

為了把Deepfake關進籠子,各大公司都拼了
 題圖來源:谷歌、@MaYiLong0
題圖來源:谷歌、@MaYiLong0歡迎關注“新浪科技”的微信訂閱號:techsina
Google Colab 終于宣布禁止 deepfake 項目
文|杜晨 編輯 | Vicky Xiao
來源:硅星人
曾幾何時,deepfake 在互聯網上格外猖獗,新聞和成人類內容成為了“換臉”的重災區。
由于受眾廣泛,市面上有不少現成的 deepfake 算法,供用戶使用,如 DeepFaceLab (DFL) 和 FaceSwap。并且,由于深度學習技術的普及,也有一些低成本甚至免費的在線工具,可以訓練這些算法,從而讓好事之徒達到其目的。
常用的工具之一就是谷歌的 Colab,一個免費的托管式 Jupyter 筆記本服務。簡單來說,用戶可以在 Colab 的網頁界面上運行復雜的代碼,“白用l”谷歌的 GPU 集群,從而訓練那些依賴高性能硬件的深度學習項目。
不過就在本月,谷歌終于對 colab 在線訓練 deepfake 痛下殺手。
前不久,DFL-Colab 項目的開發者 chervonij 發現,谷歌本月中下旬將 deepfake 加入到了 Colab 的禁止項目列表當中:
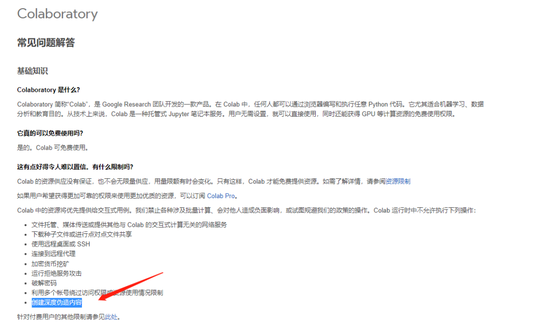 圖片來源:谷歌
圖片來源:谷歌chervonij 還表示,他最近嘗試用 Colab 運行自己的代碼的時候,遇到了如下的提示:
“您正在執行被禁止的代碼,這將有可能影響您在未來使用 Colab 的能力。請查閱FAQ頁面下專門列出的禁止行為。”
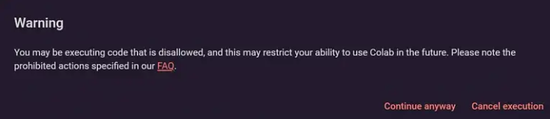 圖片來源:DFL Discord 頻道
圖片來源:DFL Discord 頻道然而這個彈出提示只是做出警告,并沒有完全禁止,用戶仍然可以繼續執行代碼 (continue anyway)。
有用戶發現,這次谷歌的行動應該是主要針對 DFL 算法的,考慮到 DFL 是目前網絡上 deepfake 行為最常采用的算法。與此同時,另一個沒那么流行,的 deepfake 算法 FaceSwap 就比較幸運,仍然可以在 Colab 上運行且不會彈出提示。
FaceSwap聯合開發者 Matt Tora 接受 Unite.ai 采訪時表示,自己并不認為谷歌此舉是出于道德目的:
“Colab 是一個偏向 AI 教育和研究方向的工具。用它來進行規模化的 deepfake 項目的訓練,和 Colab 的初衷背道而馳。”
他還補充表示,自己的 FaceSwap 項目的重要目的就是通過 deepfake 來教育用戶關于 AI 和深度學習模型的運行原理,言外之意可能這才是 FaceSwap 沒有被 Colab 針對的理由。
“出于保護計算資源,讓真正需要的用戶能夠獲取這些資源的目的,我理解谷歌的這一舉動。”
Colab 未來是否將會完全禁止 deepfake 類項目的執行?對于不聽勸的用戶會有怎樣的懲罰?目前谷歌并未對此次修改作出回應,這些問題也暫時沒有答案。
不過我們可以確定的是,谷歌肯定是不希望 Colab 這樣一個出于公益目的,提供免費訓練資源的平臺,被 deepfake 開發者濫用。
Google Research 將 Colab 免費開放給廣大用戶,目的是降低深度學習訓練的硬件成本門檻,甚至讓幾乎沒有編程知識背景的用戶也能輕松上手——也即所謂的 AI 普及化 (democratization of AI)。
由于區塊鏈行業的爆發增長,以及疫情的次生影響,當今全球芯片(特別是 GPU) 很大程度上仍然處于斷供狀態。所以如果是為了節約資源而禁用 Colab 運行 deepfake 項目,確實可以理解。
不過除了 deepfake 之外,Colab 禁止的其它行為當中也的確包括大眾認知的惡意行為,比如運行黑客攻擊、暴力破解密碼等。
| deepfake 使用門檻變高?
在過去相當長一段時間里,對于初入門和中等水平的 deepfake 視頻創作者來說,想要實現一般可接受畫質(480p或720p以上)的內容輸出,自己卻沒有足夠的硬件配置的話,那么 Colab 幾乎是唯一的正確選擇。
畢竟 Colab 界面簡單,上手輕松,訓練性能達到可以接受的水平,而且還免費,沒有理由不用。前面提到的一些 deepfake 算法項目也都針對 Colab 提供了代碼支持。
要討論 deepfake,很難避開新聞換臉視頻和成人換臉內容。硅星人發現,DFL 主項目頁面直接把新聞視頻換臉作為主要使用場景之一,并且頁面中引導的一些用戶社群也都默許明星或私人復仇式 (revenge porn) 的換臉成人內容,使得此類內容大量存在。
現如今谷歌決定禁止 deepfake 類項目在 Colab 上運行,勢必將對私人的 deepfake 內容制作造成不小的打擊。
因為這意味著那些初級和中級 deepfake 制作者將失去一個最重要的免費工具,讓他們繼續制作此類內容的成本顯著提高。
不過據領域內一些內幕人士表示,那些最頂級的,將 deepfake 當作一門生意的專業制作者,已經基本實現了完全“自主生產”。
這群人通過非法銷售及會員募捐等方式,賺到了不少錢,可以投資更加高級的設備。現在他們可以制作分辨率、清晰度和臉部還原度更高的 deepfake 視頻,從而不用依賴 Colab 以及云計算等在線服務,就能實現穩定生產和營收。
舉個例子:想要實現2k甚至4k分辨率和60fps的幀率,并且單片單次渲染用時在可以接受的范圍(比如幾天)的話,需要一個龐大的渲染農場,至少10臺電腦,每臺兩張支持 SLI 技術的英偉達 RTX 高端顯卡,以及上百GB的內存。這樣下來僅單臺的購置成本就已經相當高了,更別提還要算上運轉時的電費(渲染、冷卻等),可以說是一筆相當大的投資。
很遺憾,對于這群人來說,谷歌的新政策對他們完全起不到作用。只有全社會對 deepfake 帶來的負面影響提升重視,整個科技行業都行動起來,deepfake 的濫用問題才能得到解決。
| 把 deepfake 關進籠子里,各國、各大公司都在行動
谷歌
這的確不是谷歌第一次出面打擊 deepfake 內容制作了。在2019年,Google Research 就發表過一個大型視頻數據集。其背后是谷歌在自己內部通過制作 deepfake 視頻的方式,從而試圖了解相關算法的工作原理。
對于谷歌來說,它需要提高識別 deepfake 的能力,從而在商業化產品環境里(最典型的就是 YouTube 用戶視頻上傳),從源頭上切斷惡意換臉視頻的傳播途徑。以及,第三方公司也可以使用谷歌開放的這個數據集來訓練 deepfake 探測器。

