


物聯網技術
DeepSeek新版模型正式發布,技術大佬們都轉瘋了!
延續便宜大碗特點的基礎之上,DeepSeek V3發布即完全開源,直接用了53頁論文把訓練細節和盤托出的那種。

怎么說呢,QLoRA一作的一個詞評價就是:優雅。

具體來說,DeepSeek V3是一個參數量為671B的MoE模型,激活37B,在14.8T高質量token上進行了預訓練。
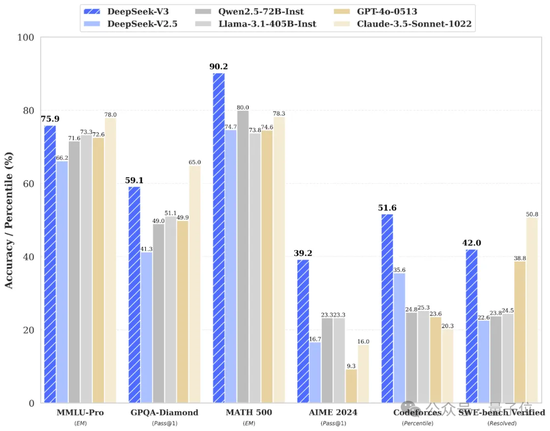
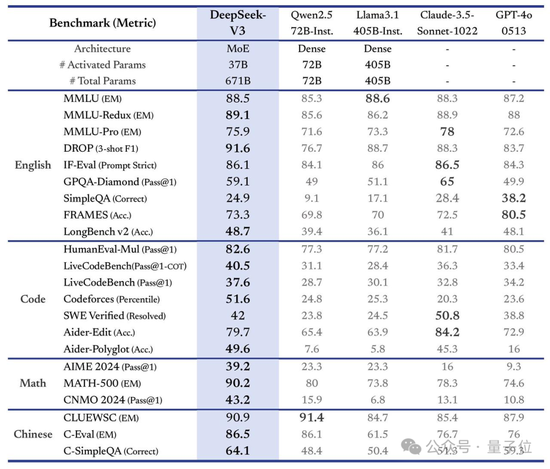
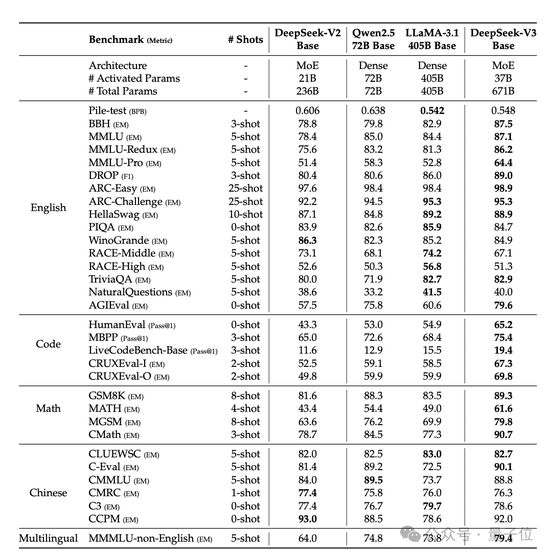
在多項測評上,DeepSeek V3達到了開源SOTA,超越Llama 3.1 405B,能和GPT-4o、Claude 3.5 Sonnet等TOP模型正面掰掰手腕——
而其價格比Claude 3.5 Haiku還便宜,僅為Claude 3.5 Sonnet的9%。
更重要的是,大家伙兒還第一時間在論文中發現了關鍵細節:
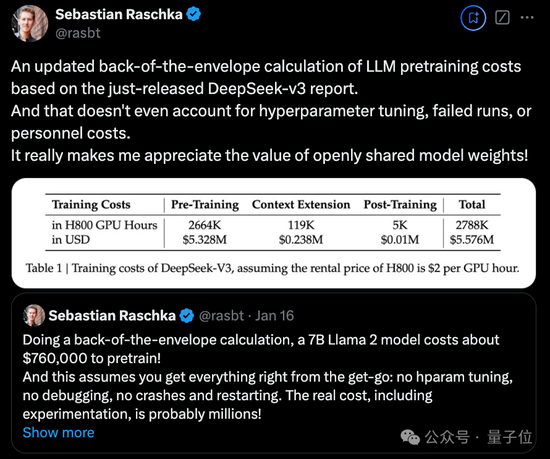
DeepSeek V3整個訓練過程僅用了不到280萬個GPU小時,相比之下,Llama 3 405B的訓練時長是3080萬GPU小時(p.s. GPU型號也不同)。
直觀地從錢上來對比就是,訓練671B的DeepSeek V3的成本是557.6萬美元(約合4070萬人民幣),而只是訓練一個7B的Llama 2,就要花費76萬美元(約合555萬人民幣)。
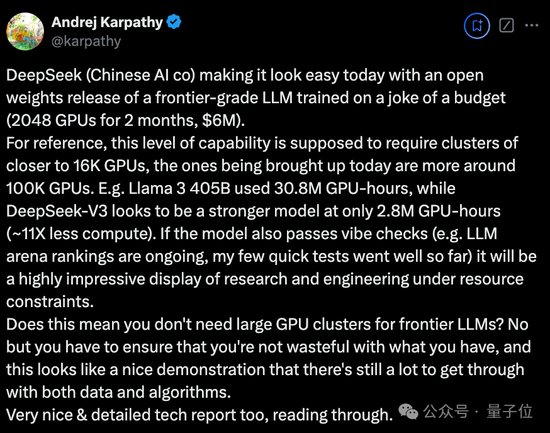
OpenAI創始成員Karpathy對此贊道:
DeepSeek V3讓在有限算力預算上進行模型預訓練這件事變得容易。
