

CNN+Transformer=SOTA!CNN丟掉的全局信息,Transformer來補(bǔ)
來源:新智元
在計算機(jī)視覺技術(shù)發(fā)展中,最重要的模型當(dāng)屬卷積神經(jīng)網(wǎng)絡(luò)(CNN),它是其他復(fù)雜模型的基礎(chǔ)。
CNN具備三個重要的特性:一定程度的旋轉(zhuǎn)、縮放不變性;共享權(quán)值和局部感受野;層次化的結(jié)構(gòu),捕捉到的特征從細(xì)節(jié)到整體。

這些特性使得CNN非常適合計算機(jī)視覺任務(wù),也使CNN成為深度學(xué)習(xí)時代計算機(jī)視覺領(lǐng)域的基石,但CNN的細(xì)節(jié)捕捉能力使它的全局建模能力較弱。
所以如何使CV模型捕獲全局特征逐漸成為研究熱點(diǎn)。
NLP的模型能解決CV問題?
2017年,Transformer橫空出世,Attention is all you need!隨后BERT類模型在各大NLP排行榜屠殺,不斷逼近、超過人類的表現(xiàn)。
2020年Google Brain研究員提出的Vision Transformer(ViT)以最小的改動將Transformer應(yīng)用于用CV領(lǐng)域。
Transformer的動態(tài)注意力機(jī)制、全局建模能力使得ViT在通過超大規(guī)模預(yù)訓(xùn)練后,表現(xiàn)出了很強(qiáng)的特征學(xué)習(xí)能力。
然而,ViT在設(shè)計上是沒有充分利用視覺信號的空間信息,ViT仍然需要借助Transformer中的Position Embedding來彌補(bǔ)空間信息的損失。
視覺信號具有很強(qiáng)的2D結(jié)構(gòu)信息,并且與局部特征具有很強(qiáng)的相關(guān)性,這些先驗知識在ViT的設(shè)計中都沒有被利用上。
CNN的設(shè)計又可以很好地彌補(bǔ)ViT設(shè)計中的這些不足,或者也可以說,ViT的設(shè)計彌補(bǔ)了CNN全局建模能力較弱的問題。
這篇論文提出一種全新的基礎(chǔ)網(wǎng)絡(luò)Convolutional vision Transformers (CvT),既具備Transforms的動態(tài)注意力機(jī)制、全局建模能力,又具備CNN的局部捕捉能力,同時結(jié)合局部和全局的建模能力。

