

AI繪畫,為何聽不懂人話?

深燃(shenrancaijing)原創(chuàng)
作者 | 唐亞華
編輯 | 黎明
2023年的AI繪畫領(lǐng)域是由兩家公司的動態(tài)引爆的。
3月17日百度發(fā)布文心一言,網(wǎng)友們瘋狂發(fā)散想象力,令人捧腹的圖片接連被生成。關(guān)于文心一言文字生成圖片的討論熱情空前高漲。
緊接著,3月18日,美國Midjourney公司宣布第五版AI圖像生成服務(wù),即MidjourneyV5。本來就處在行業(yè)領(lǐng)先水平的Midjourney,這一次版本更新真正讓AI繪畫圈沸騰了。因為MidjourneyV5生成的圖片堪稱驚艷。
兩個系統(tǒng)幾乎同時發(fā)布,免不了被對比。深燃體驗后發(fā)現(xiàn),文心一言的圖片生成功能,能夠識別簡單元素、文本沒有歧義的人或事物,但涉及到成語、專有名詞,以及字面意思和實際意義不同的表述,它就會跑偏。Midjourney在這方面幾乎沒什么問題。另外,Midjourney接收到的提示詞(prompt)越詳細精準,生成的圖片越符合要求,但文心一言需求越多,系統(tǒng)越容易出錯。
調(diào)侃背后,AI生成圖片其實不是一件簡單的事情,需要在數(shù)據(jù)、算法、算力等方面綜合發(fā)力,既對技術(shù)和硬件有高要求,還對數(shù)據(jù)采集和標注等苦活累活高度依賴。文心一言的AI繪圖功能與Midjourney在以上三方面都有不小的差距。
百度方面公開表示,“大家也會從接下來文生圖能力的快速調(diào)優(yōu)迭代,看到百度的自研實力。文心一言正在大家的使用過程中不斷學(xué)習(xí)和成長,請大家給自研技術(shù)和產(chǎn)品一點信心和時間。”從業(yè)者預(yù)估,文心一言全力追趕,用一年左右的時間有希望達到國外80%以上的水平。
AI繪圖這個戰(zhàn)場,槍聲已經(jīng)打響,追逐賽、排位賽都將一輪輪上演。
搞不定成語和專有名詞,
提示詞越多AI越廢
文心一言最近接受的最大考驗,莫過于畫一幅中餐菜名圖。在網(wǎng)友們的熱情創(chuàng)作下,驢肉火燒、紅燒獅子頭等菜品出來的畫做一個比一個離譜,車水馬龍的街道、虎頭虎腦的大胖小子,同樣驚掉了大家的下巴。
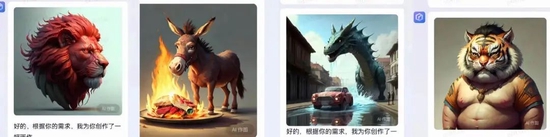
網(wǎng)友體驗文心一言時截圖,目前已更新
網(wǎng)民熱心找bug,百度程序員應(yīng)該也在背后發(fā)力,深燃測試發(fā)現(xiàn),以上內(nèi)容均已更新為可以正確顯示對應(yīng)圖片。不過,像娃娃菜、臉盆、虎皮雞蛋、三杯雞,還有胸有成竹的男人、虎背熊腰的男人,文心一言仍然給出的是字面直譯后的圖片,畫風(fēng)一言難盡。