不過,近幾年 Google Research 確實沒有花太多心思在打擊 deepfake 上。反而,該公司最近推出的 Imagen,一個超高擬真度的文字生成圖片模型,效果非常驚人,反倒是引發了一些批評。
 Imagen 文字轉圖片的效果 圖片來源:谷歌
Imagen 文字轉圖片的效果 圖片來源:谷歌微軟
微軟研究院在2020年共同推出了一項 deepfake 探測技術,名為 Microsoft Video Authenticator。它能夠檢測畫面中的渲染邊界當中灰階數值的不正常變化,對視頻內容進行逐幀實時分析,并且生成置信度分數 (confidence score)。
微軟也在和包括紐時、BBC、加拿大廣播公司等頂級媒體合作,在新聞行業的場景下對 Video Authenticator 的能力進行檢測。
與此同時,微軟也在 Azure 云計算平臺中加入了媒體內容元數據 (metadata) 校驗的技術。通過這一方式,那些被修改過的視頻內容可以和原視頻的進行元數據比對——和下載文件的時候比對 MD5 值差不多意思。
Meta
2020年,Facebook 宣布在 Facebook 產品平臺全面禁止 deepfake 類視頻。
然而這個政策執行得并不徹底。比如,目前在 Instagram 上還可以經常見到那個著名的中國翻版馬斯克 deepfake 視頻(主要是從 TikTok 上轉發過來的)。
 圖片來源:MaYiLong0|TikTok
圖片來源:MaYiLong0|TikTok在行業層面,Meta、亞馬遜 AWS、微軟、MIT、UC伯克利、牛津大學等公司和機構在2019年共同發起了一個 deepfake 檢測挑戰賽,鼓勵更多、更優秀、更與時俱進的檢測技術。
Twitter:
2020年 Twitter 封殺了一批經常發布 deepfake 視頻的賬號。不過對于其它 deepfake 內容,Twitter 并沒有完全限制,而是會打上一個標簽“被修改的內容”(manipulated media),并且提供第三方事實核查機構的檢測結果。

創業公司:
OARO MEDIA:西班牙公司,提供一套對內容進行多樣化數字簽名的工具,從而減少deepfake 等被修改過的內容傳播對客戶造成的負面影響。
Sentinel:位于愛沙尼亞,主要開發 deepfake 內容檢測模型。

Quantum+Integrity:瑞士公司,提供一套基于 API 的 SaaS 服務,可以進行各種基于圖像類的檢測,能力包括視頻會議實時 deepfake、截屏或圖片“套娃”、虛假身份證件等。

國家(立法和行政)
中國:2020年印發的《法治社會建設實施綱要(2020 - 2025年)》進一步要求,對深度偽造等新技術應用,制定和完善規范管理辦法。
美國:2019年正式簽署生效的2020財年國防批準法當中包含了和 deepfake 相關的條文,主要是要求政府向立法機構通報涉及跨國、有組織、帶有政治目的的 deepfake 虛假信息行為。
加州、紐約州和伊利諾伊州都有自己的 deepfake 相關法律,主要目的是保護 deepfake 受害者的權益。
歐盟:GDPR、歐盟人工智能框架提議、版權保護框架、虛假信息針對政策等高級別法律文件,都對可能和 deepfake 有關的事務實現了交叉覆蓋。不過,整個區域級別目前并沒有專門針對 deepfake 的法律和政策。
在成員國級別上,荷蘭立法機構在2020年曾經要求政府制定打擊 deepfake 成人視頻的政策,以及表示會考慮將相關問題寫入該國刑法。

(聲明:本文僅代表作者觀點,不代表新浪網立場。)

作者簡介




