




8 月 10 日,寧波高架發生一起小鵬 P7 追尾致人死亡的事故。
發生事故的原因主要有兩點,一是被撞車輛是靜止的。二是被撞人員站在車后。離車很近的地方是水泥護欄,還有一個人蹲著,離被撞車很近。

即便這次事故,車主沒有開啟 NGP 功能,AEB 系統也應該起作用,但上述的原因讓 AEB 系統失效了。
有人可能會說時速 80 公里超出了 AEB 的上限,早期的 AEB 系統的確如此,上限一般是時速 60 公里。
2020 年后的新一代 AEB 則不然,在速度上限內是剎停,也就是剎車力度會達到最大,超過上限則是減速。
以特斯拉為例,如減速 50 公里,那么系統則在時速 110 公里情況下觸發 AEB,最多減速至時速 60 公里。
有些如奔馳,AEB 速度上限高達時速 110 公里。
還有些車型把這一部分單獨抽出,稱之為碰撞緩解,實際就是加強版的 AEB。
只減速不剎停,這樣做也是為了避免高速情況下后車的追尾。

蔚來和特斯拉都發生過撞靜止車輛的事故,特斯拉的次數尤其多,多次撞向白色卡車和消防車。
在封閉場地測試時,我們可以看到靜止車輛或行人都能觸發 AEB,即使最廉價的車型都能做到剎停。
但為何在真實道路上,遇到靜止目標時,AEB 不行了?
01
分離動態目標的常見三種方法
 圖像識別流程
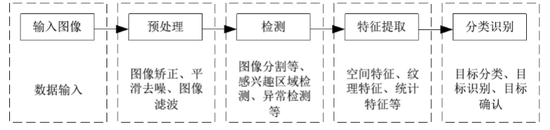
圖像識別流程 我們先從先從圖像識別流程和運用目標分離方法來看看自動駕駛系統是如何識別和處理障礙物的。
上圖為機器視覺的處理流程,其主要過程為輸入圖像,對輸入的圖像進行預處理。
預處理之后的圖像,再對其進行 ROI 區域檢測或者異常檢測,對已經檢測出來的區域進行特征提取分類識別等。
系統對運動目標是需要特別重視的,會優先處理運動目標,因此第一步要將運動目標從背景圖中分割出來,有些系統為了避免誤動作,干脆將靜態目標過濾掉。
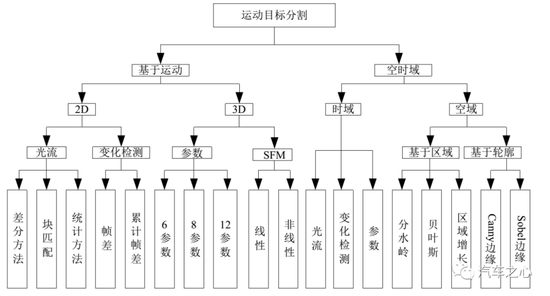 運動目標分離方法
運動目標分離方法 分離動態目標最常見的三種方法是幀差法、光流法和背景差法。
考慮到實時性和成本,目前業內大多采用幀差法。這種方法對運算資源消耗最少,最容易達到實時性,但缺點準確度不高。
所謂幀差法,即檢測相鄰幀之間的像素變化。
幀差法的基本思想是:運動目標視頻中,可以根據時間提取出系列連續的序列圖像,在這些相鄰的序列圖像中,背景的像素變化較小,而運動目標的像素變化較大,利用目標運動導致的像素變化差,則可以分割出運動目標。
幀差法可以分為兩幀差分法與三幀差分法。
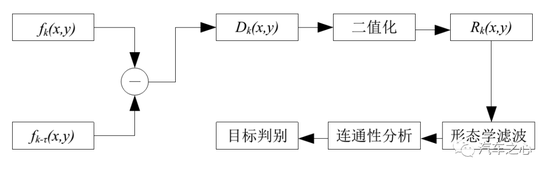
兩幀差分法
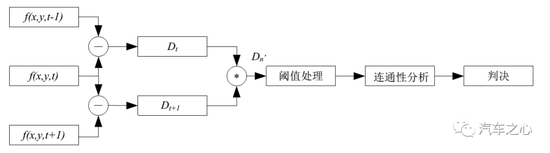
三幀差分法
兩幀差分法就是將視頻采集到時序列圖像的相鄰兩幀圖像進行差分。