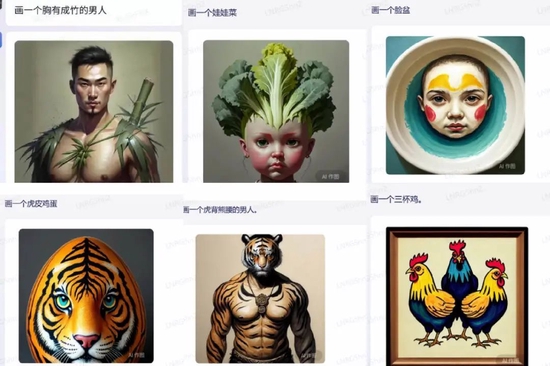
深燃截圖
即便輸入提示詞時強調(diào)“畫一個衛(wèi)浴器材水龍頭”,文心一言畫出的仍然是水中龍的頭像;當深燃輸入“畫一個風(fēng)姿綽約的人”時,系統(tǒng)畫出的是一位男士,顯然AI沒能理解風(fēng)姿綽約形容的是女人。

深燃截圖
程序員改bug的速度比不上網(wǎng)友找漏洞的速度。很快又有人發(fā)現(xiàn),文心一言畫圖時有把提示詞中譯英之后根據(jù)英文意思生成圖片的可能性,據(jù)此有人推測百度可能用國外的作圖產(chǎn)品接口,套了一個自己的殼。
深燃也驗證了一下某用戶的測試。比如輸入“水瓜”,畫出的是西瓜,這也對應(yīng)西瓜的英文單詞Watermelon;要求畫樹葉、封面、蘋果,畫出的圖是樹葉覆蓋蘋果,顯然系統(tǒng)是把封面翻譯成了Cover,這個單詞也有覆蓋的意思;畫“土耳其張開翅膀”,出現(xiàn)的畫面是張開翅膀的火雞,我們都知道,Turkey是土耳其,也是火雞。
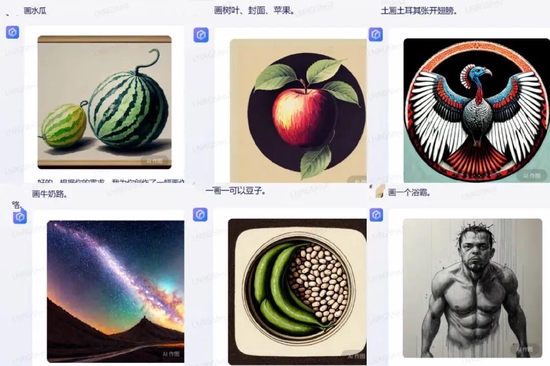
深燃截圖
對此,百度對外回應(yīng)稱,文心一言完全是百度自研的大語言模型,文生圖能力來自文心跨模態(tài)大模型ERNIE-ViLG。“在大模型訓(xùn)練中,我們使用的是全球互聯(lián)網(wǎng)公開數(shù)據(jù),符合行業(yè)慣例。”
亞洲視覺科技研發(fā)總監(jiān)陳經(jīng)也在接受媒體采訪時表示,“百度的畫圖AI采用了英文標注的開源圖片素材進行訓(xùn)練,因此需要中翻英來當prompt(提示詞)。目前,全球AI研發(fā)有開源的傳統(tǒng),特別是訓(xùn)練數(shù)據(jù)庫,不然收集圖片效率太低了。”
深燃體驗后還發(fā)現(xiàn),文心一言在單個需求描述時表現(xiàn)尚可,比如畫一幅憤怒的小孩、開心的農(nóng)民、一只很餓的流量貓,但一幅圖一旦提出多個作圖需求,AI就有點懵。
比如請文心一言“生成一幅畫,在一個下雨天,小紅在植樹,小王在看書”,系統(tǒng)生成的圖片里只有背靠樹看書的一個人;還有,“畫一幅畫,里面有大笑的年輕人、哭泣的小孩、愁容滿面的老人”,系統(tǒng)把哭泣和愁容滿面等表情集合在了一張臉上,畫出了一個小孩和老人的結(jié)合體。如下圖所示,還有一些類似的情況,系統(tǒng)同樣沒能準確完成給出的指令。