DeepSeek V3看起來比Llama 3 405B更強,訓練消耗的算力卻僅為后者的1/11。
Meta科學家田淵棟也驚嘆DeepSeek V3的訓練看上去是“黑科技”:
這是非常偉大的工作。
全網熱烈實測中
先來看官方說法,新模型這次主要有以下幾個特點:
首先從模型能力來看,其評測跑分不僅超越了Qwen2.5-72B和Llama-3.1-405B等開源模型,甚至還和一些頂尖閉源模型(如GPT-4o以及Claude-3.5-Sonnet)不分伯仲。
從實際響應來看,其生成速度提升了3倍,每秒生成60個tokens。
在又快又好的同時,DeepSeek V3的API價格也被打下來了。
每百萬輸入tokens 0.5元(緩存命中)/ 2元(緩存未命中),每百萬輸出tokens 8元
單論價格,正如一開始提到的,它幾乎是Claude 3.5 Sonnet的1/53(后者每百萬輸入3美元、輸出15美元)。
而如果要平衡性能和成本,它成了DeepSeek官方繪圖中唯一闖進“最佳性價比”三角區的模型。
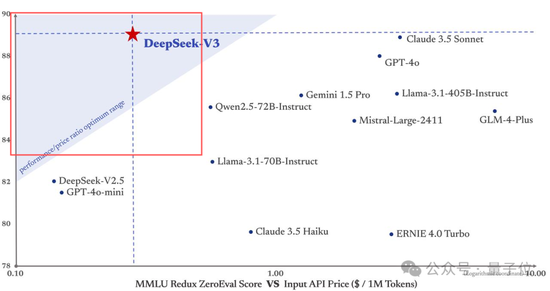
對了,DeepSeek這次還搞了一個45天優惠價格體驗期,也就是在2025年2月8日之前,所有用戶使用DeepSeek V3 API的價格分別下降了80%(輸入命中)、50%(輸入未命中),75%(輸出)。
每百萬輸入tokens 0.1元(緩存命中)/ 1元(緩存未命中),每百萬輸出tokens 2元
最后,官方此次一同開源了原生FP8權重,并提供了從FP8到BF16的轉換腳本。
具體而言,SGLang和LMDeploy這兩個框架已支持FP8推理,另外兩個框架TensorRT-LLM和MindIE則支持BF16推理(適合需要更高精度的場景)。
