

更精準(zhǔn)地生成字幕!哥大&Facebook開發(fā)AI新框架,多模態(tài)融合,性能更強(qiáng)
來源:量子位
子豪 發(fā)自 凹非寺
量子位 報(bào)道 | 公眾號(hào) QbitAI
現(xiàn)在,給視頻添加字幕,又有了新玩法。
這就是Facebook、哥倫比亞大學(xué)等大學(xué)的新研究,共同開發(fā)了一個(gè)框架——Vx2Text。
這個(gè)框架可以幫助我們,從視頻、音頻等輸入內(nèi)容中提取信息,再以人類可以理解的文字,生成字幕或者回答問題等。
并且,與之前的最新技術(shù)相比,Vx2Text在三個(gè)任務(wù)中均展現(xiàn)出最佳的性能。

Vx2Text究竟是什么?一起往下看。
技術(shù)原理
Vx2Text是從多模態(tài)輸入(由視頻、文本、語音或音頻組成)中提取信息,再以人類可以理解的方式,生成自然語言文本(例如:字幕、回答問題等)。
研究團(tuán)隊(duì)通過引入大型基準(zhǔn),來評(píng)估Vx2Text解釋信息和生成自然語言的能力。
這些基準(zhǔn)主要包括:用于圖像或視頻字幕、問答(QA)和視聽對(duì)話的數(shù)據(jù)集。
為了在這些基準(zhǔn)測(cè)試中表現(xiàn)出色,Vx2Text必須完成幾個(gè)目標(biāo):
從每個(gè)模態(tài)中提取重要信息;
有效地組合不同線索,以解決給定的問題;
以可理解的文本形式,將結(jié)果生成和呈現(xiàn)出來。
并且,將這些目標(biāo)嵌入一個(gè)統(tǒng)一的、端到端的可訓(xùn)練的框架中。
整個(gè)過程可以分為三步:
多模態(tài)輸入及識(shí)別;
將不同模態(tài)嵌入同一語言空間;
融合多模態(tài)信息。
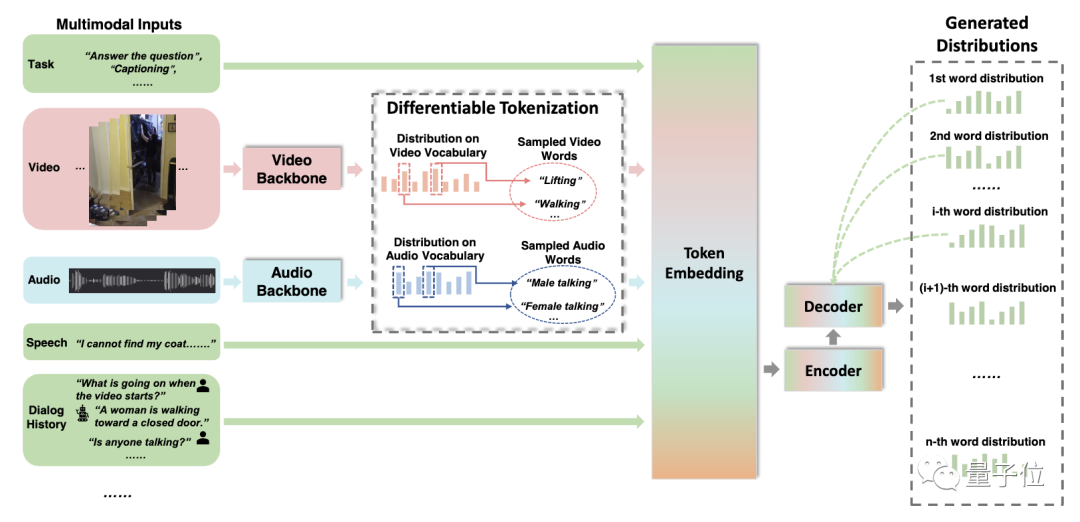
具體而言:
輸入及識(shí)別
Vx2Text接收視頻、音頻和語音作為輸入。利用特定模態(tài)分類器,來識(shí)別輸入的聲音或動(dòng)作等,得到相應(yīng)類別的文本信息。
嵌入
通過可區(qū)分標(biāo)記化,將識(shí)別得到的不同模態(tài)的文本信息,嵌入同一語言空間中,以便執(zhí)行多模態(tài)融合,實(shí)現(xiàn)端到端的訓(xùn)練。
多模態(tài)融合,簡(jiǎn)單來說就是,將從文本、圖像、語音、視頻等多種形式的數(shù)據(jù)和信息,進(jìn)行轉(zhuǎn)換和融合。
先前不同模態(tài)輸入信號(hào)的組合方法,大多依賴于額外的跨模態(tài)融合模塊,繁重且計(jì)算成本高。
而使用Vx2Text,無需設(shè)計(jì)專門的跨模態(tài)網(wǎng)絡(luò)模塊,這種設(shè)計(jì)不僅簡(jiǎn)單得多,還可以帶來更好的性能。
融合
采用通用的編-解碼器語言模型,即自回歸解碼器模型,來融合多模態(tài)信息,以生成文本。
不同于以前的僅編碼器模型,這一模型具有通用性,能直接適用于“不同模態(tài)生成文本”問題,無縫處理兩種類型的任務(wù),無需為每個(gè)任務(wù)設(shè)計(jì)專門的架構(gòu)。
處理生成式任務(wù),需要通過解碼生成連貫的句子;
處理區(qū)分式任務(wù),則需將候選答案集輸入,在概率分布下,選擇最高概率的答案。
實(shí)驗(yàn)
對(duì)Vx2Text在三個(gè)任務(wù)中的有效性進(jìn)行評(píng)估:包括視頻問答、視聽場(chǎng)景感知對(duì)話和視頻字幕。
分別使用三個(gè)基準(zhǔn)數(shù)據(jù)集:TVQA、AVSD和TVC。
評(píng)估每種模態(tài)的重要性