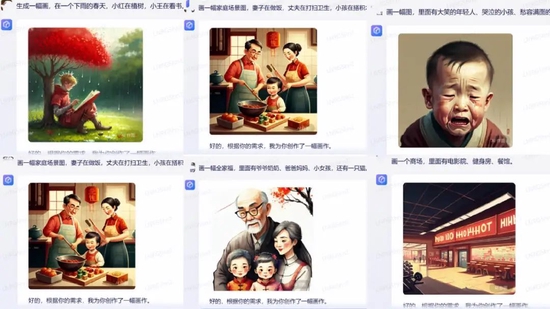
深燃截圖
深燃又把上述提示詞輸入到MidjourneyV4測試了一下,如下圖所示,即使是V4版本,表現(xiàn)也遠高出文心一言。MidjourneyV4基本能理解句子中的意思,做出的圖幾乎可以包含所有的要素。
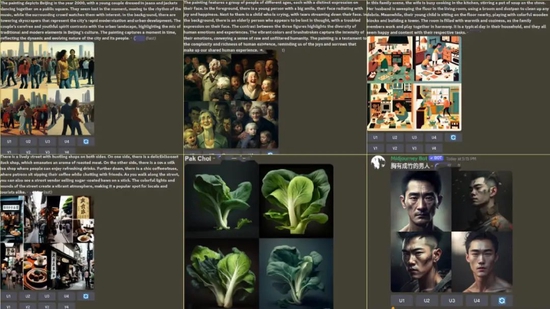
深燃體驗MidjourneyV4后截圖
深燃還測試了AI繪畫領(lǐng)域一直以來難以攻克的畫手指難的問題。在這方面,文心一言也沒能經(jīng)受住考驗。比如“畫一位30歲的女士,雙手豎起大拇指”,文心一言生成的圖片大拇指是豎起來了,但是其中一只手有7根手指;輸入“畫一個人,兩只手做點贊姿勢”時,系統(tǒng)也無法實現(xiàn)這一手部姿勢。
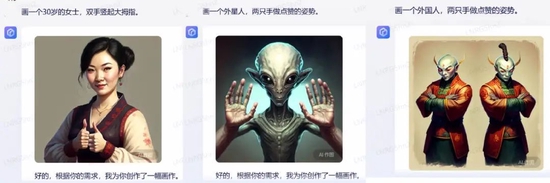
深燃截圖
Midjourney此前的版本同樣存在手指誤差的問題,最新發(fā)布的V5版本,已經(jīng)能夠正確畫出五根手指,雖然有人依舊指出其繪出的大拇指有點長,但相比以往已經(jīng)有不小的進步。有從業(yè)者評價:“Midjourney的此前版本就像是近視患者沒有戴上眼鏡,而MidjourneyV5就是戴上眼鏡后的清晰效果,4K細節(jié)拉滿”。
比如MidjourneyV5畫出的《三體》角色圖,效果被網(wǎng)友評價為幾乎要“成精了”。而文心一言畫《三體》角色時,系統(tǒng)全然不顧描述里提到的留著黑色短發(fā)、戴著眼鏡的要求,畫出了一個扎著發(fā)髻,不戴眼鏡,古風(fēng)穿著的男士。
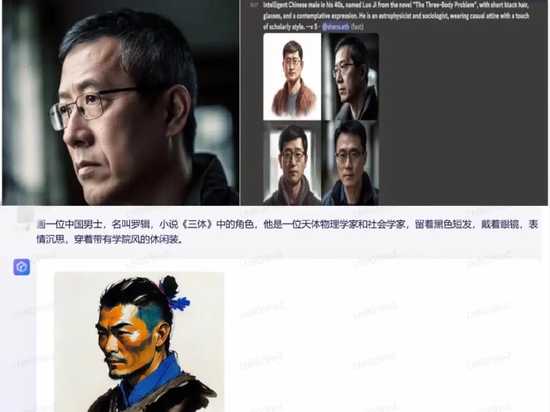
上圖為MidjourneyV5生成的三體角色圖 圖片來源 / Ai總編推書
下圖為文心一言作圖 / 深燃截圖
最近MidjourneyV5畫的一對情侶的圖片掀起了業(yè)內(nèi)一陣驚呼。作圖的提示詞是:“一對年輕的情侶穿著牛仔褲和夾克坐在樓頂上”,背景分別是2000年和2023年的北京。最后出圖的效果大大超出很多人的想象。深燃把類似表述輸入文心一言時,系統(tǒng)直接給出了毫不相關(guān)的圖片。

左圖為MidjourneyV5作圖 圖片來源 / 量子位
右為深燃對比體驗文心一言截圖
對比來看,Midjourney作圖已經(jīng)在細節(jié)上幾近完美了,文心一言還處在難以準確分辨字面意思和實際意思的初級階段。Midjourney提示詞描述越詳細,生成的圖片越精準,文心一言能理解的文字長度有限,過多描述會讓它直接報錯或者胡亂生成圖片。
AI文生圖到底有多難?
