

Jeff Dean萬字長文:2020谷歌10大領域AI技術發展

歡迎關注“創事記”的微信訂閱號:sinachuangshiji
文/QJP、小勻
來源: 新智元(ID:AI_era)
Jeff Dean發了一篇幾萬字長文,回顧了這一年來谷歌在各個領域的成就與突破,并展望了2021年的工作目標。
“當我20多年前加入谷歌的時候,只想弄清楚如何真正開始使用電腦在網絡上提供高質量和全面的信息搜索服務。時間快進到今天,當面對更廣泛的技術挑戰時,我們仍然有著同樣的總體目標,那就是組織全世界的信息,使其普遍可獲取和有用。
2020年,隨著世界被冠狀病毒重塑,我們看到了技術可以幫助數十億人更好地交流,理解世界和完成任務。我為我們所取得的成就感到驕傲,也為即將到來的新的可能性感到興奮。”
Google Research 的目標是解決一系列長期而又重大的問題,從預測冠狀病毒疾病的傳播,到設計算法、自動翻譯越來越多的語言,再到減少機器學習模型中的偏見。
本文涵蓋了今年的關鍵亮點。
新冠病毒和健康
COVID-19的影響給人們的生活帶來了巨大的損失,世界各地的研究人員和開發人員聯合起來開發工具和技術,以幫助公共衛生官員和政策制定者理解和應對這場流行病。
蘋果和谷歌在2020年合作開發了暴露通知系統(ENS) ,這是一種支持藍牙的隱私保護技術,如果人們暴露在其他檢測呈陽性的人群中,可以通知他們。
ENS 補充了傳統的接觸者追蹤工作,并由50多個國家、州和地區的公共衛生當局部署,以幫助遏制感染的傳播。
在流感大流行的早期,公共衛生官員表示,他們需要更全面的數據來對抗病毒的快速傳播。我們的社區流動性報告,提供了對人口流動趨勢的匿名追蹤,不僅幫助研究人員了解政策的影響,如居家指令和社會距離,同時還進行了經濟影響的預測。
我們自己的研究人員也探索了用這種匿名數據來預測COVID-19的傳播,用圖神經網絡代替傳統的基于時間序列的模型。
冠狀病毒疾病搜索趨勢癥狀允許研究人員探索時間或癥狀之間的聯系,比如嗅覺缺失---- 嗅覺缺失有時是病毒的癥狀之一。為了進一步支持更廣泛的研究社區,我們推出了谷歌健康研究應用程序,以提供公眾參與研究的方式。
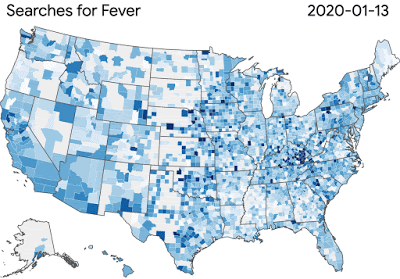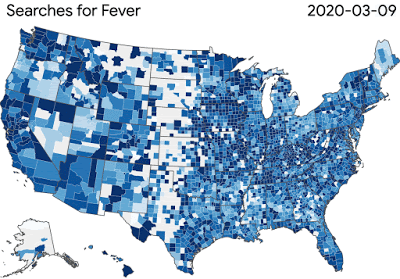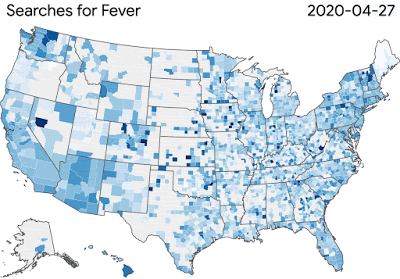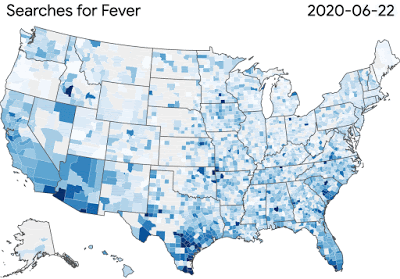 圖:COVID-19搜索趨勢正在幫助研究人員研究疾病傳播和癥狀相關搜索之間的聯系
圖:COVID-19搜索趨勢正在幫助研究人員研究疾病傳播和癥狀相關搜索之間的聯系谷歌的團隊正在為更廣泛的科學界提供工具和資源,這些科學界正在努力解決病毒對健康和經濟的影響。
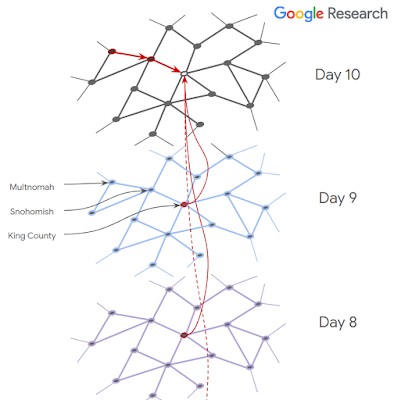 圖:一個模擬新冠病毒擴散的時空圖
圖:一個模擬新冠病毒擴散的時空圖我們還致力于幫助識別皮膚疾病,幫助檢測老年黃斑變性(在美國和英國是導致失明的主要原因,在全世界是第三大致盲原因) ,以及潛在的新型非侵入性診斷(例如,能夠從視網膜圖像中檢測出貧血的跡象)。
 圖:深度學習模型從視網膜圖像中量化血紅蛋白水平。血紅蛋白水平是檢測貧血的一項指標
圖:深度學習模型從視網膜圖像中量化血紅蛋白水平。血紅蛋白水平是檢測貧血的一項指標今年,同樣的技術如何可以窺視人類基因組,也帶來了令人興奮的演示。谷歌的開源工具DeepVariant,使用卷積神經網絡基因組測序數據識別基因組變異,并在今年贏得了FDA的4個類別中的3個類別的最佳準確性的挑戰。丹納-法伯癌癥研究所領導的一項研究使用同樣的工具,在2367名癌癥患者中,將導致前列腺癌和黑色素瘤的遺傳變異的診斷率提高了14% 。
天氣、環境和氣候變化
機器學習能幫助我們更好地了解環境,并幫助人們在日常生活中以及在災難情況下做出有用的預測。
對于天氣和降水預報,像 NOAA 的 HRRR 這樣基于計算物理的模型一直占據著主導地位。然而,我們已經能夠證明,基于ML的預報系統能夠以更好的空間分辨率預測當前的降水量(“西雅圖的本地公園是不是在下雨? ”而不僅僅是“西雅圖在下雨嗎? ”)它能夠產生長達8小時的短期預報,比 HRRR 準確得多,并且能夠以更高的時間和空間分辨率更快地計算預報。