使用不同的輸入組合,評(píng)估各個(gè)模態(tài)對(duì)基于視頻的文本生成性能的影響。結(jié)果表明:
在AVSD和TVQA數(shù)據(jù)集中,每種模態(tài)都有助于性能提升,對(duì)于AVSD尤其明顯。
在AVSD的所有指標(biāo)下,增加視頻模態(tài)的都會(huì)帶來性能提升;TVQA數(shù)據(jù)集也體現(xiàn)這種趨勢(shì)。
此外,問答的歷史記錄對(duì)AVSD的性能,也起到十分積極的作用。這表明模型在對(duì)話中,成功合并了先前問答的信息。
可區(qū)分標(biāo)記化的的有效性
將不同的模態(tài)融合機(jī)制(包括:多模態(tài)特征嵌入、凍結(jié)標(biāo)記化、可區(qū)分標(biāo)記化),在AVSD和TVQA中的性能進(jìn)行比較,得到結(jié)論:
與多模式特征嵌入相比,凍結(jié)標(biāo)記化實(shí)現(xiàn)了更好的性能。
可區(qū)分標(biāo)記化通過優(yōu)化整個(gè)端到端模型,進(jìn)一步提高了這兩項(xiàng)任務(wù)的性能,在很大程度上優(yōu)于其他方案。
生成模型的優(yōu)勢(shì)

對(duì)四個(gè)模型的準(zhǔn)確性進(jìn)行評(píng)估,得到結(jié)論:
對(duì)于所有大小的訓(xùn)練集,與去掉解碼器的系統(tǒng)判別版本(Discriminative)相比,默認(rèn)的Vx2Text模型(Generative)都更準(zhǔn)確。
此外,生成模型可以使用相同的模型進(jìn)行多任務(wù)學(xué)習(xí),無需更改架構(gòu)。這樣能夠進(jìn)一步提高準(zhǔn)確性,尤其是對(duì)于小型訓(xùn)練集。
與最新技術(shù)的比較