按出現(xiàn)時間來算,AI繪畫算是AI領(lǐng)域的新事物。
公開報道顯示,2021年1月,OpenAI發(fā)布了兩個連接文本與圖像的神經(jīng)網(wǎng)絡(luò):DALL?E和 CLIP。DALL?E可以基于文本直接生成圖像,CLIP能夠完成圖像與文本類別的匹配。DALL?E是基于GPT-3的120億參數(shù)版本實現(xiàn)的。
隨后在2022年,DALL·E 2、Stable Diffusion等文生圖底層大模型發(fā)布,帶動了應(yīng)用層的發(fā)展,出現(xiàn)了一大批爆款產(chǎn)品,包括Midjourney。2022年也被認為是“AI繪畫元年”。
StabilityAI的Stable Diffusion是一個開源模型,很多開發(fā)者基于這個模型開發(fā)訓(xùn)練出了更多不同的生成模型。國內(nèi)很多科技公司的AI繪畫項目也是由Stable Diffusion提供技術(shù)支撐。Midjourney是付費訂閱的,公開信息顯示,Midjourney每年的收入可能達到1億美元左右。另外,有AI繪圖業(yè)務(wù)的還有Google、Meta等公司。百度的文心一言和此前就發(fā)布的文心一格算是國內(nèi)最早的具備AI繪畫功能的大模型。
文心一言的發(fā)布和升級了的MidjourneyV5更是將AI繪畫行業(yè)推向高潮。這一次迭代是Midjourney自去年推出以來最大的更新,Midjourney也成了目前市面上最先進的AI圖像生成器之一。
熱度還在繼續(xù)。最近,行業(yè)內(nèi)又有一系列企業(yè)跟進推出AI繪畫功能。3月21日,微軟宣布,必應(yīng)搜索引擎接入了OpenAI的DALL·E模型,將AI圖像生成功能引入新版必應(yīng)和Edge瀏覽器,免費開放。就在同一天,Adobe發(fā)布AI模型Firefly,支持用文字生成圖像、藝術(shù)字體。
可以說,2023年,AI繪畫行業(yè)迎來了真正的大爆發(fā)。
調(diào)侃文心一言之余,客觀來說,AI生成圖片本身就不是一件容易實現(xiàn)的事情。系統(tǒng)的語義理解能力、充分的數(shù)據(jù)標注、細節(jié)處理、用戶的提示詞選擇,都在AI作圖中起著重要作用。

AI領(lǐng)域資深從業(yè)者郭威告訴深燃,之前AI生成圖片只需要確認風(fēng)格、物品等,用GAN(生成式對抗網(wǎng)絡(luò))生成圖片。文心一言和Midjourney這一代模型的做法是先理解自然語義,再生成圖片。把自然語言輸入到系統(tǒng)里,AI對語義的理解和人類的理解不可避免會有偏差。
“更大的難點,還是標注數(shù)據(jù)。語義比詞組的空間更大,需要大量數(shù)據(jù),而且標注難度和成本更高。”郭威說。
很多人以為,系統(tǒng)生成圖片有誤時,后臺改一個標注就能矯正系統(tǒng)了。比如生成“驢肉火燒”出了錯,只是告訴系統(tǒng)這是一道菜,而不是一頭驢就行了,但這種方式只是一對一修改而沒有一層層訓(xùn)練,修正了單個錯誤,并不會增強系統(tǒng)的理解能力,治標不治本。
也就是說,即便是有大量開源的全球數(shù)據(jù)庫圖片可以用,國內(nèi)的系統(tǒng)在中文提示詞與英文素材對應(yīng)方面還需要做大量工作。
另外,AI生成的圖片極難完善眼睛、手、腳等部位細節(jié)。一直以來,行業(yè)內(nèi)就有“AI不會畫手”的說法,很多人判斷是不是AI作圖,就看圖片中的手畫得怎么樣。“因為深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)沒有足夠的數(shù)據(jù)學(xué)習(xí)手指與手指之間的架構(gòu)邏輯,加上手指關(guān)節(jié)間特征屬于細小顆粒度,生成的手容易出錯。”資深A(yù)loT算法從業(yè)者連路詩說。目前除了MidjourneyV5,其他AI作圖產(chǎn)品細節(jié)方面的問題還沒有完全解決。
到了最終生成圖片環(huán)節(jié),用戶選擇用什么提示詞(prompt)和風(fēng)格(style)來生成想要的圖片也很重要,新用戶往往不得方法,很難找到精準的提示詞或足夠契合的風(fēng)格。
此外,目前的AI繪圖產(chǎn)品還存在一些共同的挑戰(zhàn)。
連路詩提到,一方面是時效性不夠,目前AI繪畫知識庫的更新、數(shù)據(jù)的引入不完全是實時的,如果加入實時性數(shù)據(jù),需要巨大的成本;另一方面,目前各系統(tǒng)對數(shù)據(jù)過濾的嚴謹程度不一樣,有的設(shè)置了相對嚴格的禁用詞,有的沒有,法律或道德邊界不清。
還有一個是AI繪圖帶來的版權(quán)問題。目前行業(yè)內(nèi)大部分企業(yè)不對外宣布自己用來訓(xùn)練AI的圖片來源,這樣的AI生成圖片商用時,可能存在未知的法律風(fēng)險。且目前AI作的圖也不受版權(quán)保護。
多久才能追上?
