

原來鑒黃師的KPI是這樣的
 play
play

歡迎關注“新浪科技”的微信訂閱號:techsina
文/博雯 蕭簫
來源:量子位
夠黃了嗎?
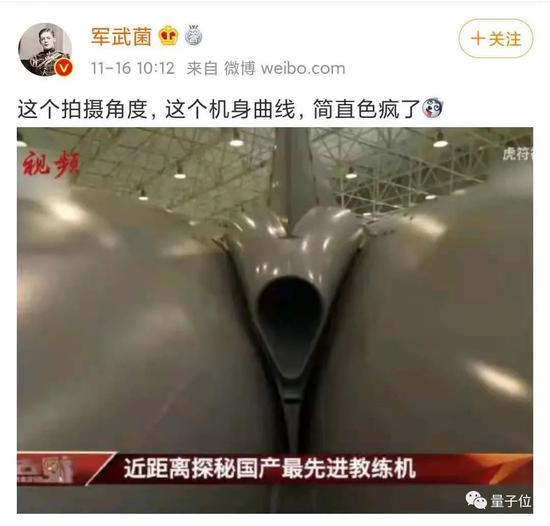
夠黃就能和諧了。
但平臺不為所動,反手夾走了真正身體外露的“正確選項”:
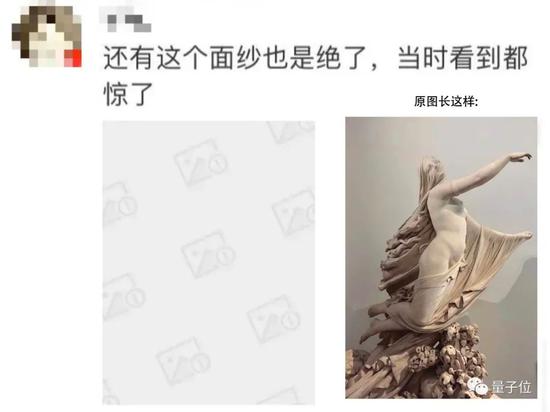
掛圖,實在是門玄學。

可在這個雖自但醫的現代網絡里,誰又能定義什么才是真正的GHS呢?
無法明確定義,后續的鑒定工作就無從開展。
欣賞人體藝術的精神需求,以及教育未成年人的現實需求,如何統一這兩者,就成了一個亟待解決的問題。
為了大家的身心健康,我們有必要來探討一下,如何才能科學有效地鑒黃。

人類鑒黃行不行?
評判一個人類鑒黃師行不行,首先要考慮知識淵博程度。
畢竟對于人類來說,鑒黃是個經驗驅動型工作。
簡單來說,就是要綜合考慮一張圖片中人物皮膚裸露、肢體動作和表情神態等特征,然后以個人經驗來判斷是否涉黃。

雖然鑒定結果難免會受個人喜好個體差異的影響,但總體來說,只有擁有長期高速駕駛的經驗,才能對色情和性感拿捏自如。
好,再來康康鑒黃師們的身體夠不夠結實。
冷知識:我們常說的“鑒黃”,在國內更多是“內容審核”或“內容安全”部門的工作。
所以廣大審核員們每天要面對的不僅是小黃圖,還有互聯網上時刻都在爆炸式增長的各類內容。

有調查顯示,審核員們平均8個小時要看超過600部視頻,聽4000條語音,看上萬張涉黃圖片,處理近10億條不良信息。

高強度、低工資和輪班制更是工作常態:
在這樣的一杯茶一包煙,一萬圖片看一天的996生活下,有人的心態慢慢失衡。

也有人因為長期面對大量低俗、獵奇的垃圾信息,甚至是暴力、血腥的違法內容,而產生了心理陰影。
還有更多或是因為受夠了每天幾千條的黃暴圖片選擇轉行,或是因為長時間的高強度壓抑工作患上了抑郁癥,甚至最終自殺的審核員。
 △紀錄片《網絡審查員》劇照
△紀錄片《網絡審查員》劇照那么對于不堪重負的人類鑒黃師,計算機能來幫幫忙嗎?
當然可以!機器學習算法早在2018年就已經趕來助力了。

