

內存256KB設備也能人臉檢測,微軟提出用RNN代替CNN | NeurIPS 2020
來源:量子位
蕾師師 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
為了讓更多IoT設備用上AI,在條件“簡陋”的單片機上跑圖像識別模型也成為一種需求。
但是圖像識別對內存有較高的要求,一般搭載MCU的設備內存都不高,怎樣才能解決這個問題呢?
最近,微軟提出了一種RNNPool方法,甚至可在內存只有256 KB的STM32開發板上運行人臉檢測模型。

這篇論文也發表在近期舉行的頂會NeurIPS2020上,相關代碼已經開源。
CNN難以適應單片機低內存
目前,計算機視覺領域的主要架構都是基于CNN,但是CNN對處理器的內存要求比較高,所以對于微型處理器,更加不友好。
CNN主要分成兩個部分,一是卷積層,用來提取被輸入圖像的視覺特征。二是池化層,用來組合特征,并且簡單表達出來。
但這樣的結構真的非常消耗內存,假如我們輸入一張56×56的8位圖像,在處理的過程中,至少需要800KB的內存。
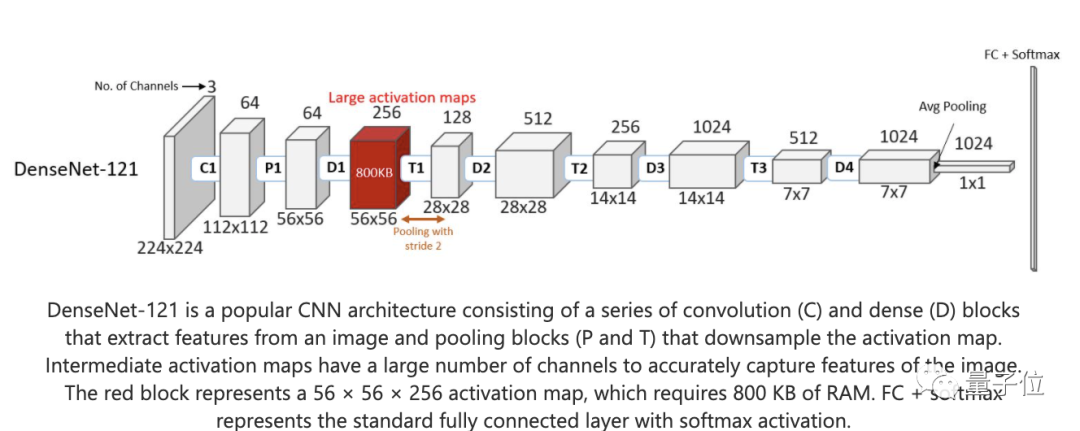
邊緣AI往往內存和功耗都有限,大多數Arm Cortex-M4微控制器設備的內存都少于256 KB。
顯然,CNN方法應用在這類邊緣設備上是不現實的。
雖然壓縮激活圖的大小可以減少輸出通道的數量,但這可能會導致精度大大降低。
另一種方法是對圖的行/列數量進行下采樣。
假設是一個28×28×256的激活圖取代56×56×256激活圖。那么,一個圖像就可以壓縮到200 KB內。
池化算子和帶狀卷積是下采樣激活圖的標準方法,但這個方法依賴于相對簡單和有損的聚合。若將其應用于較大的接收域,或者圖像模塊進行更激進的下采樣,則可能會導致其精度降低。
因此,如上圖中所示,在大多數標準CNN架構中,這種運算符僅限于在2×2的接收域才能保證它的準確度。
而且這種方法只將激活圖大小減少了四倍,滿足不了我們的要求。
因此,我們需要找到一個池化算子,它既可以總結激活圖的大模塊,并可以一次性降低激活圖的大小。
這種方法就叫做RNNPool。
RNNPool所需內存減少80~90%
RNNPool在語法上等效于池化算子,可以快速減小中間圖的大小。它的模型層數更少,對內存要求更低,可以在內存受限的小型設備上分析圖像。
RNNPool由兩個學習遞歸神經網絡(RNN)組成,它們以每個模塊為單個向量,在水平和垂直方向上掃過激活圖的每個模塊。
RNNPool獲取一個激活圖的模塊并將其匯總為1×1體素,然后逐步執行下采樣步驟。RNNPool可以支持8×8,甚至16×16的模塊大小,并且可以以步長s = 4或s = 8采樣,而不會顯著降低精度。