行業(yè)共性問題之外,根據(jù)多位從業(yè)者的說法,在數(shù)據(jù)、算法、算力三方面,文心一言都跟Midjourney差距不小。
數(shù)據(jù)方面,文心一言數(shù)據(jù)的數(shù)量和質(zhì)量都需要提升。
連路詩解釋,NLP(即natural language process,自然語言處理)分成幾個過程,第一步是自然語言理解,比如,實體識別,系統(tǒng)會根據(jù)專屬名詞生成自己的理解;接下來是自然語言生成,包括生成文字和圖片。大多數(shù)問題出在對自然語言的理解不準確,這時候就需要人工對句子進行數(shù)據(jù)處理、參數(shù)調(diào)整等。
“中文本身難在字與字之間沒有間距,人工分詞一方面要隔開字詞的間距,同時要界定動詞、名詞等詞性,還要標注主語、謂語、賓語,以及是否為常用詞等”,連路詩補充,“分詞需要龐大的人力投入,一般一個小組至少需要5000人。AI公司通常把這一需求外包給人力成本較低的省份的公司,另外,AI生成圖片的結(jié)果也需要人類的反饋增強學(xué)習(xí)。”
基礎(chǔ)標注工作做好之后,系統(tǒng)會將這些詞轉(zhuǎn)成向量進行計算,向量越不準確,生成的結(jié)果越模糊。“目前百度可能做了一部分工作,但還沒達到能準確理解大部分語義的程度,可以判定為不及格。”連路詩說。

陳經(jīng)也提到,大模型需要的數(shù)據(jù)庫里的“圖片是要標注的,這更加大了收集整理圖片的難度。當前也有中文標準的訓(xùn)練數(shù)據(jù),但是少很多。由于發(fā)布時間倉促,百度對于畫圖AI的中文輸入詞還沒完全搞定,后續(xù)應(yīng)該會根據(jù)用戶反饋,把中文的提示詞與英文的訓(xùn)練素材更好的對應(yīng)上。”
第二大差距是算法。
算法方面,各公司在底層大模型的使用層數(shù)上有差別。連路詩認為,以文心一言目前在算法方面的表現(xiàn)來看,有可能與Midjourney等模型的深度神經(jīng)網(wǎng)絡(luò)的層數(shù)有十倍左右的差距。
“AI生成圖片不準確還有一種可能性,該系統(tǒng)的底層架構(gòu)不是深度神經(jīng)網(wǎng)絡(luò),也沒有根據(jù)底層Vector(向量)一點點像素級生成圖片,而是系統(tǒng)先用搜索引擎匹配知識圖譜,再生成圖像,也可以理解為拼湊貼圖。神經(jīng)網(wǎng)絡(luò)在對圖片進行計算的時候,本來就有圖片的旋轉(zhuǎn)、切割、拼湊,這樣的系統(tǒng)生成的圖片有可能是顆粒度很粗的片狀圖片拼湊出來的。”連路詩做了這樣的推測。不過,文心一言屬于哪種技術(shù)還不清楚。
第三,算力上的差距。OpenAI號稱自己的模型是千億規(guī)模參數(shù),也就是每次計算的時候擁有1000張以上顯卡分布式計算的算力。百度與國外幾家主要科技企業(yè)的算力差距同樣不小。
當然,百度和Midjourney目前的發(fā)展程度不一,與其發(fā)展階段也有關(guān)系。
Midjourney于2022年3月首次面世,目前已經(jīng)迭代到了第五代。百度文心一言所具備的AI作圖功能,即文心一格,雖然在2022年8月就推出了,但目前沒有看到相關(guān)的升級迭代信息。而在AI領(lǐng)域,變化幾乎是以天為單位的。
國內(nèi)AI繪圖多久能趕上國際水平?郭威對此比較樂觀。在他看來,“數(shù)據(jù)方面雖然有差異,但最多也只有半年左右的差距,中文類的數(shù)據(jù)國內(nèi)比國外更多,拼命補一下能趕上。”
至于算法差異,他表示,OpenAI等幾家機構(gòu)比Google、Facebook、百度等高出半年到一年的水平,之前因為不確定性大,各企業(yè)沒有重點布局,現(xiàn)在驗證這條路是有前途的,針對性追趕,很快也能趕上。雖然OpenAI沒開源,但從OpenAI出來的一些人很快也會把技術(shù)思路共享到小圈子里,頭部公司很容易跟進。
“算力的差距就很難彌補了,短期內(nèi)難追上去,但是用一年多時間把國內(nèi)系統(tǒng)做到國外80分或90分以上的程度是可能的。”郭威說。
無論如何,接下來,AI繪畫將會走到舞臺中央大放異彩是確定的事實,對各公司來說,拼的是速度。行業(yè)規(guī)則是公開的,所有選手都在往前跑,這時候,競爭是最大的動力,拿結(jié)果說話才是硬道理。
*題圖及文中配圖來源于pexels。應(yīng)受訪者要求,文中郭威為化名。

(聲明:本文僅代表作者觀點,不代表新浪網(wǎng)立場。)

作者簡介




