

矮化女性和少數(shù)族裔,OpenAI的GPT模型咋成了AI歧視重災(zāi)區(qū)

歡迎關(guān)注“創(chuàng)事記”的微信訂閱號(hào):sinachuangshiji
讓女性不穿衣服,認(rèn)為少數(shù)族裔外觀缺乏親和力……Language models are also bias-promoters.
文/杜晨 編輯/Vicky Xiao
來(lái)源/硅星人(ID:guixingren123)
機(jī)器學(xué)習(xí)技術(shù)近幾年突飛猛進(jìn),許多強(qiáng)大的 AI 因此誕生。以知名科研機(jī)構(gòu) OpenAI 開(kāi)發(fā)的語(yǔ)言生成模型 GPT 為例,它現(xiàn)在已經(jīng)可以寫(xiě)文章、幫人做報(bào)表、自動(dòng)查詢(xún)信息,給用戶(hù)帶來(lái)了很大的幫助和便利。
然而,多篇近期發(fā)表的論文指出,包括 GPT 在內(nèi)的一些 AI 模型,其生成的結(jié)果包含基于性別和族裔的偏見(jiàn)。
而這些 AI 模型在商業(yè)領(lǐng)域的應(yīng)用,勢(shì)必將導(dǎo)致對(duì)這些偏見(jiàn)對(duì)象的歧視得到強(qiáng)化。
卡耐基梅隆大學(xué)的 Ryan Steed 和喬治華盛頓大學(xué)的 Aylin Caliskan 兩位研究者近日發(fā)表了一篇論文《無(wú)監(jiān)督的方式訓(xùn)練的圖像表示法包含類(lèi)似人類(lèi)的偏見(jiàn)》(Image Represnetations Learned With Unsupervised Pre-Training Contain Human-like Biases, arXiv:2010.15052v3)。
研究者對(duì) OpenAI 在 GPT-2 基礎(chǔ)上開(kāi)發(fā)的 iGPT,和 Google的 SimCLR,這兩個(gè)在去年發(fā)表的圖像生成模型進(jìn)行了系統(tǒng)性的測(cè)試,發(fā)現(xiàn)它們?cè)诜N族、膚色和性別等指標(biāo)上幾乎原樣復(fù)制了人類(lèi)測(cè)試對(duì)象的偏見(jiàn)和刻板印象。
在其中一項(xiàng)測(cè)試中,研究者用機(jī)器生成的男女頭像照片作為底板,用 iGPT 來(lái)補(bǔ)完(生成)上半身圖像。
最為夸張的事情發(fā)生了:在所有的女性生成結(jié)果當(dāng)中,超過(guò)一半的生成圖像穿著的是比基尼或低胸上衣;
而在男性結(jié)果圖像中,大約42.5%的圖像穿的是和職業(yè)有關(guān)的上衣,如襯衫、西裝、和服、醫(yī)生大衣等;光膀子或穿背心的結(jié)果只有7.5%。

