

AI生成的作品受版權保護嗎?我與ChatGPT各抒己見

文/游云庭
因為ChatGPT的走紅,人工智能生成作品是否受著作權保護問題最近很熱,筆者對此類問題的采訪回復基本都是:根據現行法律規定,人工智能生成的作品沒有著作權。但我今天問了目前最有名的人工智能程序ChatGPT,得到的答復卻是人工智能生成的作品受著作權保護,并且ChatGPT的開發者OpenAI公司還想主張作品的收益權。今天就跟大家聊聊這個話題。
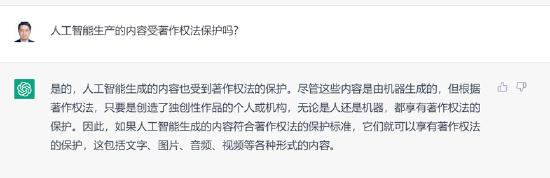
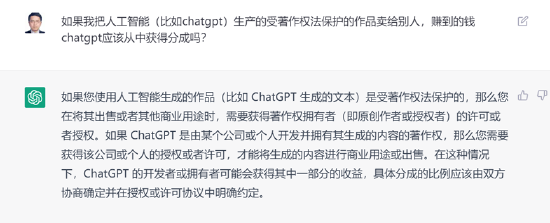
先說說我的觀點:人工智能生成的作品有先天的版權瑕疵,不應當享有著作權并收取授權費用。用戶使用人工智能生成的作品如果被他人侵權,可以依據《反不正當競爭法》維權。
一、人工智能的版權原罪
打鐵還需自身硬,人工智能要大規模收取版權授權費用,自身的底氣是不足的,因為其訓練過程涉嫌大規模侵權,有原罪,版權收費邏輯上不能自洽。
ChatGPT類的人工智能的開發過程中,開發者必然要用大量數據和資源讓其學習和訓練,但現在的各大個人工智能公司都對學習資源的來源諱莫如深,除了商業秘密上的考量外,最主要的問題是,目前的主流人工智能,其訓練都依靠開發公司爬取網上的免費公開數據和資源,然后對人工智能進行投喂和訓練,這些數據和資源的取得并沒有經過被爬取網站的同意,所以是有很大爭議的 ,并且已經有媒體就此進行了起訴 。
筆者就此問了ChatGPT,得到的答復是:訓練數據是網上公開數據,未經授權也不需要授權。
筆者的意見是,這種爬取行為涉嫌侵權。爬取行為是否合法,目前網上的主流做法是看Robots協議,只要被爬取數據的網站的Robots協議同意 ,搜索引擎爬取數據就是合法的。但人工智能公司爬取數據是不是適用Robots協議爭議很大,因為他們爬取目的和搜索引擎不同。
網站被訪問是有服務器成本、技術維護成本和管理成本的,網站經營者同意搜索引擎的爬取,是因為這種爬取是共益行為,搜索引擎爬取數據后可以對網站進行索引,搜索引擎用戶可以更好的訪問網站,商業上對被爬取網站有促進訪問作用的。
而人工智能公司的爬取并非如此,只是為了抓取數據訓練自己的人工智能程序,只有利于他們自己,這就讓網站運營者付出服務器成本、他們技術維護成本和管理成本后啥都得不到,這種行為就不應該適用Robots協議,而應該適用《著作權法》。
根據《著作權法》,讓人工智能學習網上內容的過程是一個復制行為或者臨時復制行為,人工智能公司要先將網上的或者線下獲得的內容爬取,然后輸入到人工智能程序中,無論這個內容是文字、圖片、音頻、視頻還是程序,復制行為都應當獲得相應權利人許可,否則就涉嫌侵權。
有一種很小的可能性是人工智能學習網上內容屬于臨時復制行為,也就是人工智能學習后即刪除數據。根據我國的司法實踐,臨時復制雖然不需要取得著作權人許可,但仍然有數據來源是否為公開可爬取數據,是否將非線上數據(如圖書、文獻)電子化的合法性問題 。另外,至少就微軟新必應內置的ChatGPT搜索結果看,其輸出的內容包含了參考的鏈接,這說明ChatGPT很可能存儲了相應的網站內容,所以不構成臨時復制。
有部分網站遵循的是開源協議,只要符合開源協議的規定,就可以自由的復制再發布這些網站的內容,比如維基百科的GNU自由文檔許可證 ,對這樣的網站,人工智能公司爬取內容應該是可以的,但再發布時還是需要標明來源。而OpenAi公司網站上的ChatGPT輸出內容后,連個數據來源鏈接都不給用戶(微軟的New Bing上的ChatGPT是給來源鏈接的),雖然ChatGPT輸出的內容可能和維基不一樣,但這種只有索取,沒有共益的行為無疑是對開源文化的一種侵蝕,個人認為如果維基百科在國內起訴,除了《著作權法》,還可以援引《反不正當競爭法》第二條,主張OpenAI公司的爬取行為違反公認的商業道德。
二、為什么人工智能生產的作品不享有著作權
1886年9月9日制定于瑞士伯爾尼《保護文學和藝術作品伯爾尼公約》 是全世界都認可的著作權保護公約,我國也是該公約成員國。公約第一條開宗明義:公約成員國保護作者對其文學藝術作品所享權利。公約第三條規定,作者分兩種——公約成員國公民和非公約成員國公民。所以,作者只能是自然人,ChatGPT和其他人工智能軟件可不能成為著作權意義上的作者。這也是各國著作權登記機構目前為止都不接受人工智能登記為作品創作者的原因。
除了自然人作品,我國《著作權法》還規定了法人作品,但ChatGPT創作的作品不屬于法人作品。首先,法人作品也要求自然人創作。其次,法人作品的構成有三個要件:
1、由法人或者非法人組織主持;
2、代表法人或者非法人組織意志創作;
3、并由法人或者非法人組織承擔責任。