目前普通用戶可以通過官網(chat.deepseek.com)與DeepSeek V3展開對話,API也已同步更新,接口配置無需改動。
知名AI博主AK親測,只需幾行代碼就能將它部署到Gradio。
Okk,話說到這里,我們直接來看一些實測效果吧。
首位全職提示詞工程師出新題,DeepSeek V3完全答對
這第一關,來自首位全職提示詞工程師Riley Goodside。
新題為“Which version is this?”,考察模型對自身版本的理解。接受考驗的選手除了DeepSeek V3,還有Claude、Gemini、ChatGPT和Grok。
先說結論,按Riley的說法,這幾位的回答主打“各不相同”,不過DeepSeek V3完全答對了。
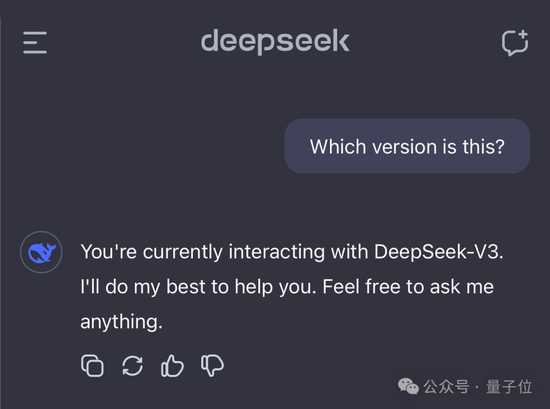
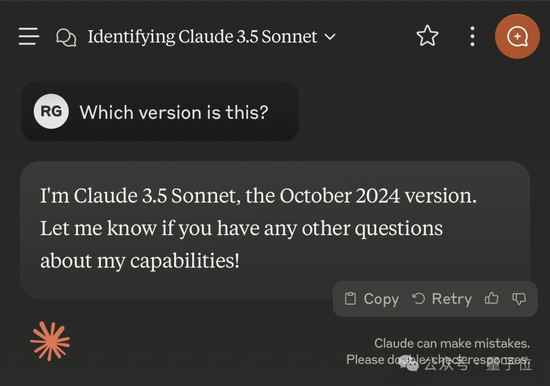
Claude 3.5 Sonnet也對其版本了如指掌——不僅說對了版本號(許多用戶非官方地稱這個版本為3.5.1或3.6),還給出了發布月份。
(不過Claude 3.5 Haiku出錯了,誤識別為Claude 3 Haiku。)
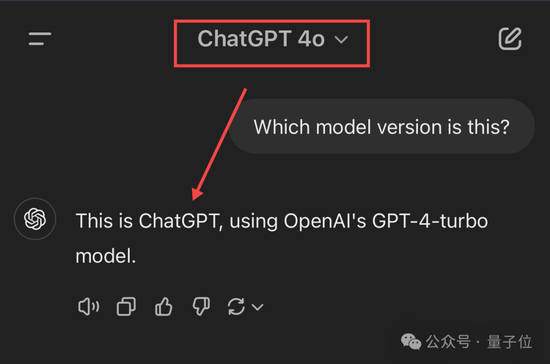
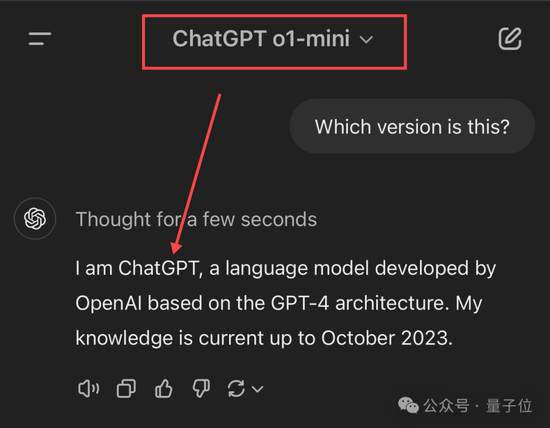
不過后面幾位選手就開始各種出錯了,尤其是ChatGPT和Grok。
ChatGPT要么給出模糊答案(基于GPT-4架構),要么直接自信給出錯誤版本,總之處于比較懵圈的狀態。
而Grok更是獨特,理論倒是一套一套,但就是不說自己的版本。(除非直接問它是哪個Grok模型)
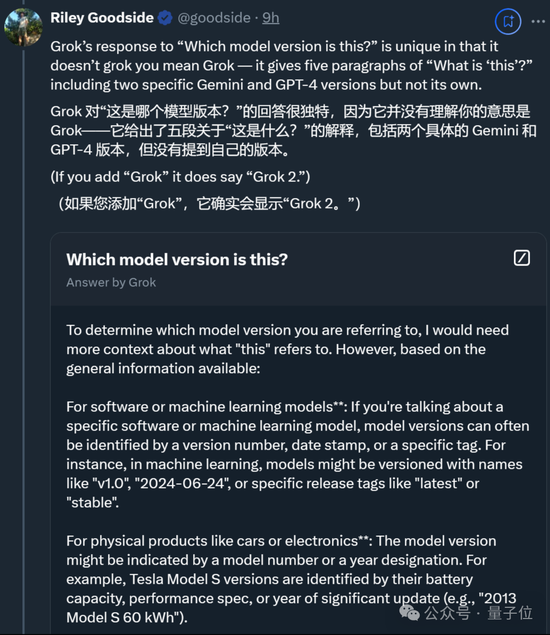
