

真·拿嘴做視頻!Meta“AI導(dǎo)演”一句話搞定視頻素材,網(wǎng)友:我已跟不上AI發(fā)展速度

歡迎關(guān)注“新浪科技”的微信訂閱號(hào):techsina
文 | 魚羊 Alex
來(lái)源:量子位
畫家執(zhí)筆在畫布上戳戳點(diǎn)點(diǎn),形成手繪作品獨(dú)有的筆觸。
你以為這是哪部紀(jì)錄片的畫面?
No,No,No!
視頻里的每一幀,都是AI生成的。
還是你告訴它,來(lái)段“畫筆在畫布上的特寫”,它就能直接整出畫面的那種。
不僅能無(wú)中生畫筆,按著馬頭喝水也不是不可以。
同樣是一句“馬兒喝水”,這只AI就拋出了這樣的畫面:

好家伙,這是以后拍視頻真能全靠一張嘴的節(jié)奏啊……
不錯(cuò),那廂一句話讓AI畫畫的Text to Image正搞得風(fēng)生水起,這廂Meta AI的研究人員又雙叒給生成AI來(lái)了個(gè)超進(jìn)化。
這回是真能“用嘴做視頻”了:
AI名為Make-A-Video,直接從DALL·E、Stable Diffusion搞火的靜態(tài)生成飛升動(dòng)態(tài)。
給它幾個(gè)單詞或幾行文字,就能生成這個(gè)世界上其實(shí)并不存在的視頻畫面,掌握的風(fēng)格還很多元。
不僅紀(jì)錄片風(fēng)格能hold住,整點(diǎn)科幻效果也沒(méi)啥問(wèn)題。

兩種風(fēng)格混合一下,機(jī)器人在時(shí)代廣場(chǎng)蹦迪的畫面好像也沒(méi)啥違和感。

文藝小清新的動(dòng)畫風(fēng)格,看樣子Make-A-Video也把握住了。

這么一波操作下來(lái),那真是把不少網(wǎng)友都看懵了,連評(píng)論都簡(jiǎn)化到了三個(gè)字母:
而大佬LeCun則意味深長(zhǎng)地表示:該來(lái)的總是會(huì)來(lái)的。

畢竟一句話生成視頻這事兒,之前就有不少業(yè)內(nèi)人士覺(jué)得“快了快了”。只不過(guò)Meta這一手,確實(shí)有點(diǎn)神速:
比我想象中快了9個(gè)月。
甚至還有人表示:我已經(jīng)有點(diǎn)適應(yīng)不了AI的進(jìn)化速度了……

文本圖像生成模型超進(jìn)化版
你可能會(huì)覺(jué)得Make-A-Video是個(gè)視頻版的DALL·E。
實(shí)際上,差不多就是這么回事兒

前面提到,Make-A-Video是文本圖像生成(T2I)模型的超進(jìn)化,那是因?yàn)檫@個(gè)AI工作的第一步,其實(shí)還是依靠文本生成圖像。
從數(shù)據(jù)的角度來(lái)說(shuō),就是DALL·E等靜態(tài)圖像生成模型的訓(xùn)練數(shù)據(jù),是成對(duì)的文本-圖像數(shù)據(jù)。
而Make-A-Video雖然最終生成的是視頻,但并沒(méi)有專門用成對(duì)的文本-視頻數(shù)據(jù)訓(xùn)練,而是依然靠文本-圖像對(duì)數(shù)據(jù),來(lái)讓AI學(xué)會(huì)根據(jù)文字復(fù)現(xiàn)畫面。
視頻數(shù)據(jù)當(dāng)然也有涉及,但主要是使用單獨(dú)的視頻片段來(lái)教給AI真實(shí)世界的運(yùn)動(dòng)方式。
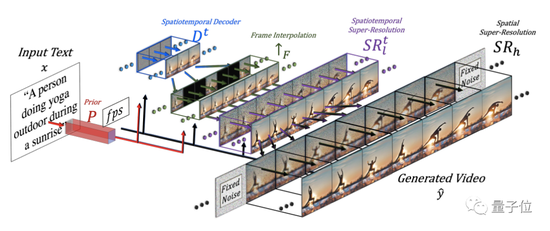
具體到模型架構(gòu)上,Make-A-Video主要由三部分組成:
-
文本圖像生成模型P
-
時(shí)空卷積層和注意力層
-
用于提高幀率的幀插值網(wǎng)絡(luò)和兩個(gè)用來(lái)提升畫質(zhì)的超分網(wǎng)絡(luò)
整個(gè)模型的工作過(guò)程是醬嬸的:
首先,根據(jù)輸入文本生成圖像嵌入。
然后,解碼器Dt生成16幀64×64的RGB圖像。
插值網(wǎng)絡(luò)↑F會(huì)對(duì)初步結(jié)果進(jìn)行插值,以達(dá)到理想幀率。
接著,第一重超分網(wǎng)絡(luò)會(huì)將畫面的分辨率提高到256×256。第二重超分網(wǎng)絡(luò)則繼續(xù)優(yōu)化,將畫質(zhì)進(jìn)一步提升至768×768。
基于這樣的原理,Make-A-Video不僅能根據(jù)文字生成視頻,還具備了以下幾種能力。
將靜態(tài)圖像轉(zhuǎn)成視頻:

根據(jù)前后兩張圖片生成一段視頻:

根據(jù)原視頻生成新視頻:

刷新文本視頻生成模型SOTA
其實(shí),Meta的Make-A-Video并不是文本生成視頻(T2V)的首次嘗試。
比如,清華大學(xué)和智源在今年早些時(shí)候就推出了他們自研的“一句話生成視頻”AI:CogVideo,而且這是目前唯一一個(gè)開源的T2V模型。
更早之前,GODIVA和微軟的“女媧”也都實(shí)現(xiàn)過(guò)根據(jù)文字描述生成視頻。
不過(guò)這一次,Make-A-Video在生成質(zhì)量上有明顯的提升。
在MSR-VTT數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果顯示,在FID(13.17)和CLIPSIM(0.3049)兩項(xiàng)指標(biāo)上,Make-A-Video都大幅刷新了SOTA。

此外,Meta AI的團(tuán)隊(duì)還使用了Imagen的DrawBench,進(jìn)行人為主觀評(píng)估。
他們邀請(qǐng)測(cè)試者親身體驗(yàn)Make-A-Video,主觀評(píng)估視頻與文本之間的邏輯對(duì)應(yīng)關(guān)系。
結(jié)果顯示,Make-A-Video在質(zhì)量和忠實(shí)度上都優(yōu)于其他兩種方法。

One More Thing
有意思的是,Meta發(fā)布新AI的同時(shí),似乎也拉開了T2V模型競(jìng)速的序幕。
Stable Diffusion的母公司StabilityAI就坐不住了,創(chuàng)始人兼CEO Emad放話道:
我們將發(fā)布一個(gè)比Make-A-Video更好的模型,大家都能用的那種!
而就在前幾天,ICLR網(wǎng)站上也出現(xiàn)了一篇相關(guān)論文Phenaki。
生成效果是這樣的:
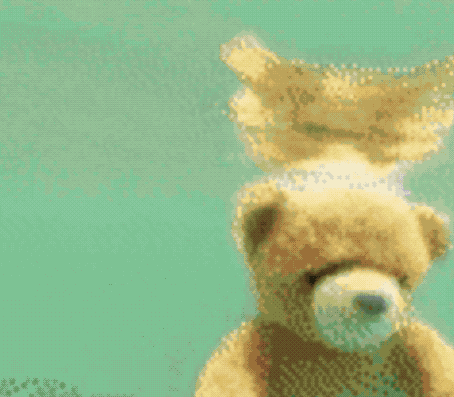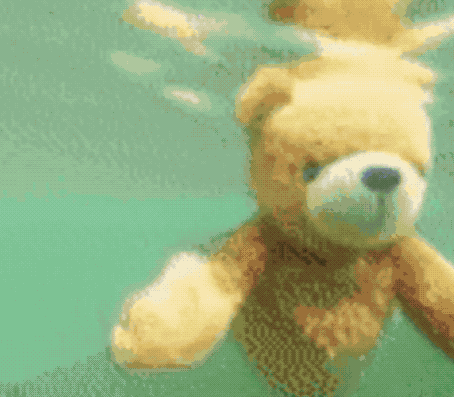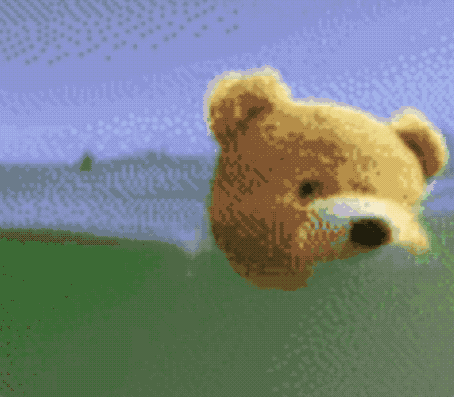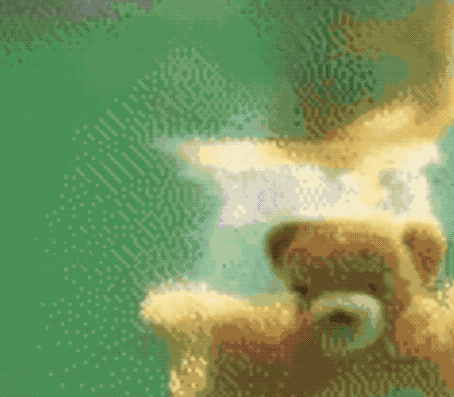
對(duì)了,雖然Make-A-Video尚未公開,但Meta AI官方也表示,準(zhǔn)備推出一個(gè)Demo讓大家可以實(shí)際上手體驗(yàn),感興趣的小伙伴可以蹲一波了~

(聲明:本文僅代表作者觀點(diǎn),不代表新浪網(wǎng)立場(chǎng)。)

作者簡(jiǎn)介

量子位
推薦閱讀




新聞熱榜
- 01字節(jié)身上看不到蘋果光環(huán)
- 02在美國(guó),拼多多對(duì)SHEIN希音“砍了一刀”...
- 03國(guó)慶節(jié)來(lái)了,國(guó)慶檔“難產(chǎn)”了
- 04黃光裕拯救國(guó)美的最后一張牌是賣樓嗎?
- 05萬(wàn)億規(guī)模的儲(chǔ)能行業(yè):迎來(lái)歷史性拐點(diǎn)?
- 06減薪、關(guān)店、巨虧,國(guó)美“臨崖”誰(shuí)來(lái)救?
- 07供應(yīng)商battle東方甄選,“6元玉米”再起波瀾...
- 08“擎天柱”一定會(huì)讓你失望,蘋果OV們也是
- 09越貴越虧,共享充電寶注定賺不了錢?
- 10點(diǎn)1個(gè)菜要10套餐具,誰(shuí)給外賣商家評(píng)評(píng)理?...