

被OpenAI CEO取關后,Yann LeCun再次抨擊:ChatGPT對現實的把握非常膚淺
機器之心報道
編輯:蛋醬、杜偉
盡管 Yann LeCun 或者一部分學者對 ChatGPT 的評價不高,但其商業化的成功仍是不可阻擋的。
大佬之間的關系,有時真是撲朔迷離。
昨天,有人發現,OpenAI CEO Sam Altman 已經在推特上取關了 Meta 首席人工智能科學家 Yann LeCun。
我們很難確定這次取關發生的具體時間點,但基本能夠確定事件原因 —— 幾天前,Yann LeCun 在前段時間的一次小型媒體和高管在線聚會上發表了自己對 ChatGPT 的看法:
‘就底層技術而言,ChatGPT 并沒有什么特別的創新,也不是什么革命性的東西。許多研究實驗室正在使用同樣的技術,開展同樣的工作。’
在 ZDNet 的‘ChatGPT is ‘not particularly innovative,’ and ‘nothing revolutionary’, says Meta‘s chief AI scientist’報道中,LeCun 演講的一些細節被披露出來。其中有一些很驚人的評價:
-
‘與其他實驗室相比,OpenAI 并沒有什么特別的進步。’
-
‘ChatGPT 使用的 Transformer 架構是以這種自監督的方式預訓練的。自監督學習是我很長一段時間以來一直倡導的,甚至可以追溯到 OpenAI 出現之前。’
-
‘Transformer 是谷歌的發明,這類語言項目的工作可以追溯到幾十年前。’
-
……
如此,Sam Altman 的取關行動也是情有可原。
在‘取關’被人發現的四個小時后,Yann LeCun 更新了動態,再次轉發了一篇‘陰陽’ChatGPT 的文章:
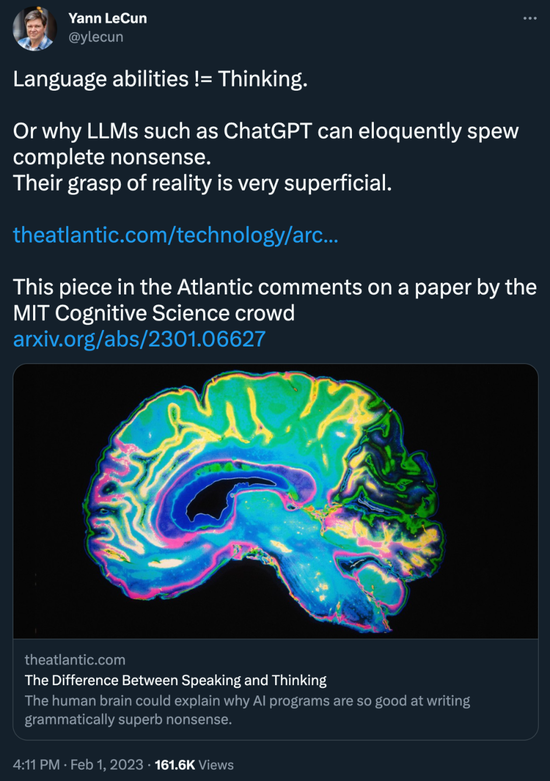
為什么像 ChatGPT 這樣的大型語言模型可以滔滔不絕地胡說八道?它們對現實的把握是非常膚淺的
有人就不同意了:‘ChatGPT 是廣泛知識和巨大創造力的源泉,已經在大量書籍和其他信息源上接受過訓練。’
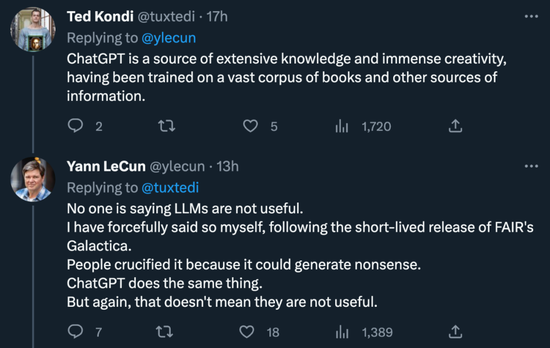
對此,LeCun 也表明了自己觀點:‘沒人說 LLM 沒用。FAIR 的 Galactica 短暫發布期間,我自己也曾這么說過。人們把它釘在十字架上,因為它會產生胡說八道。ChatGPT 做了同樣的事情。但同樣,這并不意味著它們沒有用。’
實際上,這篇《大西洋報》的文章是對麻省理工學院認知科學小組的一篇論文進行了評論。讓我們看一下具體的研究內容。
這篇論文說了啥?
這篇論文的標題為《Dissociating Language and Thought in Large Language Models: a Cognitive Perspective》,作者分別來自得克薩斯大學奧斯汀分校、MIT 和 UCLA。

