


財聯社
當地時間周二,硅谷AI芯片公司Cerebras Systems發布7款類似于GPT的大語言模型。除了發布開源大模型外,展現了一條不用英偉達GPU、不接OpenAI接口也能實現“大模型自由”的道路。
 (來源:公司官網)
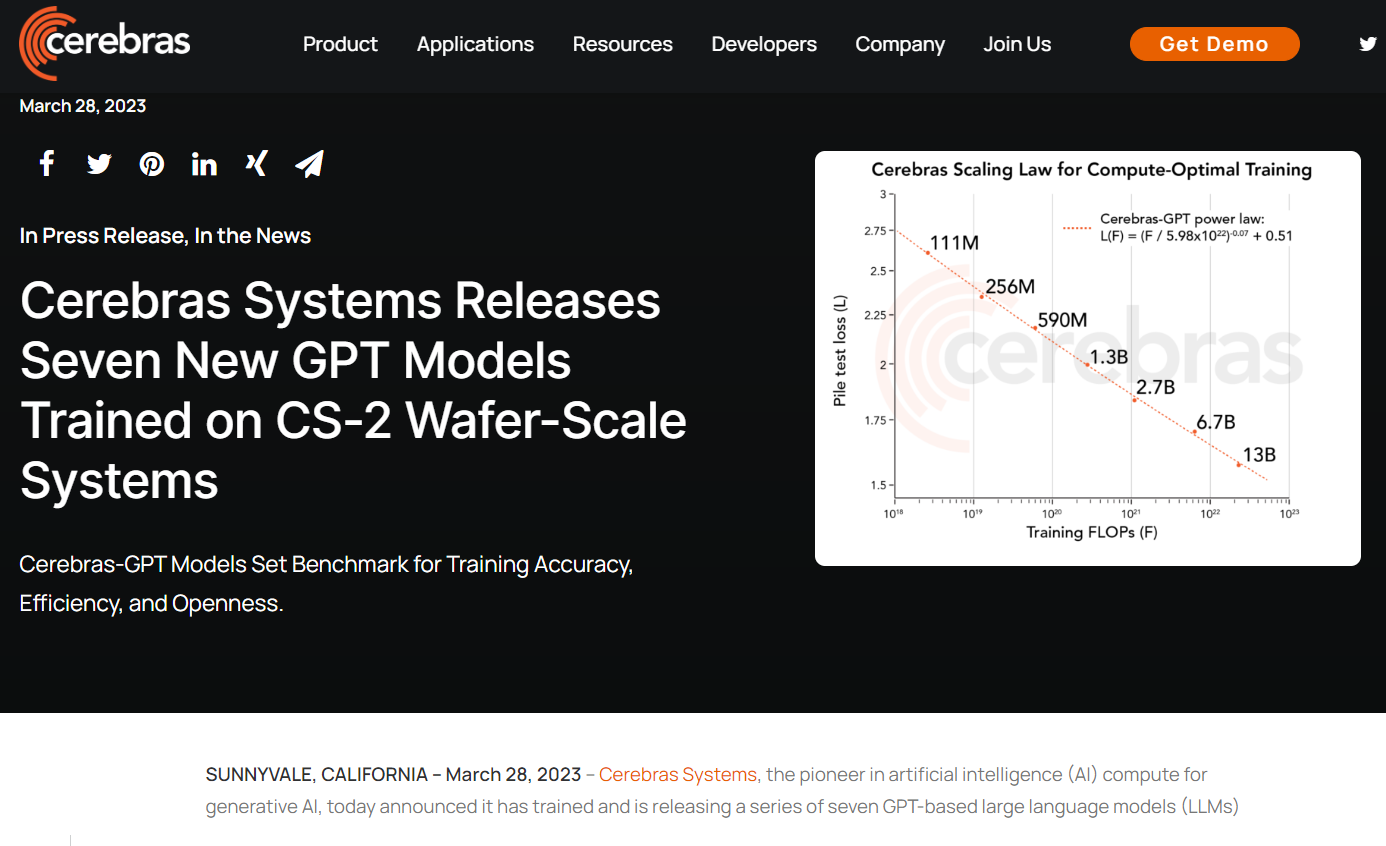
(來源:公司官網)單純從數據來看,這次Cerebras發布的7個大模型參數量介于1.11億至130億之間。作為對比,谷歌的多模態視覺語言模型PaLM-E具有5620億個參數;同樣在本月發布的GPT-4模型雖然尚未公布確切數據,但有媒體援引內部人士透露,參數量大約是GPT-3(1750億)的6倍。
按照目前人類對AI的認知,模型越大,最終能夠滿足的需求就更加復雜。當然,規模較小的模型也有自己的用武之地,例如可以配置在手機、智能音箱中。同時也有研究顯示,規模較小的模型如果經過多次訓練,準確率反倒能變得更高。
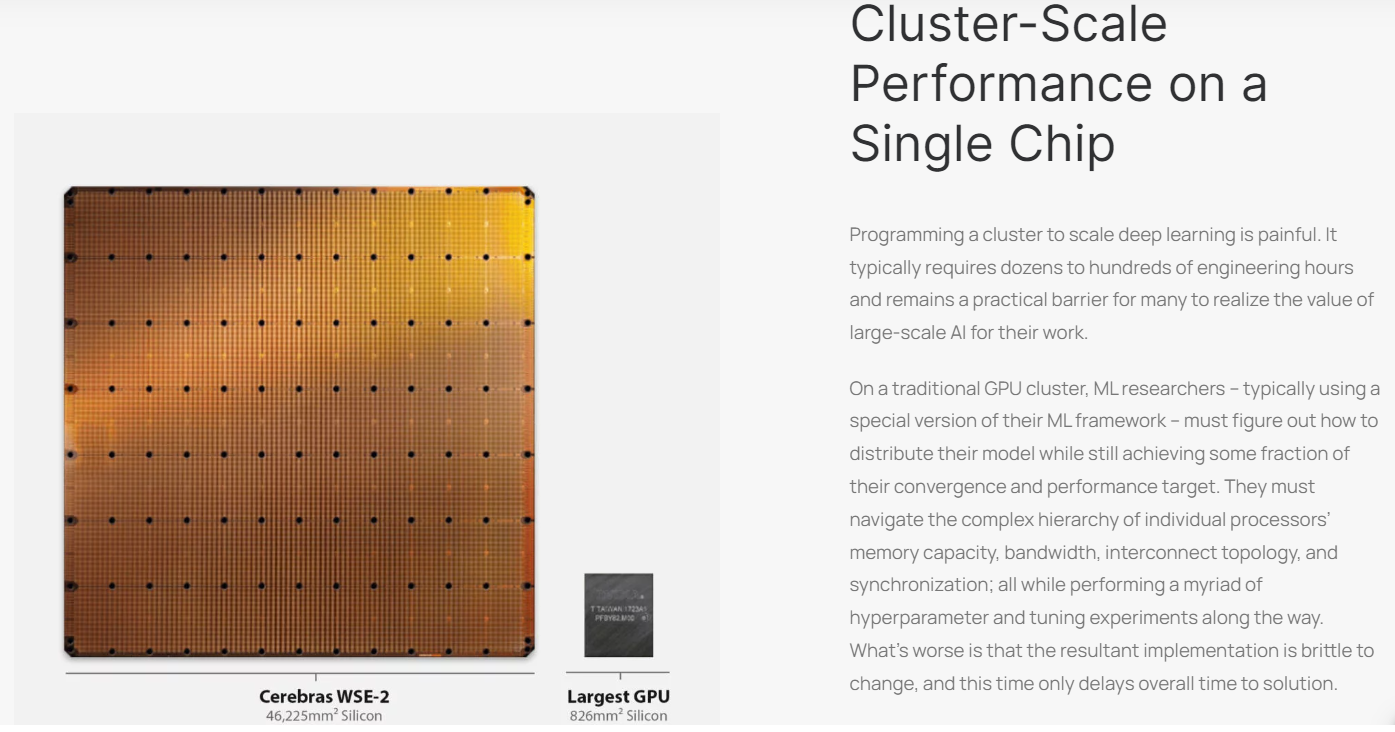
但如同上文所述,Cerebras本身是一家芯片公司,所以訓練模型用的是自家的Andromeda AI超級計算機,其中部署了16套CS-2系統。非常具有記憶點的是,Cerebras生產的AI芯片WSE-2的尺寸約為英偉達A100芯片的56倍,核心數量達到85萬個,同樣是A100芯片的123倍。這塊芯片使用的是臺積電7nm工藝,售價超過200萬美元。