我們還開發了一種改進的技術,稱為 HydroNets,它使用一個神經網絡來建模真實的河流系統,以更準確地了解上游水位對下游洪水的相互作用,做出更準確的水位預測和洪水預報。利用這些技術,我們已經將印度和孟加拉國的洪水警報覆蓋范圍擴大了20倍,幫助在25萬平方公里內更好地保護了2億多人。
可訪問性(Accessibility)
機器學習繼續為提高可訪問性提供了驚人的機會,因為它可以學會將一種感官輸入轉化為其他輸入。舉個例子,我們發布了 Lookout,一個 Android 應用程序,可以幫助視力受損的用戶識別包裝食品,無論是在雜貨店還是在他們家的廚房櫥柜里。

Lookout 背后的機器學習系統演示了一個功能強大但緊湊的機器學習模型,可以在有近200萬個產品的手機上實時完成這一任務。
同樣,使用手語交流的人很難使用視頻會議系統,因為即使他們在手語,基于音頻的揚聲器檢測系統也檢測不到他們在主動說話。為視頻會議開發實時自動手語檢測,我們提出了一種實時手語檢測模型,并演示了如何利用該模型為視頻會議系統提供一種識別手語者為主動說話者的機制。
機器學習在其他領域的應用
2020年,我們與 FlyEM 團隊合作,發布了果蠅半腦連接體,這是一種大型突觸分辨率圖譜的大腦連接,重建使用大規模機器學習模型應用于高分辨率電子顯微鏡成像的腦組織。這些連接體信息將幫助神經科學家進行各種各樣的研究,幫助我們更好地理解大腦是如何運作的。
負責任的人工智能
為了更好地理解語言模型的行為,我們開發了語言可解釋性工具(LIT) ,這是一個可以更好地解釋語言模型的工具包,使得交互式探索和分析語言模型的決策成為可能。
我們開發了在預訓練語言模型中測量性別相關性的技術,以及在谷歌翻譯中減少性別偏見的可擴展技術。
為了幫助非專業人員解釋機器學習結果,我們擴展了2019年引入的 TCAV 技術,現在提供了一套完整而充分的概念。我們可以說“毛”和“長耳朵”是“兔子”預測的重要概念。通過這項工作,我們還可以說,這兩個概念足以充分解釋預測; 您不需要任何其他概念。
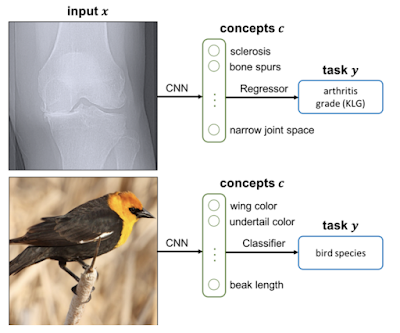
概念瓶頸模型是一種技術,通過訓練模型,使其中一層與預先定義的專家概念(例如,“骨刺呈現” ,或“翅膀顏色” ,如下所示)保持一致,然后再對任務做出最終預測,這樣我們不僅可以解釋這些概念,還可以動態地打開/關閉這些概念。
自然語言理解
更好地理解語言是我們今年看到相當大進展的一個領域。谷歌和其他公司在這個領域的大部分工作現在都依賴于transformer,這是一種特殊風格的神經網絡模型,最初是為了解決語言問題而開發的(但是越來越多的證據表明,它們對圖像、視頻、語音、蛋白質折疊以及其他各種各樣的領域也很有用)。
在2020年,我們描述了 Meena,一個對話機器人,可以聊任何事情。