對相鄰的兩幀圖像進行差分,可以在任何具有復雜的圖像特征 (例如,紋理特征、灰度均值等) 上進行。
因此,只要明顯區別與背景的運動物體均可檢測出來。
根據給定的閾值,對差分結果二值化:
若差值圖像大于給定閾值,則認為該像素點是前景目標中的點,并將該像素點作為運動目標的一部分;
若差值圖像小于給定閾值,則認為該像素點屬于背景目標點,從而將運動目標從背景目標中分割出來。
圖像進行閾值分割之后,通常都帶有噪聲,因此需要使用形態學濾波的方法對噪聲進行衰減。衰減噪聲后得到的圖像運動目標會存在一些空洞,需要進行連通性處理,最后才得到判別目標。
閾值設定太低,檢測不到目標。設定太高,會被檢測為兩個分開的物體。
同時對于比較大、顏色一致的運動目標,如白色大貨車,幀間差分法會在目標內部產生空洞,無法完整分割提取運動目標。
分離出動態目標,對目標進行識別并探測其距離,如果動態目標都已經處理完畢,這才開始處理靜態目標。而在封閉場地測試場里,只有一個目標,很輕松就能分離出背景,只處理靜態目標。
而在真實道路上,靜止目標比移動目標的檢測要晚大約 2 到 4 秒,這次發生事故時,小鵬 P7 的時速是 80 公里,也就是 44 到 88 米。
光流法是利用圖像序列中像素在時間域上的變化以及相鄰幀之間的相關性,來找到上一幀跟當前幀之間存在的對應關系,從而計算出相鄰幀之間物體的運動信息。
研究光流場的目的就是為了從圖片序列中近似得到不能直接得到的運動場,其本質是一個二維向量場,每個向量表示場景中該點從前一幀到后一幀的位移。對光流的求解,即輸入兩張連續圖象(圖象像素),輸出二維向量場。
除了智能駕駛,體育比賽中各種球類的軌跡預測,軍事行動中的目標軌跡預測都能用到。
光流場是運動場在二維圖像平面上的投影。因為立體雙目和激光雷達都是 3D 傳感器,而單目或三目是 2D 傳感器,所以單目或三目的光流非常難做。
光流再分為稀疏和稠密(Dense)兩種,稀疏光流對部分特征點進行光流解算,稠密光流則針對的是所有點的偏移。
最常見的光流算法即 KLT 特征追蹤,早期的光流算法都是稀疏光流,手工模型或者說傳統算法。
2015 年有人提出深度學習光流法,在 CVPR2017 上發表改進版本 FlowNet2.0,成為當時最先進的方法。截止到現在,FlowNet 和 FlowNet2.0 依然是深度學習光流估計算法中引用率最高的論文。
傳統算法計算資源消耗少,實時性好,效果比較均衡,但魯棒性不好。
深度學習消耗大量的運算資源,魯棒性好,但容易出現極端,即某個場景非常差,但無法解釋,與訓練數據集關聯程度高。
即使強大的英偉達 Orin 芯片,在 FlowNet2.0 上也無法做到實時性,畢竟 Orin 不能只做光流這一件事。
光流法比幀差法準確度要高,但會大量消耗運算資源。
02
4D 毫米波雷達會漏檢嗎?