Vx2Text(這里使用凍結(jié)標(biāo)記化,而非可區(qū)分標(biāo)記化)與最新技術(shù),在AVSD上進(jìn)行比較,得到結(jié)論:
在帶有和不帶有字幕輸入兩種情況下,Vx2Text模型都取得了最好的效果。證明了這一模態(tài)集成簡(jiǎn)單方案的有效性。

Vx2Text與最新技術(shù),在TVQA上進(jìn)行比較(數(shù)字代表Top-1準(zhǔn)確性(%)),得到結(jié)論:
在HERO利用額外的樣本進(jìn)行預(yù)訓(xùn)練的情況下,Vx2Text仍然實(shí)現(xiàn)了比HERO版本更好的性能。

Vx2Text與最新技術(shù),在TVC上進(jìn)行對(duì)比,得到結(jié)論:
在不使用額外樣本進(jìn)行預(yù)訓(xùn)練的情況下,Vx2Text展現(xiàn)出最佳的性能。
定性結(jié)論
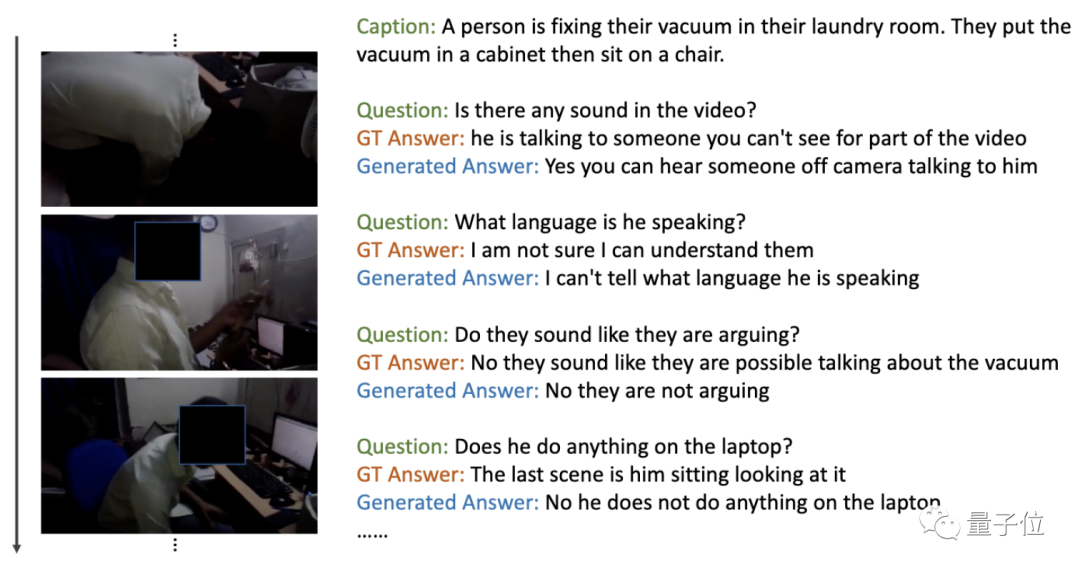 △AVSD驗(yàn)證集上的視聽場(chǎng)景感知對(duì)話任務(wù),Vx2Text生成答案示例
△AVSD驗(yàn)證集上的視聽場(chǎng)景感知對(duì)話任務(wù),Vx2Text生成答案示例
雖然輸入內(nèi)容中包含一些文本,例如:對(duì)話歷史記錄或語音記錄,但生成的文本還包含了來自其他模態(tài)的信息。例如,上圖中模型成功地識(shí)別了動(dòng)作,例如,幫助站起來等。
實(shí)驗(yàn)表明:Vx2Text能夠在多模態(tài)輸入中,為視聽場(chǎng)景感知對(duì)話和視頻字幕,生成逼真自然的文本。
Vx2Text可以用于為錄制的視頻或流媒體視頻添加字幕,以及服務(wù)YouTube和Vimeo等視頻共享平臺(tái),依靠字幕以及其他信號(hào)來改善搜索結(jié)果的相關(guān)性。
作者
論文一作藺旭東,目前是哥倫比亞大學(xué)計(jì)算機(jī)科學(xué)專業(yè)的博士生,主要研究領(lǐng)域是嵌入學(xué)習(xí)、視頻分析和生成模型,本科就讀于清華大學(xué)。這項(xiàng)研究是在其擔(dān)任Facebook AI實(shí)習(xí)生時(shí)完成的。
 △藺旭東(來自其個(gè)人主頁)
△藺旭東(來自其個(gè)人主頁)想要了解更多細(xì)節(jié),可戳文末鏈接查看~
參考鏈接:
https://arxiv.org/abs/2101.12059
https://venturebeat.com/2021/02/02/researchers-Vx2Text-ai-framework-draws-inferences-from-videos-audio-and-text-to-generate-captions/