CvT是一種層級設(shè)計結(jié)構(gòu),在每一層級,2D的圖像或Tokens通過Convolutional Embedding生成或更新特征向量。
每一層包括N個典型的Convolutional Transformer Block,把線性變換替換成卷積變換輸入到多頭attention機(jī)制,再進(jìn)行Layer Norm。
Convolutional Projecton使得CvT網(wǎng)絡(luò)可以維持圖像信號的空間結(jié)構(gòu)信息,也使得Tokens更好的利用了圖像信息的局部信息相關(guān)性,同時也利用了注意力機(jī)制對全局信息進(jìn)行建模。
而卷積操作的靈活性,使得我們可以通過設(shè)置卷積操作的步長來對key,value進(jìn)行降采樣,從而進(jìn)一步提升Transformer結(jié)構(gòu)的計算效率。
Convolutional Embedding和Convolutional Projection充分利用了視覺信號的空間特性,所以在CvT的結(jié)構(gòu)中,空間信息不需要引入position embedding,使得CvT更靈活的應(yīng)用于計算機(jī)視覺中各類下游任務(wù),如物體檢測,語義分割等。
性能表現(xiàn)
CvT與同時期的其他Transformer-based工作相比,在同等模型大小下在ImageNet1k上取得了明顯優(yōu)于其他模型的準(zhǔn)確率。
此外,CvT在大規(guī)模數(shù)據(jù)集ImageNet22k的預(yù)訓(xùn)練上也取得了不錯的性能,CvT-W24以更少的參數(shù)量,在ImageNet-1k 基準(zhǔn)測試集上獲得了87.7%的Top-1準(zhǔn)確率,超越在同樣規(guī)模數(shù)據(jù)集訓(xùn)練的ViT-H/L模型。
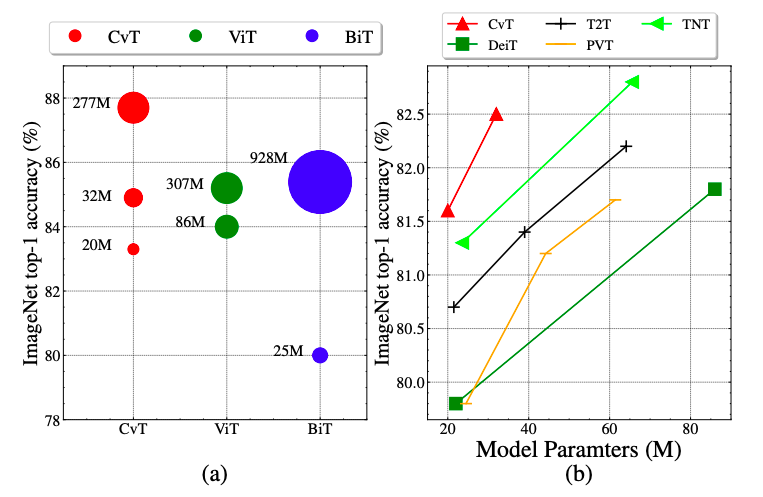
CvT 和SOTA模型模型在Image net, ImageNet Real和ImageNet V2這些數(shù)據(jù)集上性能的比較。同等規(guī)模和計算量情況下, CvT的效率優(yōu)于ResNet和ViT,甚至同時期的其它Transformer-based的工作。
通過網(wǎng)絡(luò)結(jié)構(gòu)搜索技術(shù),對CvT的模型結(jié)構(gòu)像每層Convolutional Projection中的步長和每層MLP的expansion ratio進(jìn)行有效的搜索后,最優(yōu)的模型CvT-13-NAS。以18M的模型參數(shù)量, 4.1G的FLOPs在ImageNet1k上取得了82.2的結(jié)果。

CvT 和Google的BiT,ViT在下游任務(wù)中的遷移能力,CvT-W24以更少的模型參數(shù)量在ImageNet1k上取得了87.7的結(jié)果,明顯優(yōu)于Google的BiT-152x4和ViT-H/16,進(jìn)一步驗證了CvT模型優(yōu)異的性能。

CvT是一種結(jié)合了CNN結(jié)構(gòu)和Transformers結(jié)構(gòu)各自優(yōu)勢的全新基礎(chǔ)網(wǎng)絡(luò),實(shí)驗結(jié)果也驗證了CvT在ImageNet以及各種分類任務(wù)中的有效性。可以展望,這種融合的網(wǎng)絡(luò)勢必會對視覺其他的任務(wù)性能提高進(jìn)一步影響。
參考資料:
https://arxiv.org/pdf/2103.15808.pdf

(聲明:本文僅代表作者觀點(diǎn),不代表新浪網(wǎng)立場。)

作者簡介
作者文章
推薦閱讀
- 低估了傳統(tǒng)汽車供應(yīng)鏈封閉性?華為“Tier 1”夢難做
-

- 我們絲毫不懷疑華為在智能駕駛領(lǐng)域的實(shí)力。 可我們懷疑華為嚴(yán)重低估了傳統(tǒng)汽車供應(yīng)鏈的封閉性。詳細(xì)>>
- 布局6年,字節(jié)金融悄然成型
-

- 字節(jié)金融已覆蓋支付、借貸、證券、保險等全場景。詳細(xì)>>
- 百度知道,風(fēng)光不再?
-

- 知道止于答案,知乎始于答案。詳細(xì)>>
- 抖音能點(diǎn)餐,美團(tuán)怕不怕?
-

- 字節(jié)跳動一直堅持“大力出奇跡”的運(yùn)營傳統(tǒng),固然在線上勝多敗少,但到了線上線下的結(jié)合部,大力能否持續(xù)出奇跡,還需要更多的案例進(jìn)行驗證。詳細(xì)>>