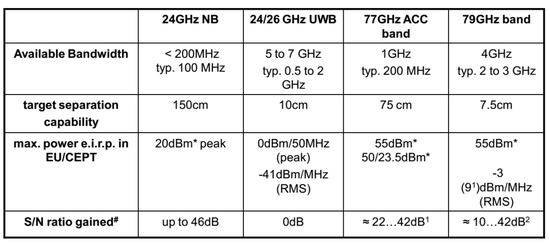
四種毫米波雷達性能對比
目前典型的 76GHz 毫米波雷達的帶寬是 500GHz
大部分毫米波雷達的帶寬是 500MHz,也就是 0.5GHz,目標分離度是 150 厘米。
也就是說,1.5 米內的兩個目標,毫米波雷達會識別成一個——這次小鵬 P7 發生的事故也是如此,車輛很靠近水泥護欄,很有可能會被認為是一個目標。
特斯拉最近也在研發毫米波雷達,其帶寬應該是 500MHz,全球最先進的 4D 毫米波雷達即大陸汽車的 ARS540,也是 500MHz。
博世還未量產的 4D 毫米波雷達是 867MHz,比特斯拉和大陸都要好,缺點可能是功耗太高,射頻輸出功率達到驚人的 5495 毫瓦,整體功耗估計有 30-60 瓦。
ARS540 的射頻輸出功率是 1143 毫瓦,整體功耗大概 10 瓦。這對一個一直常開的傳感器來說功耗似乎太高了。
再有就是雖然 60GHz 以上波段無需牌照,但超過 1GHz 的帶寬,可能還是會有監管,在沒有明確政策出臺前,業界不敢研發這種高寬帶雷達,萬一禁止就白研發了。
因為目標分離度的問題,我估計廠家為了避免誤動作,未必敢將 4D 毫米波雷達單獨做為 AEB 的觸發條件,肯定要以視覺為準。
除了靜止目標原因外,這次小鵬 P7 在事故發生前,被撞者走到車尾。這就形成了一個很罕見的目標,既像車又像行人,在這種情況下,就會出現漏檢。
03
基于單目、三目的機器視覺,有著天然缺陷
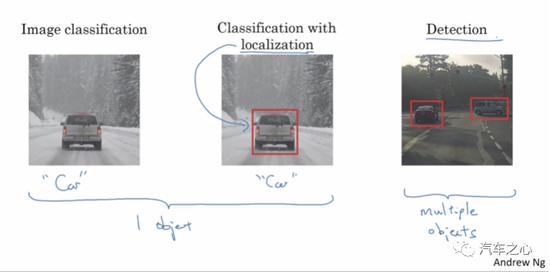
基于單目或三目的機器視覺,有著天然的無法改變的缺陷,這個缺陷表現為識別或者說分類與探測是一體的,無法分割,特別是基于深度學習的機器視覺。
也就是說,如果系統無法將目標分類(也可以通俗地說是識別),也就無法探測。
換句話說,如果系統無法識別目標,就認為目標不存在。車輛會認為前方無障礙物,會不減速直接撞上去。
什么狀況下無法識別?
有兩種情況:
第一種是訓練數據集無法完全覆蓋真實世界的全部目標,能覆蓋 10% 都已經稱得上優秀了,更何況真實世界每時每刻都在產生著新的不規則目標。
深度學習這種窮舉法有致命缺陷。特斯拉多次事故都是如此,比如在中國兩次在高速公路上追尾掃地車(第一次致人死亡),在美國多次追尾消防車。
第二種是圖像缺乏紋理特征,比如在攝像頭前放一張白紙,自然識別不出來是什么物體。某些底盤高的大貨車側面,就如同白紙,基于深度學習的機器視覺此時就如同盲人,不減速直接撞上去。
在以深度學習為核心的機器視覺里,邊界框(Bounding Box)是關鍵元素。
在檢測任務中,我們需要同時預測物體的類別和位置,因此需要引入一些與位置相關的概念。通常使用邊界框來表示物體的位置,邊界框是正好能包含物體的矩形框。
對單目、三目來說,其機器視覺如下圖:

那么立體雙目呢?