(聲明:本文僅代表作者觀點(diǎn),不代表新浪網(wǎng)立場(chǎng)。)

作者簡(jiǎn)介
作者文章
推薦閱讀
- 電影吸金,愛優(yōu)騰“搶食”春節(jié)檔
-

- 要建立一種新秩序并不容易,電影出品方要衡量收入是否能最大化,平臺(tái)要看投入產(chǎn)出比高不高,另外還有院線的抵制、觀眾買不買賬等問題。詳細(xì)>>
- 瘋狂的Clubhouse,暴露了國(guó)內(nèi)社交網(wǎng)絡(luò)的倒退
-

- 一碼難求,看著朋友圈中一個(gè)個(gè)曬出Clubhouse的邀請(qǐng)碼,有沒有收到邀請(qǐng)碼已然變成了一種互聯(lián)網(wǎng)江湖地位的象征:越接近中美互聯(lián)網(wǎng)江湖的中心,越是能盡快靠著社交人脈獲得邀請(qǐng)碼,這種自我證明比無形裝逼可高明太多了。詳細(xì)>>
- 世界要變了!2021年科技互聯(lián)網(wǎng)十大趨勢(shì)預(yù)測(cè)
-

- 疫情給全人類帶來挑戰(zhàn)的同時(shí),也激發(fā)了這個(gè)“地球勝利者”的巨大潛力:原本至少要研制三年的疫苗,一年面世;無論中美關(guān)系走向如何,中國(guó)芯片產(chǎn)業(yè)必須找到“自我”……詳細(xì)>>
- 賣得熱鬧掙錢少,奈雪的茶凈利潤(rùn)率僅0.2%
-

- 新消費(fèi)、新茶飲的崛起究竟是光芒還是泡沫?奈雪的茶的這份招股書給出了一些答案。詳細(xì)>>
新聞熱榜
- 01瘋狂的Clubhouse,暴露了國(guó)內(nèi)社交網(wǎng)絡(luò)的倒退...
- 02陳省身高徒在美去世 師徒聯(lián)手創(chuàng)立美國(guó)國(guó)家數(shù)...
- 03世界要變了!2021年科技互聯(lián)網(wǎng)十大趨勢(shì)預(yù)測(cè)...
- 04電影吸金,愛優(yōu)騰“搶食”春節(jié)檔
- 05特斯拉超跑二代或安裝火箭推進(jìn)器 馬斯克:我...
- 06波士頓動(dòng)力母公司最新機(jī)器人,就這?
- 07韓國(guó)電商Coupang沖刺美股:年?duì)I收120億 軟銀...
- 08多項(xiàng)世界第一!起源太空兩個(gè)世界級(jí)探測(cè)器成...
- 09高瓴四季度美股持倉公布:減持蔚來Zoom 加大...
- 10吳曉波:創(chuàng)業(yè)是一場(chǎng)可以量化的行為藝術(shù)