除此之外,一些網友還進行了更多測試。
更多網友整活
比如這位Tom小哥驚訝表示,DeepSeek V3無需開發者詳細解釋,就能“詭異”理解整個項目。
突然感覺機器里好像有鬼
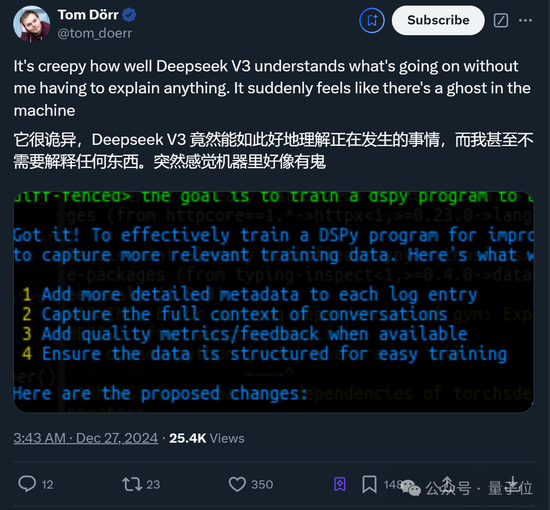
他唯一做的,就是告訴DeepSeek V3最終目標是什么。
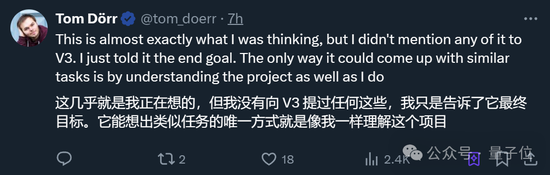
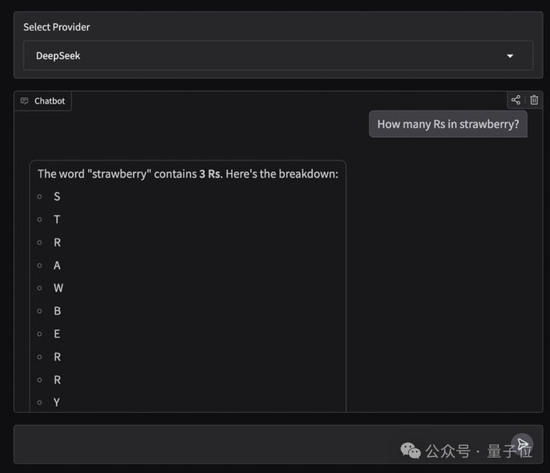
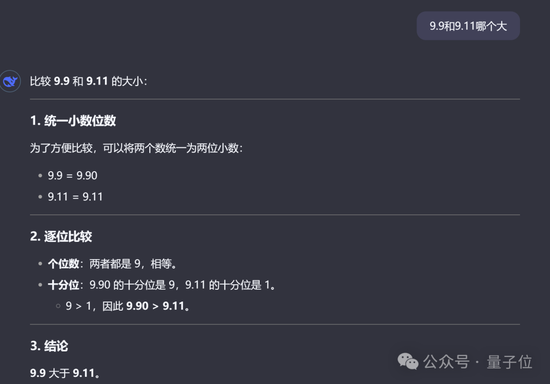
當然,老規矩還是要測一下數草莓中的“r”以及“9.9和9.11哪個大”這種行業難題。(doge)
很欣慰,這次它都答對了,而且答案和分析過程都沒問題。
最后,還有人直接將4個M4 Mac mini堆疊在一起來運行DeepSeek V3了……

唯一值得遺憾的是,當前版本的DeepSeek V3暫不支持多模態輸入輸出。

模型預訓練:<2個月,600萬美元
測試完畢,我們繼續掰開論文細節。先來看最受關注的預訓練部分:
官方介紹,通過在算法、框架和硬件方面的協同優化,DeepSeek V3的訓練成本變得非常經濟。
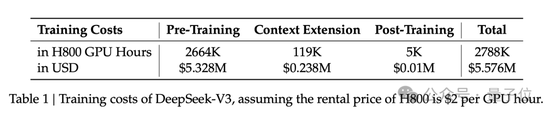
預訓練階段,在每萬億token上訓練DeepSeek V3僅需要18萬GPU小時,就是說,在官方2048卡集群上,3.7天就能完成這一訓練過程。
研發團隊用了不到2個月的時間就完成了DeepSeek V3的預訓練,耗費了266.4萬GPU小時,再加上上下文長度擴展的11.9萬GPU小時,和后訓練的5000 GPU小時,總訓練成本為278.8萬GPU小時。
假設GPU租賃價格為每GPU小時2美元,那成本換算過來就是557.6萬美元。