雙目可以準確識別出中央隔離帶,無論怎么用深度學習、單目、虛擬雙目,單目和三目在這種大面積空洞無紋理特征的車側和車頂圖像前,就如同瞎子,什么也看不到。
事實上,特斯拉也有撞上中央隔離帶致人死亡的事故。
立體雙目的流程是這樣的,如下圖:
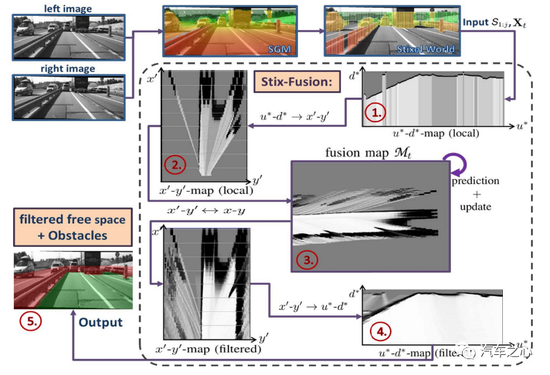
最后輸出可行駛空間(free space),與單目、三目完全不同,它不需要識別,自然也不需要畫出 Bounding Box。
雙目也有缺點,運算量太高。當然,雙目不需要 AI 運算。
盡管只有奔馳和豐田用英偉達處理器處理立體雙目,新造車勢力除了 RIVIAN,目前都不使用立體雙目(小鵬、小米可能在將來使用立體雙目),但英偉達每一次硬件升級都不忘對立體雙目部分特別關照。
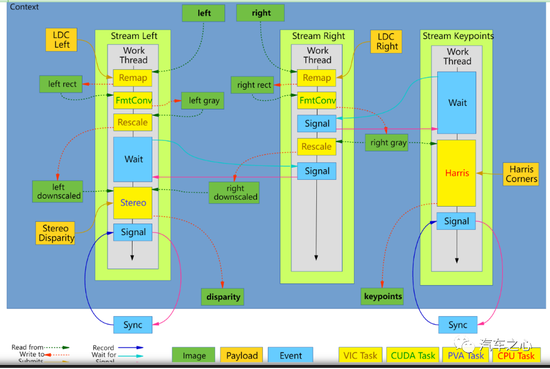
英偉達立體雙目處理流程,立體雙目視差的獲得需要多種運算資源的參加,包括了 VIC、GPU(CUDA)、CPU 和 PVA。
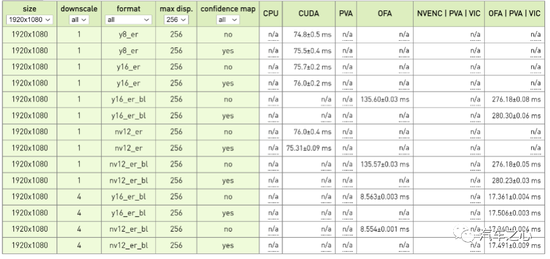
英偉達 Orin 平臺立體雙目視差測試成績,要達到每秒 30 幀,那么處理時間必須低于 30 毫秒,考慮到還有后端決策與控制系統的延遲,處理時間必須低于 20 毫秒。
1 個下取樣情況下,顯然無法滿足 30 幀的要求。
4 個下取樣,不加置信度圖時,單用 OFA 就可以滿足。加置信圖后,需要 OFA/PVA/VIC 聯手,也能滿足 30 幀需求。但這只是 200 萬像素的情況下,300 萬像素估計就無法滿足了。
奔馳的立體雙目是 170 萬像素,輸出視差圖的邊緣精度不會太高,有效距離也不會太遠。如本文開頭所說的狀況,估計可以減速,但難以剎停,反應時間不夠。
可以說,除了立體雙目系統,遇到這次小鵬 P7 事故這樣的怪異目標,都會漏檢。
04
激光雷達能否避免這類事故的發生?
那么,裝了激光雷達會不會避免這個事故?
恐怕也不能。
目前主流的激光雷達也是基于深度學習的,純深度學習視覺遇到的問題,激光雷達也會遇到,無法識別就畫不出 Bounding Box,就認為前面什么都沒,不減速撞上去。
主流的激光雷達算法經歷了三個階段:
-
第一階段是 PointNet
-
第二階段是 Voxel
-
第三階段是 PointPillar
PointPillar 少了 Z 軸切割,而是使用 2D 骨干,這導致其精度下降,性能相較于純 2D 的視覺,提升并不明顯。這也就是為什么特斯拉不使用激光雷達。
而不依賴深度學習、具備可解釋性的多線激光雷達算法,目前還未見面世。博世、奔馳和豐田在研究,這會是一個漫長的過程。
深度學習太好用了,不到半年,一個普通大學生就可以熟練調參。
深度學習淘汰了幾乎所有的傳統算法。
眼下,幾乎沒有人研究激光雷達的傳統算法,比如激光雷達的強度成像。
目前,智能駕駛最關鍵的問題是過于依賴不具備解釋性的深度學習,或者說深度神經網絡,也就是大家常說的 AI——這可能導致無人駕駛永遠無法實現。



“掌”握科技鮮聞 (微信搜索techsina或掃描左側二維碼關注)