那能不能取代人類?
不能。
很遺憾,AI鑒黃在一開始,就遇到了重重困難。
AI鑒黃難在哪?
簡單來說,AI鑒黃的過程是這樣的:
最開始,由算法工程師給AI模型喂入大量已標注性感/色情的圖片。
然后,AI會在圖像數據的特征空間上學習一個決策面,將色情及性感兩類數據劃分開來。
 △分類器完成決策面
△分類器完成決策面完成這種“分類”,也即AI學習一個鑒黃分類函數的過程。
到最后,通過這一分類函數,使AI模型達到輸入一張圖片,就能正確輸出一個“正常/色情”標簽的效果。
聽起來容易,但要讓AI真正學會檢測小黃圖,卻是難上加難。
第一個問題,就是目前沒有行業統一的標準。
雖然可以參考《暫行規定》相關文件中提出的關于淫穢信息的標準,但對于色情內容,不同行業總是有自己的管控標準和接受程度。
比如下面這四張圖,它們在各自的領域可能是人體雕塑的藝術、學前科普的教育、沙雕網友的智慧,以及呃……GHS了,但又沒有完全搞的神奇圖片。

但換個領域,換個平臺,可能就會:

畢竟,有時候人類可能都無法互相理解,AI就更不明白“什么才是真正的黃色了”。
碰到再勇一點的AI,不求準確,直接一個玄學掛圖法就將所有可能一波帶走。

第二個難點,就是現實里樣本含量極少的問題了。
不同于訓練時期的大口喂圖,現實里的色情內容,只是海量網絡信息中極小的一部分。
所以實際上崗工作后,AI更可能面對的是“大海撈黃”的情況。
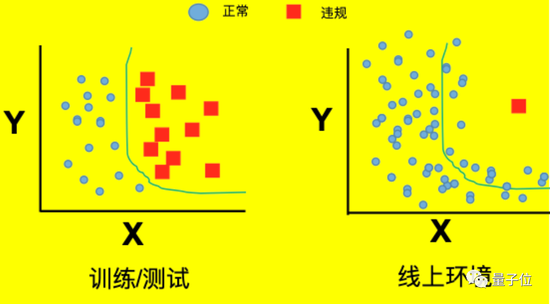
而當AI撈了半天小黃圖出來,等待下一步的優化訓練時,又會出現一個新的問題——
正確率越高,AI鑒黃師就更好嗎?
不!
這種情況下,就算AI算法的正確率達到了99%,它也可能是不合格的鑒黃師!
因為當小黃圖的比例在1%以下時,即使AI在測試中將所有圖片都判斷為“正常”,正確率也能輕松突破99%。
那么這時,AI鑒黃師哪怕完全不會鑒黃,也能達成“高正確率”的目標——
只需要全判斷成“正常圖片”就行!

這可比錯夾了藝術作品嚴重多了。
如何讓AI科學鑒黃?
先來解決最關鍵的問題——
如何讓AI模型應對真實場景中,小黃圖占比少的問題?
當然是給AI“鑒黃師”設個更合理的KPI。
AI“鑒黃師”需要明白,假陽性(正常圖誤判成小黃圖)和假陰性(小黃圖誤判成正常圖),其實是兩種嚴重性不一樣的錯誤!