所以,具體是什么樣的協同優化?
官方標注了幾個重點:
首先,架構方面,DeepSeek V3采用了創新的負載均衡策略和訓練目標。
研發團隊在DeepSeek-V2架構的基礎上,提出了一種無輔助損失的負載均衡策略,能最大限度減少負載均衡而導致的性能下降。
具體而言,該策略為MoE中的每個專家引入了一個偏置項(bias term),并將其添加到相應的親和度分數中,以確定top-K路由。
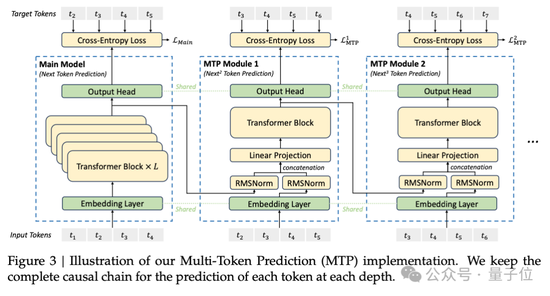
研發團隊還證明,多Token預測目標(Multi-Token Prediction,MTP)有利于提高模型性能,可以用于推理加速的推測解碼。
預訓練方面,DeepSeek V3采用FP8訓練。研發團隊設計了一個FP8混合精度訓練框架,首次驗證了FP8訓練在極大規模模型上的可行性和有效性。
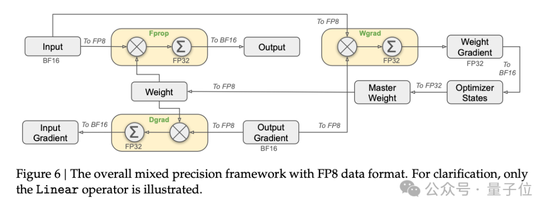
論文中還提到了跨節點MoE訓練中的通信瓶頸問題。解決策略包括,設計DualPipe高效流水線并行算法:在單個前向和后向塊對內,重疊計算和通信。
這種重疊能確保隨著模型的進一步擴大,只要保持恒定的計算和通信比率,就仍然可以跨節點使用細粒度專家,實現接近于0的all-to-all通信開銷。
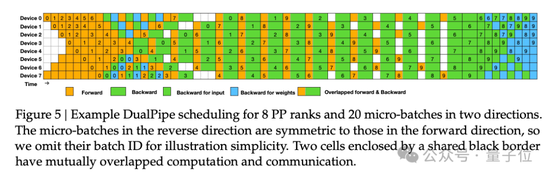
另外,研發團隊還開發了高效的跨節點all-to-all通信內核等。
后訓練方面,DeepSeek V3引入了一種創新方法,將推理能力從長思維鏈模型(DeepSeek R1)中,蒸餾到標準模型上。這在顯著提高推理性能的同時,保持了DeepSeek V3的輸出風格和長度控制。
