

谷歌:引領ML發展的遷移學習,究竟在遷移什么?丨NeurIPS 2020
來源:新智元
在機器學習領域大熱的分類學習任務中,為了保證訓練得到的分類模型具有準確性和高可靠性,一般會作出兩個基本假設:
用于學習的訓練樣本與新的測試樣本滿足獨立同分布;
必須有足夠可用的訓練樣本才能學習得到一個好的分類模型。
但實際情況很難滿足這兩個條件。

很多 ML 技術只有在訓練數據和測試數據處于相同的特征空間中或具有相同分布的假設下才能很好地發揮作用,一旦隨著時間推移,標簽可用性變差或標注樣本數據缺乏,效果便不盡如人意。
因此,這就引起 ML 中另一個需要關注的重要問題,如何利用源領域(Source domian)中少量的可用標簽訓練樣本 / 數據訓練出魯棒性好的模型,對具有不同數據分布的無標簽 / 少可用標簽的目標領域(Target domain)進行預測。
由此,遷移學習(Transfer Learning)應運而生,并引起了廣泛的關注和研究。

近幾年來,已經有越來越多的研究者投入到遷移學習中。每年機器學習和數據挖掘的頂級會議中都有關于遷移學習的文章發表。
顧名思義,遷移學習就是把一個領域已訓練好的模型參數遷移到另一個領域,使得目標領域能夠取得更好的學習效果。鑒于大部分的數據具有存在相關性,遷移學習可以比較輕松地將模型已學到的知識分享給新模型,從而避免了從頭學習,這加快效率,也大大提高樣本不充足任務的分類識別結果。
今年的 NeurIPS 上,谷歌的一支研究團隊發表了一篇名為 What is being transferred in transfer learning? 的論文,揭示了關于遷移學習的最新研究進展。

在這篇論文中,作者便向我們提供了新的工具和分析方法,從不同的角度剖析了不同模塊的作用及影響成功遷移的因素,得到了一些有趣的結論,例如,相比高層的特征,預訓練模型適合遷移的主要是低層的統計信息。
具體而言,通過對遷移到塊混洗圖像(block-shuffled images)的一系列分析,他們從學習低層數據統計中分離出了特征復用(feature reuse)的效果,并表明當從預訓練權重進行初始化訓練時,該模型位于損失函數 “地圖” 的同一 “盆地”(basin)中,不同實例在特征空間中相似,并且在參數空間中接近(注:basin 一詞在該領域文獻中經常使用,指代參數空間中損失函數相對較低值的區域)。
遷移學習應用現狀
前百度首席科學家吳恩達(Andrew Ng)曾經說過:遷移學習將會是繼監督學習之后,下一個機器學習商業成功的驅動力。
在 2016 年的 NIPS 會議上,吳恩達曾給出了一個未來 AI 方向的技術發展判斷:毋庸置疑,目前成熟度最高、成功商用的是監督學習,緊隨其后,下一個近 5 年內最可能走向商用的 AI 技術將會是遷移學習。

DeepMind 首席執行官 Demis Hassabis 也曾表示,遷移學習也是最有前途的技術之一,有朝一日可能會觸發通用人工智能的誕生(AGI)。在當下深度學習的發展大潮中看來,遷移學習確實如此。
如今距離這兩位 AI 學者的 “預測” 已經過去了近 5 年。那么,目前遷移學習應用正呈現怎樣的局面?
在計算機視覺領域,遷移學習已經有了很多成功的應用,甚至在一些任務中,機器能以超越人類精確度的水平完成某項任務。
而在 NLP 領域,遷移學習也是一系列研究突破中的關鍵組成部分,尤其在跨域情感分析上展現了其潛力。

