

豆包代碼大模型曝光!在字節(jié)最新開源基準(zhǔn)里,多種編程語言性能僅次于OpenAI/Claude
允中 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
豆包代碼大模型,不小心給曝光了!
在字節(jié)開源的代碼大模型評估基準(zhǔn)FullStack Bench里面,出現(xiàn)了此前字節(jié)未披露過的Doubao-Coder。
不過目前還只是Preview版,還并沒有上線。
它在多種編程語言上的性能表現(xiàn)如下,可以看到在閉源模型中排名第五。

今年6月,字節(jié)還發(fā)布了AI編程助手豆包MarsCode。據(jù)傳即由Doubao-Coder模型支撐。
目前,豆包MarsCode每月為用戶貢獻(xiàn)百萬量級代碼。
而回到這個評估基準(zhǔn),據(jù)介紹FullStack Bench是目前最全面的代碼評估數(shù)據(jù)集。
團(tuán)隊還同步開源了可隨時測評代碼大模型的沙盒執(zhí)行環(huán)境SandBox Fusion,單服務(wù)器即可部署,也可直接在線體驗。
全新代碼大模型評估基準(zhǔn)FullStack Bench
既然如此,那就先來了解一下這個最新評估基準(zhǔn)。
有一說一,現(xiàn)在代碼大模型越來越卷,評估AI編程水平的“考卷”也被迫升級~
代碼評估基準(zhǔn)可以幫助代碼大模型不斷優(yōu)化。不過,當(dāng)前的主流基準(zhǔn)越來越難以反映代碼大模型的真實水平了。
主要體現(xiàn)在題目類型相對單調(diào),覆蓋的應(yīng)用領(lǐng)域和編程語言少,模型即便在考試中拿了高分,現(xiàn)實中可能還是難以應(yīng)對復(fù)雜的編程問題。
為了更真實地評估AI編程水平,字節(jié)豆包大模型團(tuán)隊聯(lián)合M-A-P社區(qū),開源了全新代碼大模型評估基準(zhǔn)FullStack Bench。

這是一個專注于全棧編程和多語言編程的代碼評估數(shù)據(jù)集,它首次囊括了編程全棧技術(shù)中超過11類真實場景,覆蓋16種編程語言,包含3374個問題。
FullStack Bench的應(yīng)用領(lǐng)域抽取自全球最大的程序員技術(shù)問答社區(qū)Stack Overflow,相比HumanEval等基準(zhǔn)覆蓋的編程領(lǐng)域擴大了一倍以上。
此前業(yè)界基準(zhǔn)難以反映真實世界代碼開發(fā)的多樣性和復(fù)雜性。
例如,HumanEval和MBPP中近80%數(shù)據(jù)只聚焦于基礎(chǔ)編程和高級編程問題;DS-1000中超過95%數(shù)據(jù)集中于數(shù)據(jù)分析和機器學(xué)習(xí),且僅對Python語言進(jìn)行評測;xCodeEval雖覆蓋多項任務(wù),但基本局限于高級編程和數(shù)學(xué)領(lǐng)域;McEval和MDEval擴展了支持的編程語言,但應(yīng)用領(lǐng)域仍局限于基礎(chǔ)編程和高級編程,未涉及更廣泛的場景。
為模擬全棧開發(fā)的實際應(yīng)用場景,字節(jié)豆包大模型和M-A-P研究團(tuán)隊分析了全球最大的程序員技術(shù)問答社區(qū)Stack Overflow上的問題分布,從中提煉出常見的真實編程應(yīng)用領(lǐng)域。
團(tuán)隊從Stack Overflow上隨機抽取了50萬個問題,并使用大模型為每個問題標(biāo)注應(yīng)用領(lǐng)域類型。
研究團(tuán)隊篩選出占總問題數(shù)前88.1%的主要應(yīng)用領(lǐng)域,其余領(lǐng)域歸類為“其他”。再通過對領(lǐng)域分布做適當(dāng)調(diào)整來保證魯棒性,最終形成了FullStack Bench關(guān)注的超過11種應(yīng)用場景及分布比例。