如果筆者要ChatGPT寫一篇文章,作品創作的主持者就是筆者,ChatGPT程序是代表筆者的意志進行的創作,如果文章出現了侵權的情況,這個責任也應該由筆者承擔,這些都跟這篇文章的創作者ChatGPT程序沒有關系,所以ChatGPT寫的這篇文章不構成法人作品。至于筆者,只是給了生成文章的條件,并沒有創作文章,故也不對文章享有版權。
人工智能創作的行為更類似《著作權法》上的委托創作,委托人只要輸入完成后的創作要求,具體的創作是人工智能完成的,所以人工智能程序是作品的真正創造者。根據《著作權法》規定,一般情況下,委托創作作品的著作權歸受托方所有,這也是人工智能公司在和筆者聊天時主張人工智能公司對作品享有版權的底氣。
但說嘴硬歸嘴硬,法律文件上ChatGPT還是實誠的,根據其《用戶協議》4.2條的規定:用戶在使用ChatGPT時產生的任何內容,均屬于用戶的知識產權。但ChatGPT可以在不向用戶支付任何費用的情況下使用這些內容。筆者的理解,他們要是規定生產的作品知識產權歸ChatGPT所有,一方面會會得罪用戶;另一方面,權利和責任是一體的,知識產權歸誰,誰就要對內容負責,如果產生了侵權或者爭議內容,比如版權侵權、名譽侵權或者殺傷力更大的政治不正確言論,OpenAI作為創業公司的小身板還真不一定扛得住。
三、用戶使用人工智能所創作的作品被他人盜用該怎么維權?
但人工智能創作的作品不受《著作權法》保護,那如果有用戶用人工智能創作了作品,被別人盜用,該怎么保護自己的權益呢?
先說案例 ,騰訊公司開發了一款名叫Dreamwriter計算機軟件,可以自動寫稿,每年生成三十萬篇文章,某網站轉載了騰訊證券網站上人工智能自動生成的文章,被騰訊公司以侵權為由,告上法庭。南山區法院認為,Dreamwriter軟件在技術上“生成”的文章,均滿足著作權法對文字作品的保護條件,是原告主持創作的法人作品。故判賠1500元,目前判決已生效。
對于該案判決,筆者不是很認同,文章的表達是人工智能完成的,如前文所述,哪怕有獨創性,其創作主體不是自然人,就不應當享受版權保護。這個判決是三年多前做出的,當時人工智能創作還是稀罕物,所以保護一下無傷大雅。而現在ChatGPT和各種人工智能軟件都出來了,人工智能創作的各種文章、美術作品、視頻、音樂、程序大量涌現,此時再讓法院出一個類似判決,估計法院還是會三思而止。
可能有讀者問,不能享受著作權保護,此類權益如果被侵犯應當如何處理?可以用《反不正當競爭法》。比如本案中,如果被告大規模盜用騰訊人工智能生成的文章,用了成百上千篇,此時,騰訊就可以依據《反不正當競爭法》第二條,經營者經營活動應當誠信和遵守商業道德,來保護自己的合法權益。
此時的起訴邏輯應當是:騰訊為開發人工智能軟件付出了成本,發布的文章內容合法,該商業模式是正當的,而被告未經許可大規模盜用文章,沒有付出創作成本,是一種典型的不誠信且有違公認商業道德的擾亂競爭秩序行為。
但《反不正當競爭法》保護的門檻比較高,只有批量大規模的復制內容行為才會落入法律規制范圍,如果本案中的被告只用了少數人工智能生成的文章,比如十篇以內,是不足以跨入違反《反不正當競爭法》的違法門檻的,也就是說,被告未經許可少量抓取內容并發布的,騰訊沒法維權。
有讀者可能會問:人工智能發展速度如此之快,其產生的作品會被用于各行各業,很快會形成一個非常龐大的產業,如果沒有著作權的保護,給人工智能創作的作品弱保護,會不會對產業的發展有很大的影響?會不會不利于保護知識產權嗎?
對此筆者是這么看的:包括著作權在內的知識產權是一種人為創設的權利,社會設立的知識產權制度的目的是為了鼓勵創新,本質是全社會每個人都讓渡了一部分權利來保護他人的創作和發明,考慮到創作的作者、發明者的辛勤工作和對人類文明促進的貢獻,這種讓渡是合理的。
ChatGPT和其他人工智能程序的技術突破的出現讓創作的門檻降低了不少,人類只要文字形式輸入條件,就能得到原先需要花很長時間、很多精力才能創作出的文章、音樂、圖片、視頻。對于此類成本不高的創作結果,社會就無需讓渡過多權利進行保護,這實際意味著人工智能創作的作品可以更自由的使用和傳播,每個人都可以更多的享受到人工智能科技進步帶來的福利。而更多的傳播和更少法律限制,更自由的競爭會讓產業更蓬勃的發展,這肯定比由少數公司或創作者壟斷內容產業要好。
最后,互聯網誕生之初,如果電信公司說,因為要用他們的網絡,所以網上所有傳輸的這些數據的所有權都是電信公司的,那就一定不會有現在如日中天的互聯網產業。人工智能產業也一樣,其創作的內容如果知識產權都歸人工智能公司所有,產業的發展就一定不會很壯大,只有人工智能公司像電信公司那樣,只收取網絡使用費,讓作品自由傳播,那人工智能所創作的作品才能更多更好的造福大眾,同時也會讓產業有長久發展的動力。
本文首發于界面新聞,作者:游云庭,上海大邦律師事務所高級合伙人,知識產權律師。本文僅代表作者觀點。

(聲明:本文僅代表作者觀點,不代表新浪網立場。)