與此同時,遷移學習所存在的問題也隨之暴露。研究人員發現,某些案例中,源域和目標域之間在視覺形式上仍存在不小的差異。對于研究人員而言,已經很難理解什么能夠成功進行遷移,以及網絡的哪些部分對此負責。在這篇論文中,研究團隊專注于研究視覺領域的遷移學習。
文中涉及的兩大數據集分別是:
CheXpert 數據集,這是在 2019 年 AAAI 上,吳恩達的斯坦福團隊發布的大型 X 射線數據集,此數據集考慮到了不同疾病的胸部 X 射線醫學影像,它包含 65,240 位病人的 224,316 張標注好的胸部 X 光片以及放射科醫師為每張胸片寫的病理報告;
DomainNet 數據集,該數據集發布在 2019 年 ICCV 上,此論文作者收集并注釋了迄今為止最大的 UDA 數據集,專門用于探究不同領域中的遷移學習。其中存在顯著的領域差異和大量的類別劃分,包含 6 個域和分布在 345 個類別中的近 60 萬幅圖像,范圍從真實圖像到草圖,剪貼畫和繪畫樣本,解決了多源 UDA 研究在數據可用性方面的差距。
4 種網絡的遷移學習
他們分析了四種不同情況下的網絡:
1. 預訓練網絡(P, pre-trained model);
2. 隨機初始化的網絡(RI, random initialization);
3. 在源域上進行預訓練后在目標域上進行微調的網絡(P-T, model trained/fine-tuned on target domain starting from pre-trained weights);
4. 隨機初始化對目標域進行普通訓練的模型(RI-T, model trained on target domain from random initialization)。
首先,團隊通過改組數據研究了特征復用。將下游任務的圖像劃分為相同大小的塊并隨機排序,數據中的塊混洗破壞了圖像的視覺特征。該分析表明了特征復用的重要性,并證明了不受像素混洗干擾的低級統計數據在成功傳輸中也起作用。
然后,需要比較經過訓練的模型的詳細行為。為此,他們調查了從預訓練和從零開始訓練的模型兩者間的異同。實驗證明,與通過隨機初始化訓練的模型相比,使用預訓練的權重訓練的模型的兩個實例在特征空間上更為相似。
再就是調查了預訓練權重和隨機初始化權重訓練的模型的損失情況,并觀察到從預訓練權重訓練的兩個模型實例之間沒有性能降低,這表明預訓練權重能夠將優化引導到損失函數的 basin。
接下來,我們結合文章中的實驗和結果來詳細的分析方法論并探討 “What is being transferred?”。
什么被遷移了?
人類視覺系統的組成具有層次化的特征,視覺皮層中的神經元對邊緣等低級特征做出響應,而上層的神經元對復雜的語義輸入進行響應。一般認為,遷移學習的優勢來自重用預先訓練的特征層。如果下游任務因為太小或不夠多樣化而無法學習良好的特征表示時,這會變得特別有用。
因此,很容易理解,大家認為遷移學習有用的直覺思維就是,遷移學習通過特征復用來給樣本少的數據提供一個較好的特征先驗。
然而,這種直覺卻無法解釋為什么在遷移學習的許多成功應用中,目標領域和源領域在視覺上差異很大的問題。

圖1 。圖片出處:arXiv
為了更清楚地描述特征復用的作用,作者使用了圖 1 中包含自然圖像(ImageNet)的源域(預訓練)和一些與自然圖像的視覺相似度低的目標域(下游任務)。
圖 2 可以看到,real domain 具有最大的性能提升,因為該域包含與 ImageNet 共享相似視覺特征的自然圖像。這能夠支撐團隊成員的假設 —— 特征復用在遷移學習中起著重要作用。另一方面,在數據差別特別大的時候(CheXpert 和 quickdraw),仍然可以觀察到遷移學習帶來的明顯的性能提升。

除最終性能外,在所有情況下,P-T 的優化收斂速度都比 RI-T 快得多。這也暗示出預訓練權重在遷移學習中的優勢并非直接來自特征復用。
為了進一步驗證該假設,團隊修改了下游任務,使其與正常視覺域的距離進一步拉大,尤其是將下游任務的圖像劃分為相等大小的塊并隨機排序。
混洗擾亂了那些圖像中的高級視覺功能,模型只能抓住淺層特征,而抽象特征沒法很好地被提取。
其中,塊大小 224*224 的極端情況意味著不進行混洗;在另一種極端情況下,圖像中的所有像素都將被混洗,從而使得在預訓練中學到的任何視覺特征完全無用。
在本文中,團隊成員創造出了一種特殊情況,每個通道的像素都可以獨立的移動,并且可以移動到其他通道中。