為此,來自中科院的專家,提出了一種名為局部AUC優化的方法,用2個指標對AI模型進行約束。
AUC(Area Under Curve)全稱曲線下面積,通常這里的曲線指ROC(Receiver Operating Characteristic Curve),即受試者工作特征曲線。
當我們畫一條ROC曲線時,其X軸為真陽性率(True Positive Rate, TPR),而Y軸則為假陽性率(False Positive Rate, FPR),曲線為ROC,被包裹的藍色面積就是AUC。
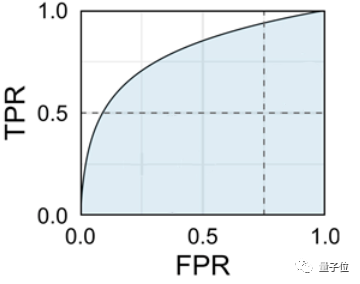
真陽性率:所有真·小黃圖中,被正確判斷成小黃圖的比率;
假陽性率:所有真·正常圖中,被錯誤判斷成小黃圖的比率。
如果AI“鑒黃師”胡亂分類(未經訓練,隨機分類),那么真陽性率和假陽性率基本持平。
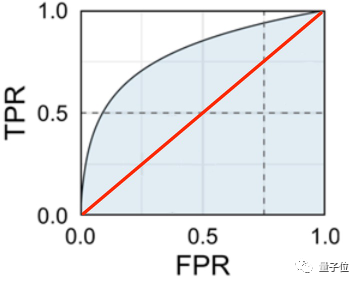
因此,有效的AI“鑒黃師”,真陽性率必須比假陽性率高,(最理想的狀態是真陽性率為1,不出錯),測出來的藍色面積就更大,這也是它的KPI了。
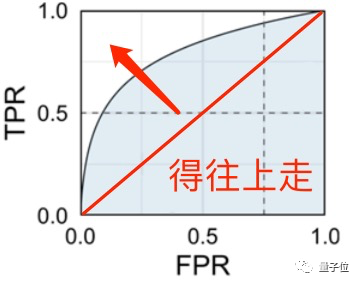
而且為了讓AI“鑒黃師”符合崗位要求,真陽性率(TPR)和假陽性率(FPR)還必須符合一定的閾值,就像下面這樣:
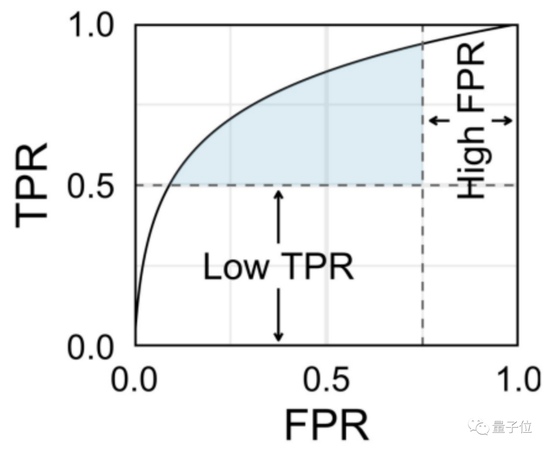
可別小看這個指標,它會讓AI“鑒黃師”專注提升AUC,且不受到標簽分布的影響。
這樣的KPI,如何能讓AI模型靈活handle不同行業的標準?
據團隊介紹,這里的閾值并不是固定的,而同樣會根據各行各業不同的標準,以及對風險召回率的要求和人工審核成本等因素進行調整的,最終實現風險召回和審核成本間的最佳平衡。
針對各行各業不同的認知標準,團隊還會從數據集下手,對模型進行調整。
團隊表示,不同場景下,對于色情風險防控的標準和認知確實有所不同。

為此,團隊在做數據標記時,會用非常詳細的標簽對數據進行描述,也就是細粒度打標。用不同的訓練集訓練后,同一種AI模型,也能適應不同的行業標準了。
除此之外,在做數據標記時,也會有講究。
如果只讓一個人來對數據集進行標記,那么訓練出來的AI模型肯定會帶有個人偏好。為了避免這種情況,就得靠多人多次打標,用統計學對抗偏見。
這樣,訓練出來的AI“鑒黃師”,既能通過不同的訓練集“培養特長”,也能根據合理的“KPI”激勵自己做得更好。
真的減輕人類工作了嗎?
減輕了!
據團隊表示,還是降低了不少工作量的。
首先,AI鑒黃師在看過每張樣本后,會給色情、性感等標簽打個預測分,是更接近小黃圖、還是更接近性感圖。
根據這些分值,機器會自動對結果的可信度進行分層。
如果AI對自己很有自信——給的分數很高,那么直接輸出結論就行。
這種情況下,就不需要人類鑒黃師再看一遍了。
但如果AI覺得水太深,把握不住,就還是交給人類鑒黃師來審核。

為了進一步減輕人類鑒黃師的工作量,AI鑒黃師還會“回看”自己打分低的那些圖片:我到底為什么對它們拿不準?
然后,再對這些圖片進行學習,進一步提升鑒黃水平。
團隊介紹
這篇正經研究,目前已經登上了機器學習頂會ICML 2021,屬于錄用率僅3%的長文成果。

開發出這個指標的團隊成員,分別來自中科院、信息安全國家重點實驗室、深圳鵬城實驗室等研究機構。
一作楊智勇,是中科院信息工程研究所信息安全國家重點實驗室的博士生,目前已在在CCF-A類會議/期刊上發表論文20篇。
目前,這位小哥已經以一作身份,在TPAMI、ICML、NeurIPS、TIP、AAAI等頂會上發表過論文,其中ICML中的還是oral。

二作許倩倩,是中國科學院計算技術研究所副研究員。

當然,除了鑒黃以外,這個指標還能被用在更多的AI安全模型上。
據研究團隊表示,除了鑒黃以外,這個指標也能應用到更多的安全場景中,包括過濾違規信息(例如詐騙廣告)。


(聲明:本文僅代表作者觀點,不代表新浪網立場。)

作者簡介




