚,期待關注AI的朋友報名參會、共探新形勢下智能產(chǎn)業(yè)發(fā)展之路。

量子位?QbitAI · 頭條號簽約作者
?'?' ? 追蹤AI技術和產(chǎn)品新動態(tài)

(聲明:本文僅代表作者觀點,不代表新浪網(wǎng)立場。)

作者簡介
作者文章
推薦閱讀
- 左手瑞幸、右手蛋殼 2020最倒霉的投資人?
-

- 接連兩次翻車,劉二海認輸了嗎?似乎沒有。詳細>>
- 小米可以不自卑 但遠未到驕傲時
-

- 11月24日晚間,小米公布2020年第三季度財報,其中15項業(yè)績創(chuàng)下歷史新高。詳細>>
- 余承東給華為開車
-

- 多年以后,余承東肯定也忘不了十年前的那次座談會。詳細>>
- 想做二手手機供應鏈?轉(zhuǎn)轉(zhuǎn)“負重”難前行
-
- 轉(zhuǎn)轉(zhuǎn)存在的價值到底在哪里呢?詳細>>