圖3 。圖片出處:arXiv
圖 3 顯示了不同塊大小對最終性能和優化速度的影響。我們可以觀察到以下幾點:
隨著打亂程度的加劇,RI-T 和 P-T 的最終性能都會下降,任務越發困難;
相對精度差異隨塊尺寸(clipart, real)的減小而減小,說明特征復用很有效果;
quickdraw 上情況相反是由于其數據集和預訓練的數據集相差過大,但是即便如此,在 quickdraw 上預訓練還是有效的,說明存在除了特征復用以外的因素;
P-T 的優化速度相對穩定,而 RI-T 的優化速度隨著塊尺寸的減小時存在急劇的下降。這表明特征復用并不是影響 P-T 訓練速度的主要因素。
由上述實驗得出結論,特征復用在遷移學習中起著非常重要的作用,尤其是當下游任務與預訓練域共享相似的視覺特征時。但是仍存在其他因素,例如低級別的統計信息,可能會帶來遷移學習的顯著優勢,尤其是在優化速度方面。
失誤和特征相似性
這部分主要通過探究不同模型有哪些 common mistakes 和 uncommon mistakes 來揭示預訓練的作用。
為了理解不同模型之間的差異,作者首先比較兩個 P-T,一個 P-T 加一個 RI-T 和兩個 RI-T 之間的兩類錯誤率并發現 P-T 和 RI-T 模型之間存在許多 uncommon mistakes,而兩個 P-T 的 uncommon mistakes 則要少得多。對于 CheXpert 和 DomainNet 目標域,都是這種情況。
在 DomainNet 上可視化每個模型的兩類錯誤并觀察得到,P-T 不正確和 RI-T 正確的數據樣本主要包括模棱兩可的例子;而 P-T 是正確的數據樣本和 RI-T 是不正確的數據樣本也包括許多簡單樣本。
這符合假設,P-T 在簡單樣本上的成功率很高,而在比較模糊難以判斷的樣本上比較難 (而此時 RI-T 往往比較好), 說明 P-T 有著很強的先驗知識,因此很難適應目標域。
為了加強對上述想法的驗證,團隊成員又對特征空間中兩個網絡的相似性進行了研究。
通過中心核對齊 (CKA, Centered Kernel Alignment) 這一指標發現,P-T 的兩個實例在不同層之間非常相似,在 P-T 和 P 之間也是如此。但是 P-T 和 RI-T 實例或兩個 RI-T 實例之間,相似性非常低。

表2 。圖片出處:arXiv
也就是說,基于預訓練的模型之間的特征相似度很高,而 RI-T 與其他模型相似度很低,哪怕是兩個相同初始化的 RI-T。這顯然在說明預訓練模型之間往往是在重復利用相同的特征,也就強調了特征復用的作用。表 2 為不同模型的參數的距離,同樣能夠反映出上述結論。
泛化性能
更好度量泛化性能的常用標準,是研究在最終解決方案附近的損失函數里 basin 程度。
作者用Θ和Θ?表示兩個不同檢查點的所有權重,通過兩個權重的線性插值{Θ?=(1-λ)Θ+λΘ?:λ?[0,1]} 評估一系列模型的表現。
由于神經網絡的非線性和組成結構,兩個性能良好的模型權重的線性組合不一定能定義效果良好的模型,因此通常會沿線性插值路徑預期到性能降低。
但是,當兩個解屬于損失函數的同一 basin 時,線性插值仍保留在 basin 中,此時的結果是,不存在性能障礙。此外,對來自同一 basin 的兩個隨機解進行插值通常可以產生更接近 basin 中心的解,這可能比端點具有更好的泛化性能。
團隊將重點放在凸包(convex hull)和線性插值上,以避免產生瑣碎的連通性結果。需要強調的是,要求 basin 上的大多數點的凸組合也都在 basin 上,這種額外的約束使得通過低損耗(非線性)路徑連接或不連接多個 basin。
此概念的具體形式化以及將凸集設置為 basin 的三點要求論文中均給出了詳細說明,在此便不再贅述。

圖 4 中所顯示出的插值結果,左為 DomainNet real, 右為 quickdraw。圖片出處:arXiv
一方面,兩次隨機運行的 P-T 解決方案之間沒有觀察到性能降低,這表明預訓練的權重將優化引導到了損失函數的 basin。另一方面,在兩個 RI-T 運行的解決方案之間清楚地觀察到了障礙。可見預訓練模型之間的損失函數是很光滑的,不同于 RI-T。
模塊重要度
如果我們將訓練好的模型的某一層參數替換為其初始參數,然后觀察替換前后的正確率就能一定程度上判斷這個層在整個網絡中的重要性,那么,模塊重要度就是一個這樣的類似的指標。

