

看圖學NumPy:掌握n維數組基礎知識點,看這一篇就夠了
來源:量子位
曉查 編譯整理?
量子位 報道 | 公眾號 QbitAI
NumPy是Python的最重要的擴展程序庫之一,也是入門機器學習編程的必備工具。然而對初學者來說,NumPy的大量運算方法非常難記。

最近,國外有位程序員講NumPy的基本運算以圖解的方式寫下來,讓學習過程變得輕松有趣。在Reddit機器學習社區發布不到半天就收獲了500+贊。

下面就讓我們跟隨他的教程一起來學習吧!
教程內容分為向量(一維數組)、矩陣(二維數組)、三維與更高維數組3個部分。
Numpy數組與Python列表
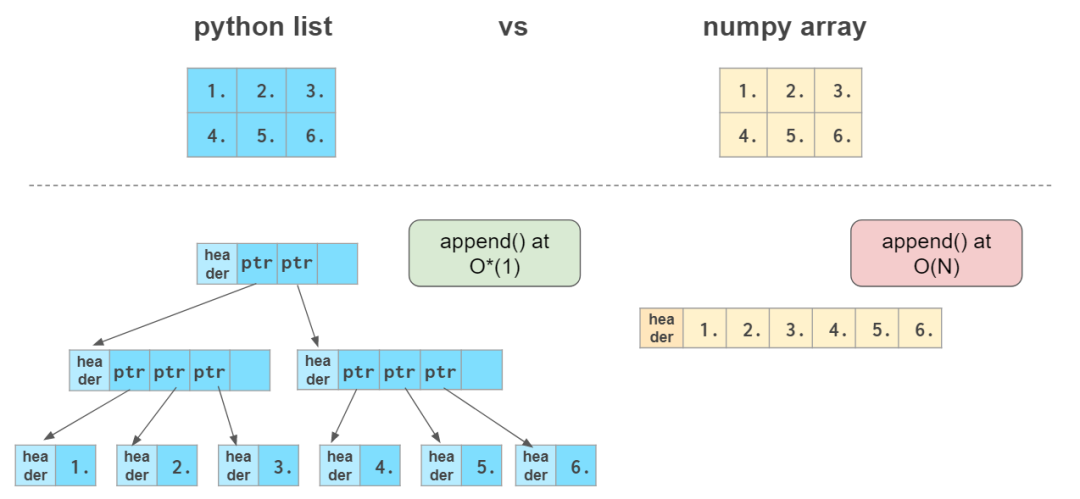
在介紹正式內容之前,先讓我們先來了解一下Numpy數組與Python列表的區別。
乍一看,NumPy數組類似于Python列表。它們都可以用作容器,具有獲取(getting)和設置(setting)元素以及插入和移除元素的功能。
兩者有很多相似之處,以下是二者在運算時的一個示例:

和Python列表相比,Numpy數組具有以下特點:
更緊湊,尤其是在一維以上的維度;向量化操作時比Python列表快,但在末尾添加元素比Python列表慢。
向量運算
向量初始化
創建NumPy數組的一種方法是從Python列表直接轉換,數組元素的類型與列表元素類型相同。

NumPy數組無法像Python列表那樣加長,因為在數組末尾沒有保留空間。
因此,常見的做法是定義一個Python列表,對它進行操作,然后再轉換為NumPy數組,或者用np.zeros和np.empty初始化數組,預分配必要的空間:

有時我們需要創建一個空數組,大小和元素類型與現有數組相同:

實際上,所有用常量填充創建的數組的函數都有一個_like對應項,來創建相同類型的常數數組:

在NumPy中,可以用arange或者linspace來初始化單調序列數組:

如果需要類似[0., 1., 2.]的浮點數組,可以更改arange輸出的類型:arange(3).astype(float)。
但是有更好的方法:arange函數對數據類型敏感,如果將整數作為參數,生成整數數組;如果輸入浮點數(例如arange(3.)),則生成浮點數組。
但是arange在處理浮點數方面并不是特別擅長:

這是因為0.1對于我們來說是一個有限的十進制數,但對計算機而言卻不是。在二進制下,0.1是一個無窮小數,必須在某處截斷。
這就是為什么將小數部分加到步驟arange通常是一個不太好的方法:我們可能會遇到一個bug,導致數組的元素個數不是我們想要的數,這會降低代碼的可讀性和可維護性。
這時候,linspace會派上用場。它不受舍入錯誤的影響,并始終生成要求的元素數。
出于測試目的,通常需要生成隨機數組,NumPy提供隨機整數、均勻分布、正態分布等幾種隨機數形式:

向量索引
一旦將數據存儲在數組中,NumPy便會提供簡單的方法將其取出:

上面展示了各式各樣的索引,例如取出某個特定區間,從右往左索引、只取出奇數位等等。
但它們都是所謂的view,也就是不存儲原始數據。并且如果原始數組在被索引后進行更改,則不會反映原始數組的改變。
這些索引方法允許分配修改原始數組的內容,因此需要特別注意:只有下面最后一種方法才是復制數組,如果用其他方法都可能破壞原始數據:

從NumPy數組中獲取數據的另一種超級有用的方法是布爾索引,它允許使用各種邏輯運算符,來檢索符合條件的元素:
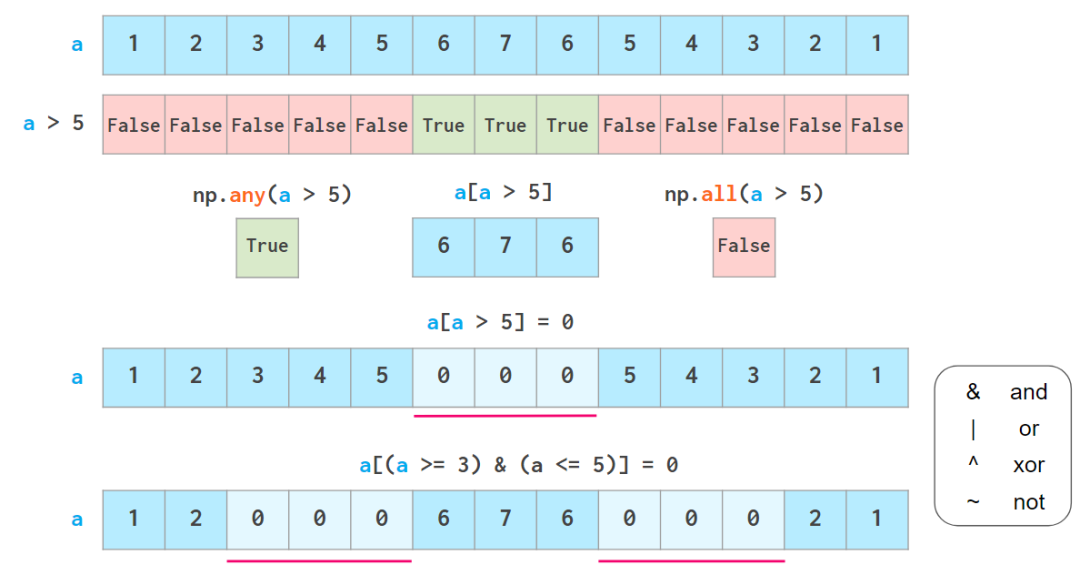
注意:Python中的三元比較3<=a<=5在NumPy數組中不起作用。
如上所述,布爾索引也會改寫數組。它有兩個常見的函數,分別是np.where和np.clip:

向量運算
算術運算是NumPy速度最引入注目的地方之一。NumPy的向量運算符已達到C++級別,避免了Python的慢循環。
NumPy允許像普通數字一樣操作整個數組(加減乘除、整除、冪):

向量還可以與標量進行類似的運算,方法相同:

大多數的數學函數都有NumPy對應項用于處理向量:

向量的點積、叉積也有運算符:

我們也可以進行三角函數、反三角函數、求斜邊運算:

數組可以四舍五入為整數:

NumPy還可以執行以下基本的統計運算(最大最小值、平均值、方差、標準差):

不過排序函數的功能比Python列表對應函數更少:

搜索向量中的元素
與Python列表相反,NumPy數組沒有index方法。

查找元素的一種方法是np.where(a==x)[0][0],它既不優雅也不快速,因為要查找的項需要從開頭遍歷數組的所有元素。
更快的方式是通過Numba中的next((i[0] for i, v in np.ndenumerate(a) if v==x), -1)來加速。
一旦對數組進行排序,情況就會變得更好:v = np.searchsorted(a, x); return v if a[v]==x else -1的復雜度為O(log N),確實非常快,但是首先需要O(N log N)的排序時間。
比較浮點數
函數np.allclose(a, b)用于比較具有給定公差的浮點數組:

np.allclose假設所有的比較數字的等級是1個單位。例如在上圖中,它就認為1e-9和2e-9相同,如果要進行更細致的比較,需要通過atol指定比較等級1:np.allclose(1e-9, 2e-9, atol=1e-17) == False。
math.isclose進行比較沒有假設前提,而是基于用戶給出的一個合理abs_tol值:math.isclose(0.1+0.2–0.3, abs_tol=1e-8) == True。
除此之外np.allclose在絕對和相對公差公式中還存在一些小問題,例如,對某些數存在allclose(a, b) != allclose(b, a)。這些問題已在math.isclose函數中得到解決。
矩陣運算
NumPy中曾經有一個專用的類matrix,但現在已棄用,因此下面將交替使用矩陣和2D數組兩個詞。
矩陣初始化語法與向量相似:

這里需要雙括號,因為第二個位置參數是為dtype保留的。
隨機矩陣的生成也類似于向量的生成:

二維索引語法比嵌套列表更方便:

和一維數組一樣,上圖的view表示,切片數組實際上并未進行任何復制。修改數組后,更改也將反映在切片中。
axis參數
在許多操作(例如求和)中,我們需要告訴NumPy是否要跨行或跨列進行操作。為了使用任意維數的通用表示法,NumPy引入了axis的概念:axis參數實際上是所討論索引的數量:第一個索引是axis=0,第二個索引是axis=1,等等。
因此在二維數組中,如果axis=0是按列,那么axis=1就是按行。

矩陣運算
除了普通的運算符(如+,-,*,/,//和**)以元素方式計算外,還有一個@運算符可計算矩陣乘積:

在第一部分中,我們已經看到向量乘積的運算,NumPy允許向量和矩陣之間,甚至兩個向量之間進行元素的混合運算:

行向量與列向量
從上面的示例可以看出,在二維數組中,行向量和列向量被不同地對待。
默認情況下,一維數組在二維操作中被視為行向量。因此,將矩陣乘以行向量時,可以使用(n,)或(1,n),結果將相同。
如果需要列向量,則有轉置方法對其進行操作:

能夠從一維數組中生成二位數組列向量的兩個操作是使用命令reshape重排和newaxis建立新索引:

這里的-1參數表示reshape自動計算第二個維度上的數組長度,None在方括號中充當np.newaxis的快捷方式,該快捷方式在指定位置添加了一個空axis。
因此,NumPy中總共有三種類型的向量:一維數組,二維行向量和二維列向量。這是兩者之間顯式轉換的示意圖:
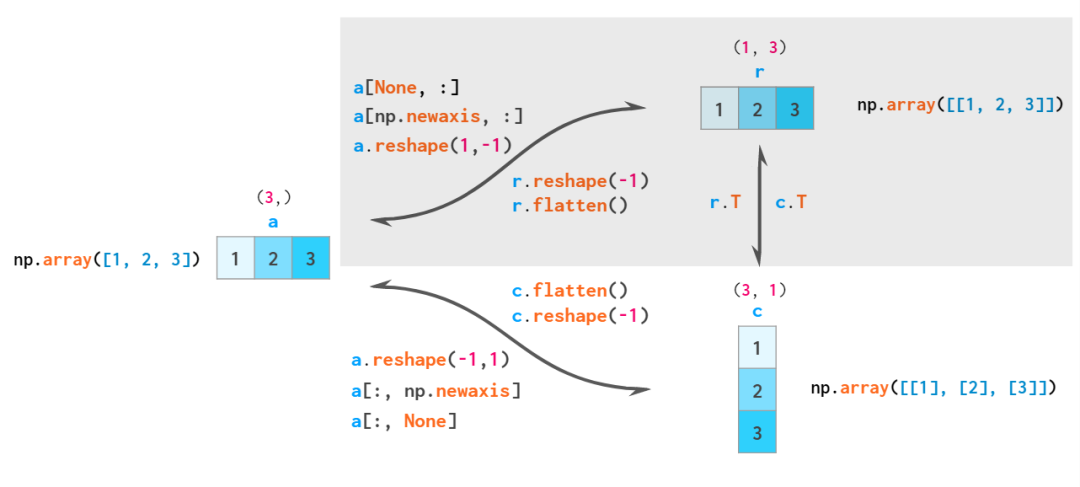
根據規則,一維數組被隱式解釋為二維行向量,因此通常不必在這兩個數組之間進行轉換,相應區域用灰色標出。
矩陣操作
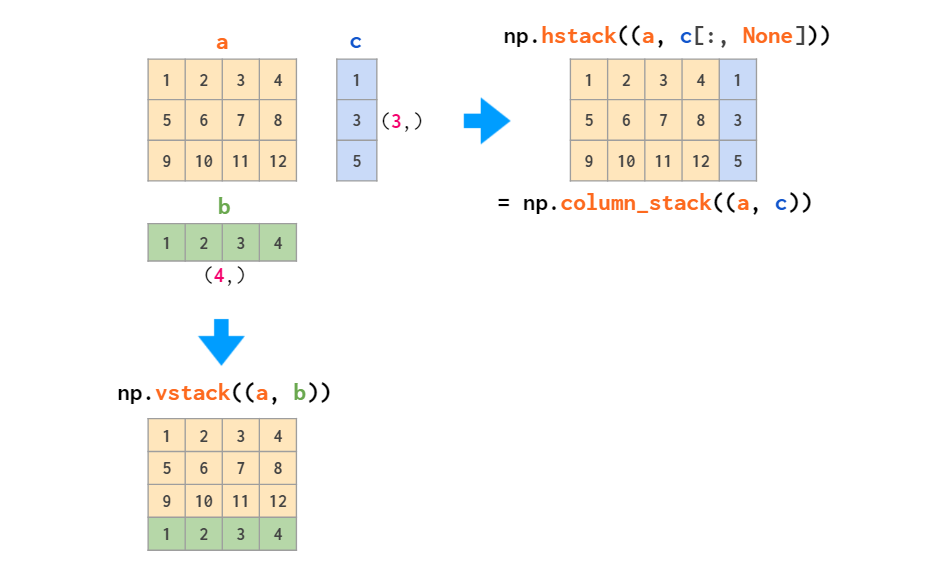
連接矩陣有兩個主要函數:

這兩個函數只堆疊矩陣或只堆疊向量時,都可以正常工作。但是當涉及一維數組與矩陣之間的混合堆疊時,vstack可以正常工作:hstack會出現尺寸不匹配錯誤。
因為如上所述,一維數組被解釋為行向量,而不是列向量。解決方法是將其轉換為列向量,或者使用column_stack自動執行:
堆疊的逆向操作是分裂:

矩陣可以通過兩種方式完成復制:tile類似于復制粘貼,repeat類似于分頁打印。

特定的列和行可以用delete進行刪除:

逆運算為插入:

append就像hstack一樣,該函數無法自動轉置一維數組,因此再次需要對向量進行轉置或添加長度,或者使用column_stack代替:
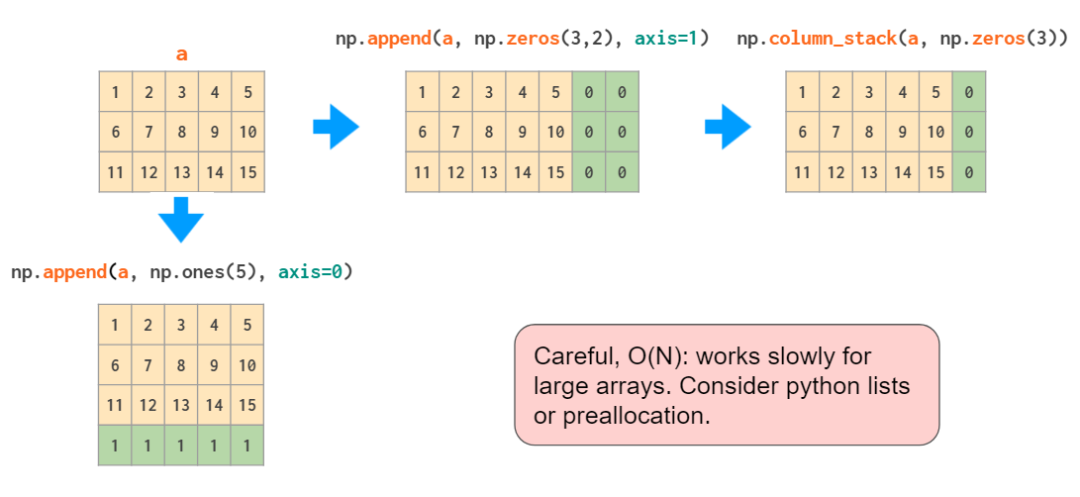
實際上,如果我們需要做的就是向數組的邊界添加常量值,那么pad函數就足夠了:

Meshgrid
如果我們要創建以下矩陣:

兩種方法都很慢,因為它們使用的是Python循環。在MATLAB處理這類問題的方法是創建一個meshgrid:
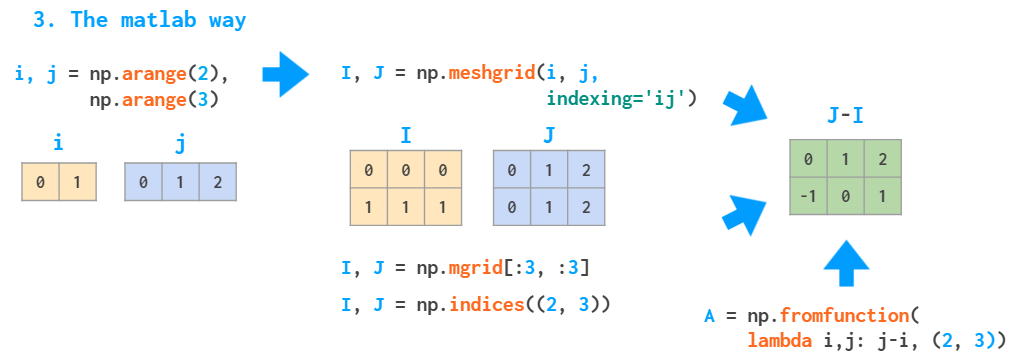
該meshgrid函數接受任意一組索引,mgrid僅是切片,indices只能生成完整的索引范圍。fromfunction如上所述,僅使用I和J參數一次調用提供的函數。
但是實際上,在NumPy中有一種更好的方法。無需在整個矩陣上耗費存儲空間。僅存儲大小正確的矢量就足夠了,運算規則將處理其余的內容:

在沒有indexing=’ij’參數的情況下,meshgrid將更改參數的順序:J, I= np.meshgrid(j, i)—這是一種“ xy”模式,用于可視化3D圖。
除了在二維或三維數組上初始化外,meshgrid還可以用于索引數組:

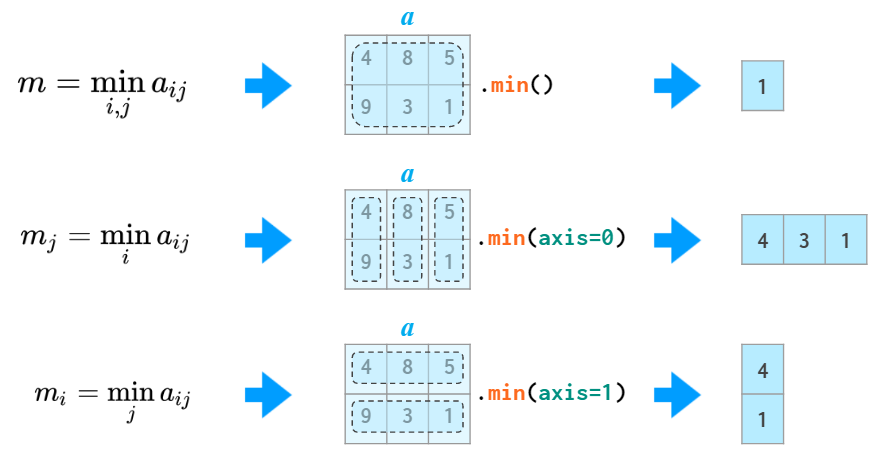
矩陣統計
就像之前提到的統計函數一樣,二維數組接受到axis參數后,會采取相應的統計運算:
二維及更高維度中,argmin和argmax函數返回最大最小值的索引:

all和any兩個函數也能使用axis參數:

矩陣排序
盡管axis參數對上面列出的函數很有用,但對二維排序卻沒有幫助:

axis絕不是Python列表key參數的替代。不過NumPy具有多個函數,允許按列進行排序:
1、按第一列對數組排序:a[a[:,0].argsort()]

argsort排序后,此處返回原始數組的索引數組。
此技巧可以重復,但是必須小心,以免下一個排序混淆前一個排序的結果:
a = a[a[:,2].argsort()]
a = a[a[:,1].argsort(kind=’stable’)]
a = a[a[:,0].argsort(kind=’stable’)]

2、有一個輔助函數lexsort,該函數按上述方式對所有可用列進行排序,但始終按行執行,例如:
a[np.lexsort(np.flipud(a[2,5].T))]:先通過第2列排序,再通過第5列排序;
a[np.lexsort(np.flipud(a.T))]:按從左到右所有列依次進行排序。

3、還有一個參數order,但是如果從普通(非結構化)數組開始,則既不快速也不容易使用。
4、因為這個特殊的操作方式更具可讀性和它可能是一個更好的選擇,這樣做的pandas不易出錯:
pd.DataFrame(a).sort_values(by=[2,5]).to_numpy():通過第2列再通過第5列進行排序。
pd.DataFrame(a).sort_values().to_numpy():通過從左向右所有列進行排序
高維數組運算
通過重排一維向量或轉換嵌套的Python列表來創建3D數組時,索引的含義為(z,y,x)。
第一個索引是平面的編號,然后才是在該平面上的移動:

這種索引順序很方便,例如用于保留一堆灰度圖像:這a[i]是引用第i個圖像的快捷方式。
但是此索引順序不是通用的。處理RGB圖像時,通常使用(y,x,z)順序:前兩個是像素坐標,最后一個是顏色坐標(Matplotlib中是RGB ,OpenCV中是BGR ):

這樣,可以方便地引用特定像素:a[i,j]給出像素的RGB元組(i,j)。
因此,創建特定幾何形狀的實際命令取決于正在處理的域的約定:

顯然,NumPy函數像hstack、vstack或dstack不知道這些約定。其中硬編碼的索引順序是(y,x,z),RGB圖像順序是:

如果數據的布局不同,則使用concatenate命令堆疊圖像,并在axis參數中提供顯式索引數會更方便:

如果不方便使用axis,可以將數組轉換硬編碼為hstack的形式:

這種轉換沒有實際的復制發生。它只是混合索引的順序。
混合索引順序的另一個操作是數組轉置。檢查它可能會讓我們對三維數組更加熟悉。
根據我們決定的axis順序,轉置數組所有平面的實際命令將有所不同:對于通用數組,它交換索引1和2,對于RGB圖像,它交換0和1:

有趣的是,(和唯一的操作模式)默認的axes參數顛倒了索引順序,這與上述兩個索引順序約定都不相符。
最后,還有一個函數,可以在處理多維數組時節省很多Python循環,并使代碼更簡潔,這就是愛因斯坦求和函數

(聲明:本文僅代表作者觀點,不代表新浪網立場。)

作者簡介
作者文章
推薦閱讀
- 輕食、代餐,真藍海還是偽風口?
-

- 2020年朋友圈中好友互動最多的廣告,一定有WonderLab。詳細>>
- 我們臥底粉絲群,揭開明星健康寶照片被倒賣背后的產業鏈
-
- 不久前,“明星健康寶照片被泄露”事件引發大眾關注,受害者遠不止“氣運聯盟”。詳細>>
- 當跨年晚會不再“合家歡”:小眾的勝利,流量的狂歡
-

- 跨年晚會太多,觀眾有點兒不夠用了。詳細>>
- 百度地圖的內容更新,已經實現了90%AI化
-
- 在AI技術的加持下,今天的百度地圖已經實現了90%數據生產環節自動化,并基于強大的產品實力為很多行業帶來了效率提升。詳細>>