

NeurlPS2020| 訓練數據嚴重不足,我的GAN也不會涼涼了!
來源:新智元
我們大家都知道,訓練GAN需要大量的數據,可多達100,000張圖。
近日,Nivida的研究人員研發出了一種被稱為自適應鑒別器增強(ADA, Adaptive Discriminator Augmentation)的方法,直接將訓練數據量減少10到20倍,此研究成果已經被發布在《用有限數據訓練生成對抗網絡(Training Generative Adversarial Networks with Limited Data》這篇論文中,該論文也將參加今年的NeurlPS2020會議。

論文中表示:「使用小型數據集的關鍵問題在于,判別器在訓練樣本上出現了過擬合,從而向生成器中傳遞的反饋開始失去意義,訓練情況也逐漸開始變得一致。」
為了證明實驗結果解決了這一技術難題,研究人員展示了在幾個數據集上,僅僅使用幾千個圖像,就可以得到可觀的結果,并且在通常情況下,可以將StyleGAN2的結果與數量很少的圖像相匹配。」
借鑒bCR方法,增強判別器泛化能力
該論文使用的方法借鑒了bCR的處理過程,什么是bCR呢?
從定義上來說,任何應用到訓練數據集的增強效果都會被生成的圖像繼承。Zhao 等人在CoRR2020上發表的《GAN的改善一致正則化(Improved consistency regularization for GANs》中的平衡一致正則化(balanced Consistency Regularization, bCR)就是針對此問題的一個解決方案。
一致正則化主要表明,使用在相同輸入圖像中的兩組增強,應該產生相同的輸出。Zhao等人將一致正則化條件添加到判別器損失中,并將判別器一致性強制使用在真實圖像和生成圖像中,而訓練生成器的時候則不使用增強操作和一致性損失操作。
如此,bCR這一方法通過令判別器對在一致正則化(CR)條件下的增強效果視而不見,從而有效地對判別器進行了泛化。
該論文的方法和bCR相似,都對展示給判別器的所有圖像做了一系列增強操作,而和bCR不同的是,該篇論文并沒有添加分離CR損失,而只使用了增強過的圖像,并在訓練生成器的過程中也做了此操作。此方法被研究人員稱為隨機判別器增強(Stochastic Discriminator Augmentation)。
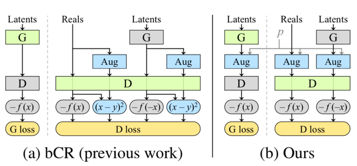
兩種方法的比較:左:bCR,右:Stochastic Discriminator Augmentation
下圖展示了研究人員對每張判別器處理的圖像進行一系列增強操作的結果,其中,此過程由增強概率p控制:

bCR方法在有效泛化判別器的同時,也導致了泄漏增強效果的后果,因為生成器可以自由生成包含增強結果的圖像,卻沒有收到任何懲罰。
在Nivida最新論文中,研究者通過實驗發現,只要p小于0.8,增強效果的泄漏就不可能在實際操作中出現,從而通過p的調整,有效解決了bCR出現的問題。
下圖展示了使用有限訓練數據,在ADA的操作下,在不同數據集下的生成圖像結果:

此外,今年早些時候,來自來自Adobe Research,麻省理工學院和清華大學的研究人員詳細介紹了DiffAugment,這是GAN增強的另一種方法。
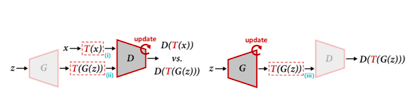
DiffAugment模型概括
降低數據量限制,或將在醫學成像中大有應用
Nvidia圖形研究副總裁David Luebke表示,任何在實踐過程中使用過實際數據科學工具的人都知道,絕大多數時間都被花費在收集和整理數據上,這個過程有時候被稱為ETL管道(ETL pipeline):提取(extract),轉換(transform)和加載(load)。
僅此一項,就需要大量的真實數據,因此,自適應鑒別器增強(ADA)方法的出現為使用者提供了巨大的幫助,因為不需要那么多的數據,就可以獲得有用的結果。
他表示,在和沒有太多空余時間的注釋人員一起工作的時候,這個成果將會起著更重要的作用。
此論文的作者認為,減少數據的限制,可以讓研究人員能夠發掘出GAN的更多用例。除了偽造人或者動物的照片之外,研究人員認為GAN可能會在醫學成像數據中得到廣泛的應用。

「如果有一位專門研究特定疾病的放射科醫生,讓他們坐下來并為50,000張圖像進行注釋的事情很可能不會發生,但是,如果讓他們為1,000張圖像進行注釋,似乎很有可能。
這項研究成果,的確改變了實際的數據科學家在整理數據的時候所需要付出的努力,而這會令探索新的應用變得容易很多。」Luebke說。
相關突破頗多,Yoshua Bengio新作同期亮相NeurlPS2020
《用有限數據訓練生成對抗網絡(Training Generative Adversarial Networks with Limited Data》并非是NeurlPS2020中唯一一篇與GAN有關的論文。
MILA 魁北克人工智能研究所(MILA Quebec Artificial Intelligence Institute)和Google Brain的研究人員(其中包括蒙特利爾Google Brain小組組長兼NeurlPS會議主席Yoshua Bengio和Hugo Larochelle),就發表了另外一篇判別器驅動的潛在采樣方法(Discriminator Driven Latent Sampling, DDLS),該方法的結果顯示,當使用CIFAR-10數據集進行評估時,它可以提高現成GAN的性能。

最后附上ADA方法的論文傳送站,感興趣的朋友可以自行探索實現細節:
https://proceedings.neurips.cc/paper/2020/hash/8d30aa96e72440759f74bd2306c1fa3d-Abstract.html
參考鏈接:
https://venturebeat.com/2020/12/07/nvidia-researchers-devise-method-for-training-gans-with-less-data/

(聲明:本文僅代表作者觀點,不代表新浪網立場。)

作者簡介
作者文章
推薦閱讀
- 《賽博朋克2077》:預謀已久的狂歡 蓄勢欲動的風潮
-

- 詳細>>
- 揭秘戀愛“殺豬盤”:聊天2個月,被騙40萬
-

- 那些本想偶遇愛情的人,被騙子引誘至一場感情和金錢雙失的危險圈套。詳細>>
- 在線音樂巨頭沉浮史:誰能撼動騰訊音樂江山?
-

- 近期蝦米音樂傳言將被關停停,這是否意味著中國在線音樂市場終局將至?詳細>>
- 獸樓處:二十歲的眼淚
-

- 不知道蛋殼這場商業賭博的推手們,會付出什么代價。詳細>>