論文地址:https://arxiv.org/pdf/2301.06627.pdf
我們知道,如今的大型語言模型(LLM)通常能夠生成連貫、合乎語法且看起來有意義的文本段落。這一成就引發了人們的猜測,即這些網絡已經是或者很快將成為‘思維機器’,從而執行需要抽象知識和推理的任務。
在本文中,作者考慮了兩個不同方面的語言使用表現來觀察 LLM 的能力,分別如下:
-
形式語言能力,包括給定語言的規則和模式知識;
-
功能語言能力,現實世界中語言理解和使用所需的一系列感知能力。
借鑒認知神經科學的證據,作者表明人類的形式能力依賴特定的語言處理機制,而功能能力需要語言之外的多種能力,它們構成了形式推理、世界知識、情境建模和社會認知等思維能力。與人類的兩種能力區別相似,LLM 在需要形式語言能力的任務上表現出色(盡管還不完美),但在很多需要功能能力的測試中卻往往失敗。
基于這一證據,作者認為,其一現代 LLM 應該被認真地作為具備形式語言技能的模型,其二玩轉現實生活語言使用的模型需要合并或開發核心語言模塊以及建模思維所需的多種非特定語言的認知能力。
總之,他們認為,形式語言能力和功能語言能力之間的區別有助于理清圍繞 LLM 潛力的討論,并為構建以類人方式理解和使用語言的模型提供了途徑。LLM 在很多非語言任務上的失敗并沒有削弱它們作為語言處理的良好模型,如果以人類的思維和大腦作為類比,未來 AGI 的進步可能取決于將語言模型以及代表抽象知識和支持復雜推理的模型相結合。
ChatGPT 數學水平仍需要提升
LLM 在語言之外的功能能力(如推理等)方面有所欠缺,OpenAI 的 ChatGPT 正是一個例子。雖然此前官宣數學能力再升級,但被網友吐槽只能精通十以內的加減法。
近日在一篇論文《Mathematical Capabilities of ChatGPT》中,牛津大學、劍橋大學等機構的研究者在公開可用和手工制作的數據集上測試 ChatGPT 的數學能力,并衡量了它與在 Minerva 等數學語料庫上訓練的其他模型的性能。同時通過模擬數學家日常專業活動(問答、定理搜索)中出現的各種用例,來測試 ChatGPT 是否可以稱為專業數學家的有用助手。

論文地址:https://arxiv.org/pdf/2301.13867.pdf
研究者引入并公開了一個全新數據集 —— GHOSTS,它是首個由數學研究人員制作和管理的自然語言數據集,涵蓋了研究生水平的數學,并全面概述語言模型的數學能力。他們在 GHOSTS 上對 ChatGPT 進行了基準測試,并根據細粒度標準評估性能。
測試結果顯示,ChatGPT 的數學能力明顯低于普通數學研究生,它通常可以理解問題但無法給出正確答案。
每月 20 美元,ChatGPT Plus 大會員上線
不管怎么說,ChatGPT 在商業上的成功是有目共睹的。
剛剛,OpenAI 宣布了‘ChatGPT Plus’,一項每月 20 美元的新付費會員服務。
訂閱者將獲得一些好處:
-
可以普遍使用 ChatGPT,即使在高峰期也是如此;
-
更快的響應時間;
-
優先獲得新功能和改進。
OpenAI 表示,它將在‘未來幾周內’向在美國和在其候補名單上的人發出該服務的邀請,并表示會將該服務推廣到其他國家和地區。
一個多星期前,有消息稱 OpenAI 要以每月 42 美元的價格推出 ChatGPT 服務的 plus 版或 pro 版,但最終定下的每月 20 美元,顯然讓更廣泛的人群有能力使用該服務,包括學生和企業。
某種程度上,這將為市場上任何想要推出的 AI 聊天機器人設定付費標準。鑒于 OpenAI 是該領域的先行者,如果其他公司試圖發布每月付費超過 20 美元的機器人,都必須先解釋明白一件事 —— 自己的聊天機器人憑什么比 ChatGPT Plus 更值錢?

(聲明:本文僅代表作者觀點,不代表新浪網立場。)

作者簡介