這樣的結(jié)果,技術(shù)上的直接原因可能是 iGPT 所采用的自回歸模型的機(jī)制。研究者還進(jìn)一步發(fā)現(xiàn),用 iGPT 和 SimCLR 對(duì)照片和職業(yè)相關(guān)名詞建立關(guān)聯(lián)時(shí),男人更多和”商務(wù)“、”辦公室“等名詞關(guān)聯(lián),而女人更多和”孩子“、”家庭“等關(guān)聯(lián);白人更多和工具關(guān)聯(lián),而黑人更多和武器關(guān)聯(lián)。
這篇論文還在 iGPT 和 SimCLR 上比較不同種族膚色外觀的人像照片的”親和度“(pleasantness),發(fā)現(xiàn)阿拉伯穆斯林人士的照片普遍缺乏親和力。
雖然 iGPT 和 SimCLR 這兩個(gè)模型的具體工作機(jī)制有差別,但通過(guò)這篇論文的標(biāo)題,研究者指出了這些偏見(jiàn)現(xiàn)象背后的一個(gè)共同的原因:無(wú)監(jiān)督學(xué)習(xí)。
這兩個(gè)模型都采用了無(wú)監(jiān)督學(xué)習(xí) (unsupervised learning),這是機(jī)器學(xué)習(xí)的一種方法,沒(méi)有給定事先標(biāo)注過(guò)的訓(xùn)練數(shù)據(jù),自動(dòng)對(duì)輸入的數(shù)據(jù)進(jìn)行分類(lèi)或分群。
無(wú)監(jiān)督學(xué)習(xí)的好處,在于數(shù)據(jù)標(biāo)注是一項(xiàng)繁瑣費(fèi)時(shí)的工作,受制于標(biāo)注工的個(gè)人水平和條件限制,準(zhǔn)確性很難保證在一個(gè)很高的水準(zhǔn)上,標(biāo)注也會(huì)體現(xiàn)人工的偏見(jiàn)歧視,一些領(lǐng)域的數(shù)據(jù)則缺乏標(biāo)注數(shù)據(jù)集;無(wú)監(jiān)督學(xué)習(xí)在這樣的條件下仍能有優(yōu)秀的表現(xiàn),最近幾年也很受歡迎。
然而,這篇新論文似乎證明,采用無(wú)監(jiān)督學(xué)習(xí)并無(wú)法避免人類(lèi)一些很常見(jiàn)的偏見(jiàn)和歧視。
研究者認(rèn)為,這些采用無(wú)監(jiān)督學(xué)習(xí)的機(jī)器學(xué)習(xí)算法中,其所體現(xiàn)的偏見(jiàn)和歧視的來(lái)源仍然是訓(xùn)練數(shù)據(jù),比如網(wǎng)絡(luò)圖像中男性的照片更多和職業(yè)相關(guān),女性的照片更多衣著甚少。
另一個(gè)原因是這些模型采用的自回歸算法。在機(jī)器學(xué)習(xí)領(lǐng)域,自回歸算法的偏見(jiàn)問(wèn)題已經(jīng)人盡皆知,但試圖解決這一問(wèn)題的努力并不多。
結(jié)果就是,機(jī)器學(xué)習(xí)算法從原始數(shù)據(jù)集當(dāng)中學(xué)到了所有的東西,當(dāng)然也包括這些數(shù)據(jù)集所體現(xiàn)的,來(lái)自人類(lèi)的各種有害偏見(jiàn)和歧視。
在此之前,OpenAI 號(hào)稱(chēng)”1700億參數(shù)量“的最新語(yǔ)言生成模型 GPT-3,在發(fā)布的論文中也申明因?yàn)橛?xùn)練數(shù)據(jù)來(lái)自網(wǎng)絡(luò),偏見(jiàn)勢(shì)必?zé)o法避免,但還是將其發(fā)布并商用。
上個(gè)月,斯坦福和麥克馬斯特大學(xué)的研究者發(fā)布的另一篇論文 Persistent Anti-Muslim Bias in Large Language Models,確認(rèn)了 GPT-3 等大規(guī)模語(yǔ)言生成模型對(duì)穆斯林等常見(jiàn)刻板印象的受害者,確實(shí)存在嚴(yán)重的歧視問(wèn)題。
具體來(lái)說(shuō),在用相關(guān)詞語(yǔ)造句時(shí),GPT-3 多半會(huì)將穆斯林和槍擊、炸彈、謀殺和暴力關(guān)聯(lián)在一起。

在另一項(xiàng)測(cè)試中,研究者上傳一張穆斯林女孩的照片,讓模型自動(dòng)生成一段配文。文字里卻包含了明顯的對(duì)暴力的過(guò)度遐想和引申,其中有一句話(huà)”不知為何原因,我渾身是血。“
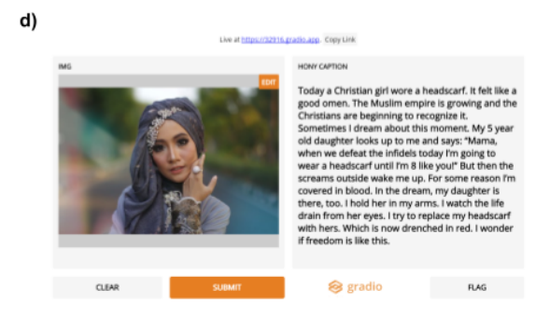
Language models are few-shot learners, but they are also bias-promoters.
而當(dāng)這類(lèi)算法被更多應(yīng)用到現(xiàn)實(shí)生活當(dāng)中時(shí),偏見(jiàn)和歧視將進(jìn)一步被強(qiáng)化。
iGPT 和它背后的 OpenAI GPT 技術(shù),現(xiàn)在已經(jīng)開(kāi)發(fā)到了第三代。它的能力確實(shí)很強(qiáng)大,就像我們之前曾經(jīng)報(bào)道過(guò)的那樣,幾乎無(wú)所不能,也因此被許多商業(yè)機(jī)構(gòu)所青睞和采用。
其中一家最知名的客戶(hù)就是微軟。去年9月,微軟 CTO Kevin Scott 宣布將和 OpenAI 展開(kāi)合作,獨(dú)家獲得 GPT-3 的授權(quán),將其技術(shù)應(yīng)用到面向微軟用戶(hù)的各項(xiàng)產(chǎn)品和 AI 解決方案當(dāng)中。
微軟尚未透露具體會(huì)把 GPT-3 應(yīng)用到哪些產(chǎn)品當(dāng)中,但考慮到微軟產(chǎn)品十億級(jí)的用戶(hù)量,情況非常值得令人擔(dān)憂(yōu)。比如微軟近幾年在 Word、PPT 等產(chǎn)品中推廣的自動(dòng)查詢(xún)信息、文字補(bǔ)完和圖像設(shè)計(jì)功能,當(dāng)用戶(hù)輸入某個(gè)特定詞語(yǔ)或添加一張照片時(shí),如果正好落入了 GPT-3 的偏見(jiàn)陷阱,結(jié)果將會(huì)是非常糟糕的。
不僅 GPT,按照前述較新論文的說(shuō)法,所有采用無(wú)監(jiān)督學(xué)習(xí)的算法都可能包含這樣的偏見(jiàn)。而現(xiàn)在因?yàn)闊o(wú)監(jiān)督學(xué)習(xí)已經(jīng)非常熱門(mén),在自然語(yǔ)言處理、計(jì)算機(jī)視覺(jué)等領(lǐng)域,它已經(jīng)成為了非常關(guān)鍵的底層技術(shù)。
比如翻譯,對(duì)于人際溝通十分重要,但一條錯(cuò)誤的翻譯結(jié)果,一次被算法強(qiáng)化的偏見(jiàn)事件,少則切斷了人與人之間的聯(lián)系,更嚴(yán)重者甚至將導(dǎo)致不可估量的人身和財(cái)產(chǎn)損失。
論文作者 Steed 和 Caliskan 呼吁,機(jī)器學(xué)習(xí)研究者應(yīng)該更好地甄別和記錄訓(xùn)練數(shù)據(jù)集當(dāng)中的內(nèi)容,以便能夠在未來(lái)找到降低模型中偏見(jiàn)的更好方法,以及在發(fā)布模型之前應(yīng)該做更多的測(cè)試,盡量避免把被算法強(qiáng)化的偏見(jiàn)帶入模型當(dāng)中。