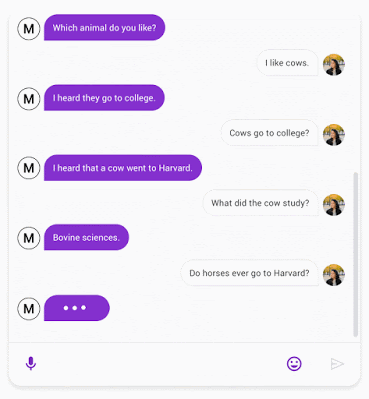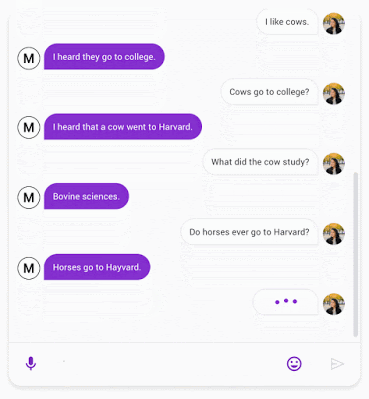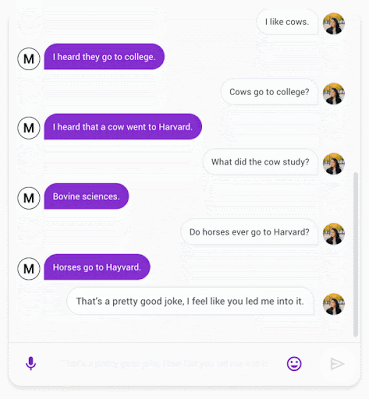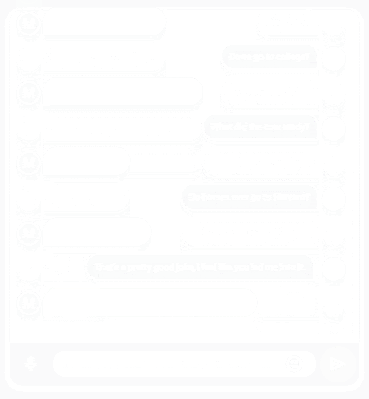
機器學習算法
谷歌仍向無監督學習方向大力發展,例如2020年開發的SimCLR,推進自監督和半監督學習技術。
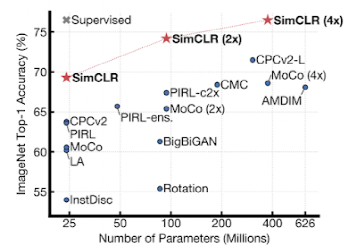 使用不同的自監督方法(在ImageNet上預訓練)學習的表示形式,對ImageClass的分類器進行ImageNet top-1準確性訓練。灰色十字表示受監管的ResNet-50。
使用不同的自監督方法(在ImageNet上預訓練)學習的表示形式,對ImageClass的分類器進行ImageNet top-1準確性訓練。灰色十字表示受監管的ResNet-50。強化學習
強化學習通過學習其他主體以及改進探索,谷歌已經提高了RL算法的效率。
他們今年的主要重點是離線RL,它僅依賴于固定的,先前收集的數據集(例如先前的實驗或人類演示),從而將RL擴展到了無法即時收集訓練數據的應用程序中。研究人員為RL引入了對偶方法,開發了改進的算法以用于非策略評估,此外,他們正在與更廣泛的社區合作,通過發布開源基準測試數據集和Atari的DQN數據集來解決這些問題。
 使用DQN重播數據集的Atari游戲的離線RL
使用DQN重播數據集的Atari游戲的離線RL另一個研究方向是通過學徒制學習(apprenticeship learning),向其他代理學習,從而提高了樣本效率。
需要注意的是,將RL擴展到復雜的實際問題來說是一個重要的挑戰。
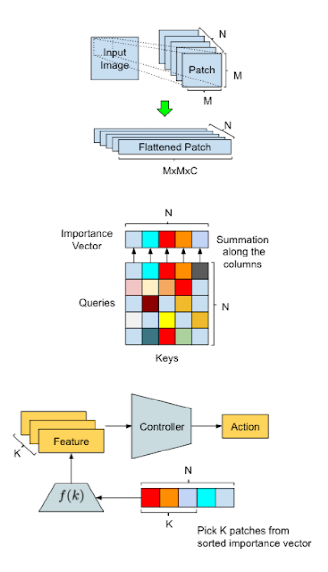
概述我們的方法并說明AttentionAgent中的數據處理流程。頂部:輸入轉換 - 一個滑動窗口將輸入圖像分割成更小的補丁,然后將它們 "扁平化",以便將來處理。中間。補丁選舉 - 修改后的自我注意力模塊在補丁之間進行投票,以生成補丁重要性向量。底部:動作生成--AttentionAgent在補丁之間進行投票,生成補丁的重要性向量。行動生成--AttentionAgent選擇重要性最高的補丁,提取相應的特征,并基于這些特征做出決策。
AutoML
毫無疑問,這是一個非常活躍和令人興奮的研究領域。
我在AutoML-Zero中:不斷學習的代碼,我們采用了另一種方法,即為演化算法提供一個由非常原始的運算(例如加法,減法,變量賦值和矩陣乘法)組成的搜索空間,以查看是否有可能從頭開始發展現代ML算法。
但是,有用的算法實在太少了。如下圖所示,該系統重塑了過去30年中許多最重要的ML發現,例如線性模型,梯度下降,校正線性單位,有效的學習率設置和權重初始化以及梯度歸一化。