FullStack Bench包含3374個問題(中文及英文問題各占一半),每個問題均包括題目描述、參考解決方案、單元測試用例及標(biāo)簽,總計15168個單元測試。
為保證評估準(zhǔn)確性,每個問題內(nèi)容均由相關(guān)領(lǐng)域的編程專家設(shè)計,并經(jīng)AI和人工驗證進(jìn)行質(zhì)量復(fù)核。例如,數(shù)據(jù)分析相關(guān)問題,由數(shù)據(jù)工程專家提出并把關(guān)配套內(nèi)容。

在初始數(shù)據(jù)集構(gòu)建后,團(tuán)隊根據(jù)主流代碼大模型測試結(jié)果,按問題難度、模糊性和可解性對數(shù)據(jù)質(zhì)量進(jìn)行了交叉評估和進(jìn)一步完善。
FullStack Bench數(shù)據(jù)構(gòu)成情況如下圖所示。

為方便開發(fā)者對大模型代碼能力進(jìn)行系統(tǒng)性測試,豆包大模型團(tuán)隊還開源了一款高效的代碼沙盒執(zhí)行工具——SandboxFusion,用于評估來自不同語言的不同編程任務(wù)。
除了FullStack Bench,SandboxFusion還兼容超過10種廣泛使用的代碼評估數(shù)據(jù)集,支持23種編程語言。開發(fā)者在單服務(wù)器上即可輕松部署SandboxFusion,也可直接在GitHub上進(jìn)行體驗。

評測結(jié)果:解決難題,閉源模型仍優(yōu)于開源模型
發(fā)布評測基準(zhǔn)及沙盒的同時,研究團(tuán)隊也基于FullStack Bench測評了全球20余款代碼大模型及語言大模型的編程表現(xiàn)。
模型包括Qwen2.5-Coder、DeepSeek-Coder-v2、CodeLlama等開源模型,以及GPT-4o、OpenAI-o1、Doubao-Coder-Preview等閉源模型。對于開源模型,根據(jù)模型大小,分為五個組別:1B+、6B+、13B+、20B+和70B+。
跨領(lǐng)域表現(xiàn):數(shù)學(xué)編程領(lǐng)域差異最大
得益于強大的推理能力,OpenAI o1-preview不出所料地領(lǐng)先。
不過,一些開源模型也有不錯的表現(xiàn)。如DeepSeekCoderv2-Instruct,在AP(高級編程)、OS(操作系統(tǒng))和其他類別中得到高分,拉開了與其他開源模型的差距。
OpenCoder-1.5B-Instruct、Qwen2.5-Coder-7B-Instruct、Qwen2.5-Coder-14B-Instruct在其各自開源組別中拔得頭籌,并超越了一些更高參數(shù)級別的模型。