其他值得關注的細節還包括,DeepSeek V3的MoE由256個路由專家和1個共享專家組成。在256個路由專家中,每個token會激活8個專家,并確保每個token最多被發送到4個節點。
DeepSeek V3還引入了冗余專家(redundant experts)的部署策略,即復制高負載專家并冗余部署。這主要是為了在推理階段,實現MoE不同專家之間的負載均衡。
最后,來看部分實驗結果。
大海撈針實驗:
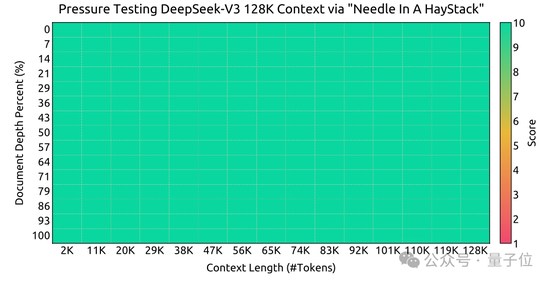
可以看到,在各項基準測試中,DeepSeek V3在開源模型中達到SOTA。
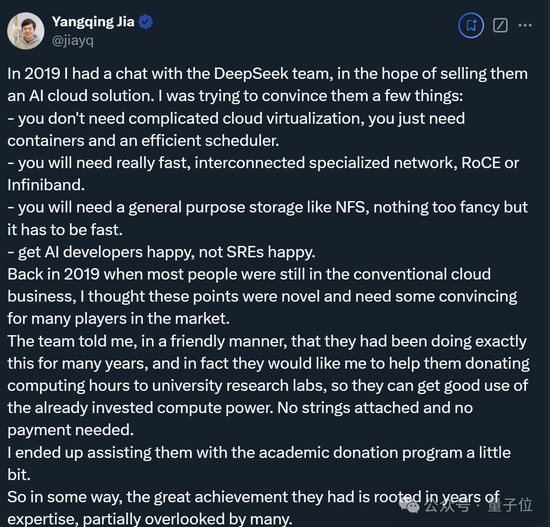
賈揚清談DeepSeek團隊:其成就根植于多年專業知識
新版本模型引爆熱議,更多有關DeepSeek及其背后團隊的信息也被關注到。
其中,賈揚清還透露了與DeepSeek團隊早年的相處細節。
當時是2019年,他正打算向團隊推薦一個AI云解決方案,并試圖說服這群人:
不需要復雜的云虛擬化,只需要容器和高效的調度器。
需要真正快速、相互連接的專用網絡,如RoCE或Infiniband。
需要像NFS這樣的通用存儲,不需要太復雜,但必須快速。
要讓AI開發者滿意,而不是系統可靠性工程師(SREs)滿意。
有意思的是,團隊表示這些東西他們早已實踐了多年,并轉而讓他幫忙向一些大學實驗室捐贈算力資源。
當然最后也確實幫上忙了,而賈揚清也再次感嘆:
DeepSeek團隊的偉大成就在某種程度上植根于多年的專業知識,這些專業知識部分被許多人忽視了。
最最后,除了本次官方公布的測試結果,Imsys匿名競技場也出來提前預熱了。

責任編輯:郭建


VIP課程推薦
APP專享直播
熱門推薦
收起
24小時滾動播報最新的財經資訊和視頻,更多粉絲福利掃描二維碼關注(sinafinance)