更好地理解ML算法和模型
隨著神經網絡被做得更寬更深,它們往往訓練得更快,泛化得更好。這是深度學習中的一個核心奧秘,因為經典學習理論表明,大型網絡應該超配更多。
在無限寬的限制下,神經網絡呈現出驚人的簡單形式,并由神經網絡高斯過程(NNGP)或神經切線核(NTK)來描述。谷歌研究人員從理論和實驗上研究了這一現象,并發布了Neural Tangents,這是一個用JAX編寫的開源軟件庫,允許研究人員構建和訓練無限寬度的神經網絡。
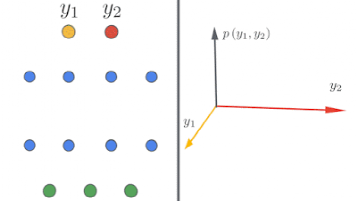 左:該示意圖顯示了深層神經網絡如何隨著簡單的輸入/輸出圖變得無限寬而引發它們。右圖:隨著神經網絡寬度的增加,我們看到在網絡的不同隨機實例上的輸出分布變為高斯分布。
左:該示意圖顯示了深層神經網絡如何隨著簡單的輸入/輸出圖變得無限寬而引發它們。右圖:隨著神經網絡寬度的增加,我們看到在網絡的不同隨機實例上的輸出分布變為高斯分布。機器感知
對我們周圍世界的感知--對視覺、聽覺和多模態輸入的理解、建模和行動--仍然是一個具有巨大潛力的研究領域,對我們的日常生活大有裨益。
2020年,深度學習使3D計算機視覺和計算機圖形學更緊密地結合在一起。CvxNet、3D形狀的深度隱含函數、神經體素渲染和CoReNet是這個方向的幾個例子。此外,他們關于將場景表示為神經輻射場的研究(又名NeRF,也可參見本篇博文)是一個很好的例子,說明Google Research的學術合作如何刺激神經體量渲染領域的快速進展。
在與加州大學伯克利分校合作的《學習因素化和重新點亮城市》中,谷歌提出了一個基于學習的框架,用于將戶外場景分解為時空變化的照明和永久場景因素。這能為任何街景全景改變照明效果和場景幾何,甚至將其變成全天的延時視頻。