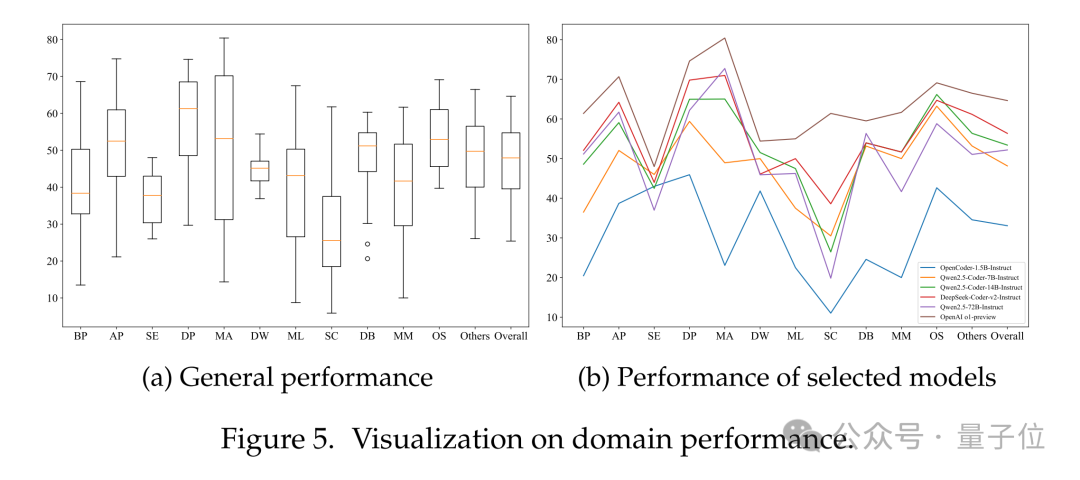
為了全面評估現(xiàn)有大語言模型在不同場景下的表現(xiàn),研究團(tuán)隊可視化了模型在FullStack Bench各領(lǐng)域的表現(xiàn)。
在BP(基礎(chǔ)編程)、AP(高級編程)、MA(數(shù)學(xué)編程)、ML(機器學(xué)習(xí))和MM(多媒體)等領(lǐng)域中,模型表現(xiàn)差異顯著,其中以MA領(lǐng)域的差距最大。
MA最佳表現(xiàn)者為OpenAI o1-preview(得分80.42),而最差的是CodeLlama-34B-Instruct(得分14.34)。數(shù)學(xué)編程要求模型同時具備數(shù)學(xué)和編程能力,那些在高度專業(yè)化代碼語料庫上訓(xùn)練的模型,在MA領(lǐng)域往往表現(xiàn)較差。
這一結(jié)果進(jìn)一步證明,F(xiàn)ullStack Bench能夠更全面地評估模型的綜合編程能力。
跨語言表現(xiàn):C++、C和Ruby上存較大差異
研究團(tuán)隊對不同模型在多種編程語言上的性能表現(xiàn)進(jìn)行了分析。
大多數(shù)模型在Bash編程任務(wù)中表現(xiàn)良好。然而,在C++、C和Ruby的表現(xiàn)上存在較大差異,這表明模型設(shè)計者可能在訓(xùn)練語料庫中對這些語言進(jìn)行了選擇性采樣。部分1B+的小型模型在D、R和Scala語言上的表現(xiàn)較差,其通過率低于10%,這表明它們的多語言處理能力都較弱。

由于SandboxFusion提供了來自編譯器的反饋,研究人員評估了模型在部分編程語言上的編譯通過率。實驗結(jié)果表明,編譯通過率與測試通過率之間存在正相關(guān)關(guān)系,但編譯通過并不意味著測試一定通過。同時,研究還探討了中英文表達(dá)對模型性能的影響。
解決難題,閉源模型普遍優(yōu)于開源模型
不同模型在不同難度問題上的表現(xiàn)存在明顯差異。總體而言,1B+模型和CodeLlama系列在所有難度級別上的表現(xiàn)均不盡如人意。其余模型在解決簡單問題時表現(xiàn)相似,但在中等難度問題上存在一定差距。對于難度較大的問題,閉源模型普遍優(yōu)于開源模型。

使用SandboxFusion,可提升模型表現(xiàn)
研究人員對比了“反思策略(Reflection)”和“N次推斷策略(BoN)”兩種策略。在Reflection策略中,通過利用SandboxFusion的反饋上下文對答案進(jìn)行N次精煉,復(fù)現(xiàn)了自我精煉策略 [Madaan et al., 2024]。而在BoN策略中,僅進(jìn)行N次推斷以獲得結(jié)果。
結(jié)果如圖所示,“Reflection”策略明顯優(yōu)于“BoN”,這表明SandboxFusion提供的反饋上下文具有較高的有效性。

了解這篇研究的詳情,可見文內(nèi)Arxiv鏈接,或關(guān)注「豆包大模型團(tuán)隊」公眾號,查閱更詳細(xì)解讀。
參考鏈接:
[1]論文鏈接:https://arxiv.org/pdf/2412.00535v2
[2]數(shù)據(jù)集開源地址:https://huggingface.co/datasets/ByteDance/FullStackBench
[3]沙盒開源地址:https://github.com/bytedance/SandboxFusion
[4]沙盒體驗入口:https://bytedance.github.io/SandboxFusion/playground/datasets
*本文系量子位獲授權(quán)刊載,觀點僅為作者所有。

(聲明:本文僅代表作者觀點,不代表新浪網(wǎng)立場。)