 (來源:Cerebras芯片)
(來源:Cerebras芯片)所以周二發布的多款模型,本身也是Cerebras向AI算力霸主英偉達發出的戰書。在OpenAI的ChatGPT點燃全球科創圈子的熱情后,雖然有許多芯片公司試圖撬動英偉達牢牢占據的市場,但取得實際成果的并不多。許多知名企業,也通過直接用英偉達的全套服務來訓練自家的AI產品,從而快速取得成績。
面向潛在的客戶,Cerebras也強調自己的芯片具有訓練時間短、同等預算下準確率高等優點,是目前世界上已經公開的大模型中生產性價比最高的方案。公司CEO Andrew Feldman也確認,使用Cerebras訓練出來的模型,未來也能在英偉達的系統中繼續訓練和定制化。
多少有些嘲諷OpenAI發布GPT-4后不再開源的做法,Cerebras也在周二宣布公司訓練出來的7個大模型全部在Apache-2.0許可的條件下向研究社區開放,包括模型本身、訓練算法和權重,以此打造行業開源的標桿。
Cerebras表示,任何人只需要向這些高度精準的預訓練模型輸入一定數量的數據,就能以很少的工作量,開發出功能強大垂直行業應用程序。


責任編輯:周唯


VIP課程推薦
APP專享直播
熱門推薦
收起
24小時滾動播報最新的財經資訊和視頻,更多粉絲福利掃描二維碼關注(sinafinance)