圖5。圖片出處:arXiv
圖 5 反映了不同模塊不同層的重要度。在監督學習案例中也有類似的模式。唯一的區別可能是,“FC” 層對于 P-T 模型的重要性是可預料的。
接下來,作者使用擴展定義以及原始定義來研究不同模塊的重要度。很容易可以注意到,優化和直接路徑都為模塊的重要度提供了有趣的見解。或許,與最終值相比,權重的最佳值是進行此分析的更好的起點選擇。
而圖 6 顯示了對 “ Conv1” 模塊的分析,正如圖 5 所示,這是一個關鍵模塊。
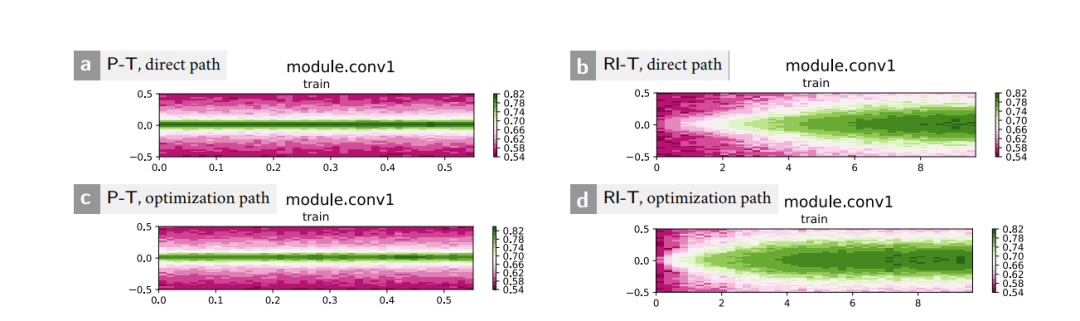
圖6。圖片出處:arXiv

圖7。圖片出處:arXiv
通過初始化來自預訓練優化路徑上不同檢查點的預訓練權重,比較遷移學習的好處。圖 7 顯示了從不同的預訓練檢查點進行微調時的最終性能和優化速度。
總體而言,預訓練的好處隨著檢查點指數的增加而增加,可得出以下結論:
在預訓練中,在學習率下降的 epoch 30 和 epoch 60 觀察到了很大的性能提升。但是,從檢查點 29、30、31(和類似的 59、60、61)初始化不會顯示出明顯不同的影響。另一方面,特別是對于 real 和 clipart 的最終性能,當從訓練前性能一直處于平穩狀態的檢查點(如檢查點 29 和 59)開始時,可以觀察到顯著的改進。這表明,預訓練性能并不總是作為預訓練權重對遷移學習有效性的忠實指標。
quickdraw 在預訓練中發現最終性能的收益要小得多,并在檢查點 10 迅速達到平穩狀態,而 real 和 clipart 直到檢查點 60 都不斷看到的性能的顯著改進。另一方面,隨著檢查點索引的增加,所有三個任務在優化速度改進上均具有明顯的優勢。
優化速度在檢查點 10 處開始達到平穩狀態,而對于 real 和 clipart,最終結果則不斷提升。在訓練前的早期檢查點是在收斂模型的 basin 之外,在訓練期間的某個點便進入 basin。這也解釋了在一些檢查點之后性能停滯不前的原因。
因此,我們可以早一步地選取檢查點,這樣便不會損失微調模型的準確性。這種現象的起點取決于預訓練模型何時進入其最終 basin。
總而言之,這項研究明確闡述了遷移學習中所遷移的內容以及網絡的哪些部分正在發揮作用。
對于成功的遷移,數據的特征復用和底層統計都非常重要。通過對輸入塊進行混洗來研究特征重用的作用,表明當從預訓練權重初始化進行訓練時,網絡停留在解決方案的同一 basin 中,特征相似并且模型在參數空間中的距離附近。
作者還進一步確認了,較低的層負責更一般的功能,較高層的模塊對參數的擾動更敏感。通過對損失函數 basin 的發現可用于改進集成方法,對低級數據統計數據的觀察提高了訓練速度,這可能會導致更好的網絡初始化方法。利用這些發現來改善遷移學習,將十分具有價值。
Refrence:
[1]https://arxiv.org/pdf/2008.11687.pdf


(聲明:本文僅代表作者觀點,不代表新浪網立場。)

作者簡介
作者文章
推薦閱讀
- 滴滴版“花唄”上線,互聯網巨頭們為何鐘愛搞金融?
-

- 滴滴在網約車行業雖然有眾多對手,但沒人可以撼動其地位已是事實,與此相比,滴滴在金融方面的表現就有些不如人意了。詳細>>
- 一文看懂醫藥電商:“賣藥”VS“用藥”下的兩種生態
-

- 隨著互聯網思維嫁接到醫療領域的嘗試,醫療電商應運而生。但在這個專業化門檻更高的領域,情況似乎有些不同。詳細>>
- 美團字節滴滴重啟支付大戰,王興張一鳴不甘心
-

- 自今年7月底美團關閉支付寶支付、王興在飯否開懟支付寶手續費高于微信后,支付賽道的表面平靜被打破,關于支付戰爭是否會重開的討論出現在臺面之上。詳細>>
- 微短劇熱起來了 1分鐘1集的“霸總故事”有錢途嗎?
-

- 這一切變量背后,都再次指向一個終極問題,微短劇到底能賺錢了嗎?詳細>>