第一個RNN遍歷每一行和每一列,并將它們全部匯總為h1維的1×1體素,第二個RNN雙向遍歷這些體素,并且生成一個最終的1×4×h2向量。其中,h1是第一遍RNN隱藏狀態的大小,其中h2是第二個RNN隱藏狀態的大小。
因此,它可以在不損失準確度的情況下大幅降低激活圖的采樣率。

由于RNNPool與池化算子等價,所以它可用于替換CNN中的所有池化運算符,降低對內存需求。
將RNNPool放在CNN架構的開頭,可以快速采樣激活圖,降低峰值內存需求。
在大多數情況下,研究人員發現基于RNNPool的模型所需的內存可以減少至原來的10~20%。同時,仍能保持幾乎相同的準確度。
實驗測試結果
研究人員將基于RNNPool的人臉檢測模型(稱為RNNPool-Face-M4)在一個叫做SeeDot的工具上編譯。
RNNPool-Face-M4用在Arm Cortex-M4微控制器的STM32F439-M4器件上,通過測試,它能在10.45秒內處理單個圖像,它的峰值內存僅需要188 KB。
再通過跟EagleEye(小型設備領域的SOTA技術)比較,可以看到,RNNPool-Face-Quant在內存消耗上的225KB明顯明顯優于EagleEye的1.17MB。

Demo
微軟團隊還基于RNNPool制作了兩個圖像任務Demo。
其中一個是臉部識別。
在訓練時,根據參數不同,輸入圖像將為640x640的RGB圖,或者為320x320的的單色圖。
在測試時,主要運用了兩種模式。一是為一組樣本圖像生成邊界框的評估模式,二是計算諸如mAP分數之類的測試模式。
測試方法一是將圖像保存在特定的文件夾中,并在具有高置信度的臉部周圍標志上邊框。如下圖所示:

測試方法二對于每個圖像,都提供了單獨的預測文件,文件中的每一行都對應一個標識框。對于每個框,將生成五個數字:框的長度,框的高度,x軸偏移,y軸偏移,存在臉部的置信度值。
除了面部識別的程序代碼外,他們還貼出了一個Visual_Wakeword的代碼庫,這是一個二元的識別程序,即判斷圖像里面,是否有人的出現。
官方介紹:
https://www.microsoft.com/en-us/research/blog/seeing-on-tiny-battery-powered-microcontrollers-with-rnnpool/
論文地址:
https://www.microsoft.com/en-us/research/publication/rnnpool-efficient-non-linear-pooling-for-ram-constrained-inference/
開源代碼:
https://github.com/microsoft/EdgeML/blob/master/pytorch/edgeml_pytorch/graph/rnnpool.py
https://github.com/microsoft/EdgeML/tree/master/examples/pytorch/vision

(聲明:本文僅代表作者觀點,不代表新浪網立場。)

作者簡介
作者文章
推薦閱讀
- 華為“造車”背后的陽謀
-

- 華為造車有句名言:華為不造車,但我們聚焦ICT技術,幫助車企造好車。詳細>>
- 共享辦公沒做錯什么,為何仍以失敗告終?
-

- 兩三年前,創業者青睞共享辦公,很大的原因在于租一個工位可以享受咖啡區、多形式休閑討論區、會議室等多個公共區域,但現在這些似乎將不復存在。詳細>>
- 警惕以“效率”為名的無限掠奪
-

- 社區團購輿論戰硝煙彌漫,不少人以擁護自由市場的姿態紛紛站出來,為美團優選等辯護,他們邏輯是:社區團購本質上是提高生鮮等零售流通的效率,這是電商創新,我們不能因噎廢食。詳細>>
- 被資本收割前,不妨多薅一把社區團購羊毛
-

- 當資本和媒體都在關注社區團購這條賽道時,那些真正的用戶和“團長”們卻并不在乎這些。詳細>>