

DeepMind打造AI游戲王!挑戰各種最強棋牌AI,戰斗力驚人
 谷歌第四代TPU立功,新游戲AI系統單挑多個AI棋牌高手。
谷歌第四代TPU立功,新游戲AI系統單挑多個AI棋牌高手。歡迎關注“新浪科技”的微信訂閱號:techsina
文/ZeR0
來源:智東西(ID:zhidxcom)
智東西12月9日消息,谷歌母公司Alphabet旗下頂尖AI實驗室DeepMind曾因其AI系統AlphaGo擊敗頂尖人類圍棋選手、AlphaStar贏得星際爭霸2而爆紅全球。本周,它又披露新的游戲AI系統。
與此前開發的游戲系統不同,DeepMind的AI新作Player of Games是第一個在完全信息游戲以及不完全信息游戲中都能實現強大性能的AI算法。完全信息游戲如中國圍棋、象棋等棋盤游戲,不完全信息游戲如撲克等。
這是向能夠在任意環境中學習的真正通用AI算法邁出的重要一步。
Player of Game在象棋、圍棋這兩種完全信息游戲和德州撲克、蘇格蘭場這兩種不完全信息游戲中與頂尖AI智能體對戰。
從實驗結果來看,DeepMind稱Player of Games在完全信息游戲中的表現已經達到了“人類頂級業余選手”水平,但如果給予相同資源,該算法的表現可能會明顯弱于AlphaZero等專用游戲算法。
在兩類不完全信息游戲中,Player of Games均擊敗了最先進的AI智能體。
 論文鏈接:https://arxiv.org/pdf/2112.03178.pdf
論文鏈接:https://arxiv.org/pdf/2112.03178.pdf深藍、AlphaGo等AI系統僅擅長玩一種游戲
計算機程序挑戰人類游戲選手由來已久。
20世紀50年代,IBM科學家亞瑟·塞繆爾(Arthur L. Samuel)開發了一個跳棋程序,通過自對弈來持續改進其功能,這項研究給很多人帶來啟發,并普及了“機器學習”這個術語。
此后游戲AI系統一路發展。1992年,IBM開發的TD-Gammon通過自對弈在西洋雙陸棋中實現大師級水平;1997年,IBM深藍DeepBlue在國際象棋競賽中戰勝當時的世界棋王卡斯帕羅夫;2016年,DeepMind研發的AI系統AlphaGo在圍棋比賽中擊敗世界圍棋冠軍李世石……
 ▲IBM深藍系統vs世界棋王卡斯帕羅夫
▲IBM深藍系統vs世界棋王卡斯帕羅夫這些AI系統有一個共同之處,都是專注于一款游戲。比如塞繆爾的程序、AlphaGo不會下國際象棋,IBM的深藍也不會下圍棋。
隨后,AlphaGo的繼任者AlphaZero做到了舉一反三。它證明了通過簡化AlphaGo的方法,用最少的人類知識,一個單一的算法可以掌握三種不同的完全信息游戲。不過AlphaZero還是不會玩撲克,也不清楚能否玩好不完全信息游戲。
實現超級撲克AI的方法有很大的不同,撲克游戲依賴于博弈論的推理,來保證個人信息的有效隱藏。其他許多大型游戲AI的訓練都受到了博弈論推理和搜索的啟發,包括Hanabi紙牌游戲AI、The Resistance棋盤游戲AI、Bridge橋牌游戲AI、AlphaStar星際爭霸II游戲AI等。
 ▲2019年1月,AlphaStar對戰星際爭霸II職業選手
▲2019年1月,AlphaStar對戰星際爭霸II職業選手這里的每個進展仍然是基于一款游戲,并使用了一些特定領域的知識和結構來實現強大的性能。
DeepMind研發的AlphaZero等系統擅長國際象棋等完全信息游戲,而加拿大阿爾伯特大學研發的DeepStack、卡耐基梅隆大學研發的Libratus等算法在撲克等不完全信息游戲中表現出色。
對此,DeepMind研發了一種新的算法Player of Games(PoG),它使用了較少的領域知識,通過用自對弈(self-play)、搜索和博弈論推理來實現強大的性能。
更通用的算法PoG:棋盤、撲克游戲都擅長
無論是解決交通擁堵問題的道路規劃,還是合同談判、與顧客溝通等互動任務,都要考慮和平衡人們的偏好,這與游戲策略非常相似。AI系統可能通過協調、合作和群體或組織之間的互動而獲益。像Player of Games這樣的系統,能推斷其他人的目標和動機,使其與他人成功合作。
要玩好完全的信息游戲,需要相當多的預見性和計劃。玩家必須處理他們在棋盤上看到的東西,并決定他們的對手可能會做什么,同時努力實現最終的勝利目標。不完全信息游戲則要求玩家考慮隱藏的信息,并思考下一步應該如何行動才能獲勝,包括可能的虛張聲勢或組隊對抗對手。
DeepMind稱,Player of Games是首個“通用且健全的搜索算法”,在完全和不完全的信息游戲中都實現了強大的性能。
Player of Games(PoG)主要由兩部分組成:1)一種新的生長樹反事實遺憾最小化(GT-CFR);2)一種通過游戲結果和遞歸子搜索來訓練價值-策略網絡的合理自對弈。
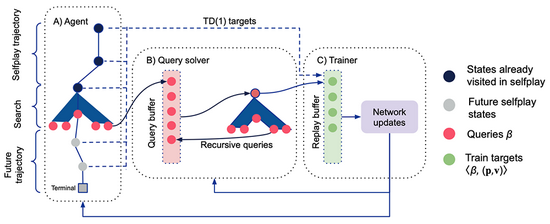 ▲Player of Games訓練過程:Actor通過自對弈收集數據,Trainer在分布式網絡上單獨運行
▲Player of Games訓練過程:Actor通過自對弈收集數據,Trainer在分布式網絡上單獨運行在完全信息游戲中,AlphaZero比Player of Games更強大,但在不完全的信息游戲中,AlphaZero就沒那么游刃有余了。
Player of Games有很強通用性,不過不是什么游戲都能玩。參與研究的DeepMind高級研究科學家馬丁·施密德(Martin Schmid)說,AI系統需考慮每個玩家在游戲情境中的所有可能視角。
雖然在完全信息游戲中只有一個視角,但在不完全信息游戲中可能有許多這樣的視角,比如在撲克游戲中,視角大約有2000個。
此外,與DeepMind繼AlphaZero之后研發的更高階MuZero算法不同,Player of Games也需要了解游戲規則,而MuZero無需被告知規則即可飛速掌握完全信息游戲的規則。
在其研究中,DeepMind評估了Player of Games使用谷歌TPUv4加速芯片組進行訓練,在國際象棋、圍棋、德州撲克和策略推理桌游《蘇格蘭場》(Scotland Yard)上的表現。
 ▲蘇格蘭場的抽象圖,Player of Games能夠持續獲勝
▲蘇格蘭場的抽象圖,Player of Games能夠持續獲勝在圍棋比賽中,AlphaZero和Player of Games進行了200場比賽,各執黑棋100次、白棋100次。在國際象棋比賽中,DeepMind讓Player of Games和GnuGo、Pachi、Stockfish以及AlphaZero等頂級系統進行了對決。
 ▲不同智能體的相對Elo表,每個智能體與其他智能體進行200場比賽
▲不同智能體的相對Elo表,每個智能體與其他智能體進行200場比賽在國際象棋和圍棋中,Player of Games被證明在部分配置中比Stockfish和Pachi更強,它在與最強的AlphaZero的比賽中贏得了0.5%的勝利。
盡管在與AlphaZero的比賽中慘敗,但DeepMind相信Player of Games的表現已經達到了“人類頂級業余選手”的水平,甚至可能達到了專業水平。