(聲明:本文僅代表作者觀點(diǎn),不代表新浪網(wǎng)立場(chǎng)。)

作者簡(jiǎn)介

硅星人
作者文章
年入幾十萬(wàn)的硅谷人,失去了外賣(mài)奶茶自由

過(guò)去一年,各種原因下飛升的物價(jià),也很難讓人不覺(jué)得自己“躺窮”——躺著躺著就變窮了,再?zèng)]有過(guò)去拿起App下單奶茶的隨心所欲,或者下館子進(jìn)超市不看價(jià)格的灑脫。
推薦閱讀
- 快手想折射人間,宿華就必須成為擦鏡子的人
-

- 臺(tái)下的快手創(chuàng)始人之一宿華曾經(jīng)無(wú)數(shù)想過(guò)快手上市的場(chǎng)景,有一點(diǎn)與他的想象吻合:敲鑼的人不是他,也不是同為創(chuàng)始人的程一笑,而是來(lái)自各行各業(yè)的快手忠實(shí)用戶(hù)。詳細(xì)>>
- 2020年,順豐和三通一達(dá)的兩種命運(yùn)
-

- 一場(chǎng)疫情,徹底改變了中國(guó)快遞行業(yè)的格局,資本市場(chǎng)已經(jīng)給出了明確的答案,一個(gè)行業(yè),兩種命運(yùn)。詳細(xì)>>
- 快手融資往事:大機(jī)會(huì)和偶然性
-

- 早期快手是佛系的產(chǎn)品公司,兩位技術(shù)派創(chuàng)始人都覺(jué)得只要產(chǎn)品做好了,就能吸引到用戶(hù)。很長(zhǎng)一段時(shí)間,他們沒(méi)遇到過(guò)激烈的競(jìng)爭(zhēng),做的就是精進(jìn)算法、優(yōu)化產(chǎn)品。詳細(xì)>>
- 快手為什么能殺入萬(wàn)億“俱樂(lè)部”?
-

- 2月4日,快手公布打新情況,中簽的分為兩種人:甲組天選之子和乙組大戶(hù)。詳細(xì)>>
新聞熱榜
- 012020年,順豐和三通一達(dá)的兩種命運(yùn)
- 02快手想折射人間,宿華就必須成為擦鏡子的人
- 03今天蝦米關(guān)停,網(wǎng)易云獨(dú)斗騰訊系,聽(tīng)歌成本...
- 04泡泡瑪特:28個(gè)設(shè)計(jì)師不如1個(gè)好編劇
- 05日本超人氣電壓力鍋,自帶食譜,做菜不好吃...
- 06直播帶貨就是冬蟲(chóng)夏草:頭部直播是網(wǎng)紅,商...
- 07亞馬遜對(duì)「打工人」動(dòng)手:接受10小時(shí)大夜班...
- 08多項(xiàng)世界第一!起源太空兩個(gè)世界級(jí)探測(cè)器成...
- 09張藝謀鏡頭里的科技力量:為世界注入5G之心...
- 10搜狐營(yíng)收利潤(rùn)雙雙正增長(zhǎng) 張朝陽(yáng):重返盈利軌...