2020年,他們還使用神經網絡進行媒體壓縮的領域不斷擴大,不僅在學習的圖像壓縮方面,而且在視頻壓縮的深層方法,體壓縮以及深不可知的圖像水印方面都取得了不錯的成績。

第一行:沒有嵌入消息的封面圖像。第二行:來自HiDDeN組合失真模型的編碼圖像。第三行:來自我們模型的編碼圖像。第四行:HiDDeN組合模型的編碼圖像和封面圖像的歸一化差異。第五行:模型的歸一化差異
通過開源解決方案和數據集與更廣泛的研究社區進行互動是另一個重要方面。2020年,谷歌在MediaPipe中開源了多種新的感知推理功能和解決方案,例如設備上的面部,手和姿勢預測,實時身體姿勢跟蹤,實時虹膜跟蹤和深度估計以及實時3D對象檢測。

“最后,展望這一年,我特別熱衷于構建更多通用機器學習模型的可能性,這些模型可以處理各種模式,并且可以通過很少的培訓示例來自動學習完成新任務。
該領域的進步將為人們提供功能更強大的產品,為全世界數十億人帶來更好的翻譯,語音識別,語言理解和創作工具。
這種探索和影響使我們對工作感到興奮!”


作者簡介

新智元
作者文章

推薦閱讀
- “工具人”釘釘
-

- 被釘釘寄予厚望的釘釘宜搭平臺,在“云釘一體”戰略后,該平臺的出現做實了釘釘“工具人”的定位。詳細>>
- “印鈔機”悅刻,為何著急上市
-

- 中國煙草是沒機會了,但它的“替換股”電子煙龍頭老大——霧芯科技即將赴美上市。詳細>>
- 快手通過聆訊:9個月營收407億 需平衡主播與平臺關系
-

- 1月16日報道 快手科技通過港交所上市聆訊,并更新招股書,預計2月初在港交所上市。詳細>>
- Playtika上市:市值130億美元 史玉柱資本騰挪數年
-

- 以色列棋牌游戲Playtika(股票代碼為“PLTK”)昨日在美國納斯達克上市,發行價為27美元,之前發行區間為22美元到24美元。詳細>>