Player of Games在德州撲克比賽中與公開可用的Slumbot對戰。該算法還與Joseph Antonius Maria Nijssen開發的PimBot進行了蘇格蘭場的比賽。
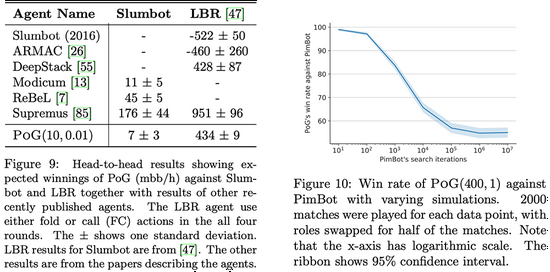 ▲不同智能體在德州撲克、蘇格蘭場游戲中的比賽結果
▲不同智能體在德州撲克、蘇格蘭場游戲中的比賽結果結果顯示,Player of Games是一個更好的德州撲克和蘇格蘭場玩家。與Slumbot對戰時,該算法平均每hand贏得700萬個大盲注(mbb/hand),mbb/hand是每1000 hand贏得大盲注的平均數量。
同時在蘇格蘭場,DeepMind稱,盡管PimBot有更多機會搜索獲勝的招數,但Player of Games還是“顯著”擊敗了它。
研究關鍵挑戰:訓練成本太高
施密德相信Player of Games是向真正通用的游戲系統邁出的一大步。
實驗的總體趨勢是,隨著計算資源增加,Player of Games算法以保證產生更好的最小化-最優策略的逼近,施密德預計這種方法在可預見的未來將擴大規模。
“人們會認為,受益于AlphaZero的應用程序可能也會受益于游戲玩家。”他談道,“讓這些算法更加通用是一項令人興奮的研究。”
當然,傾向于大量計算的方法會讓擁有較少資源的初創公司、學術機構等組織處于劣勢。在語言領域尤其如此,像OpenAI的GPT-3這樣的大型模型已取得領先性能,但其通常需要數百萬美元的資源需求,這遠超大多數研究小組的預算。
即便是在DeepMind這樣財力雄厚的公司,成本有時也會超過人們所能接受的水平。
對于AlphaStar,公司的研究人員有意沒有嘗試多種構建關鍵組件的方法,因為高管們認為訓練成本太高。根據DeepMind披露的業績文件,它在去年才首次盈利,年收入達到8.26億英鎊(折合約69億人民幣),獲得4380萬英鎊(折合約3.67億人民幣)的利潤。從2016年~2019年,DeepMind共計虧損13.55億英鎊(折合約113億人民幣)。

據估計,AlphaZero的訓練成本高達數千萬美元。DeepMind沒有透露Player of Games的研究預算,但考慮到每個游戲的訓練步驟從數十萬到數百萬不等,這個預算不太可能低。
結語:游戲AI正助力突破認知及推理挑戰
目前游戲AI還缺乏明顯的商業應用,而DeepMind的一貫理念是借其去探索突破認知和推理能力所面臨的獨特挑戰。近幾十年來,游戲催生了自主學習的AI,這為計算機視覺、自動駕駛汽車和自然語言處理提供了動力。
隨著研究從游戲轉向其他更商業化的領域,如應用推薦、數據中心冷卻優化、天氣預報、材料建模、數學、醫療保健和原子能計算等等,游戲AI研究對搜索、學習和博弈推理的價值愈發凸顯。
“一個有趣的問題是,這種水平的游戲是否可以用較少的計算資源實現。”這個在Player of Games論文最后中被提及的問題,還沒有明確的答案。

(聲明:本文僅代表作者觀點,不代表新浪網立場。)

作者簡介




