

誰在給大模型打分?

大模型,跑個分。
@科技新知 原創
作者丨樟稻 編輯丨伊頁
當新賽道擠滿了摩拳擦掌的選手,場邊的裁判員也應運而生。
5月,國家科技部下屬的中國科學技術信息研究所,發布了《中國人工智能大模型地圖研究報告》。內容顯示,截至5月28日,國內10億級參數規模以上基礎大模型至少已發布79個。
每一個亮相時,都少不了“行業領先”“技術革新”諸如此類的標簽。不免引來質疑:如何直觀地評判哪一款大模型在技術和性能上更為卓越?那些宣稱“第一”的評估標準與數據來源又是怎樣的?
一把衡量不同模型效能基準的“尺子”亟待打造。
前不久,國際咨詢公司IDC發布《AI大模型技術能力評估報告2023》,調研了9家中國市場主流大模型技術廠商。其他不少研究機構和團隊也投入資源,發布了對應的評價標準和深度報告。這背后所顯露的現象和趨勢,更值得深層次的探討。
評測基準百家爭鳴
ChatGPT 帶火了大模型應用的相關研究,評測基準亦成為關注焦點所在。
日前,微軟亞洲研究院公開了介紹大模型評測領域的綜述文章《A Survey on Evaluation of Large Language Models》。根據不完全統計(見下圖),大模型評測方面文章的發表呈上升趨勢,越來越多的研究著眼于設計更科學、更好度量、更準確的評測方式來對大模型的能力進行更深入的了解。
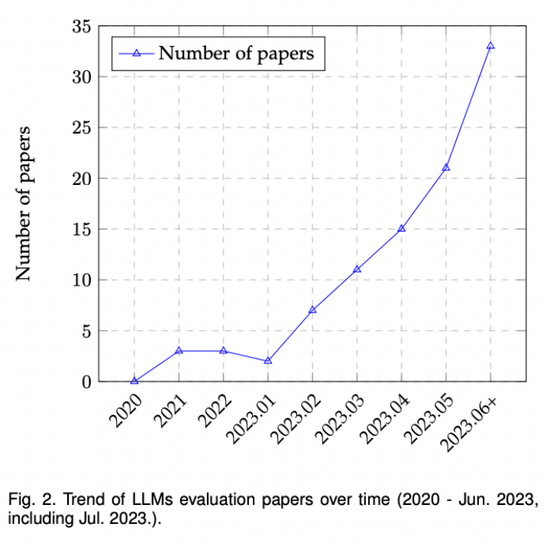
文中一共列出了19個受歡迎的基準測試,每個都側重于不同的方面和評估標準,為其各自的領域提供了寶貴的貢獻。為了更好地總結,研究員將這些基準測試分為兩類:通用基準(General benchmarks)和具體基準(Specific benchmarks),其中不乏一些深具盛名的大模型基準。
Chatbot Arena,就被行業人士普遍認為是最具公平性與廣泛接受度的平臺。其背后的推手——LMSYS Org,是一個開放的研究組織,由加州大學伯克利分校、加州大學圣地亞哥分校和卡內基梅隆大學合作創立。
這個創新性的評估標準,為各大AI研究機構與技術愛好者,提供了一個既獨特又具有激烈競爭力的場所,專門用于評價和比對不同聊天機器人模型的實際應用效果。用戶能夠與其中的匿名模型進行實時互動,而后通過在線投票系統表達他們對于某一模型的滿意度或喜好。
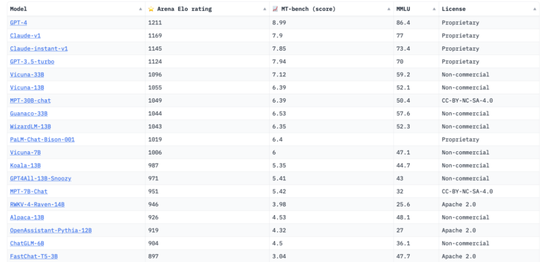
值得一提的是,該評測方式的設計靈感來源于國際象棋等競技游戲中盛行的ElO評分系統。通過積累大量的用戶投票,它能夠更為貼近實際場景地評估各模型的綜合表現。
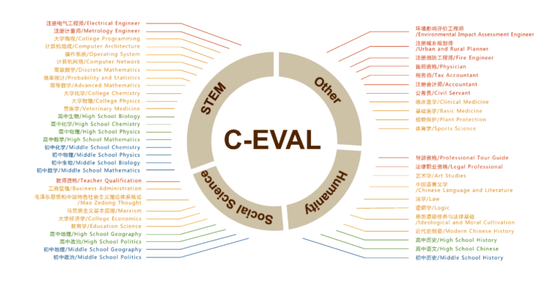
微軟亞洲研究院還在文中提到了通用基準C-Eval,這是一個全面的中文基礎模型評估套件。它包含了13948個多項選擇題,涵蓋了52個不同的學科和四個難度級別,該項目由上海交通大學、清華大學、愛丁堡大學共同完成。
除了通用任務的基準測試外,還存在一些專為某些下游任務設計的具體基準測試。
譬如,MultiMedQA是一個醫學問答基準測試,重點關注醫學檢查、醫學研究和消費者健康問題。該基準由谷歌和DeepMind的科研人員提出,它包括七個與醫學問答相關的數據集,其中包括六個現有的數據集和一個新的數據集。測試目標是評估大語言模型在臨床知識和問答能力方面的性能。
還有一些中文評測基準被微軟研究院所遺漏。例如SuperCLUE,作為針對中文可用的通用大模型的一個測評基準,由來自中文語言理解測評基準開源社區CLUE的成員發起。
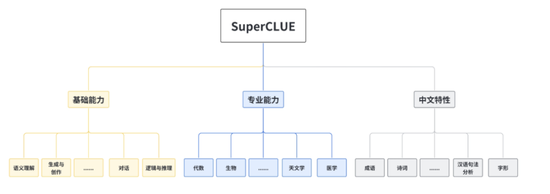
為了著眼于綜合評價大模型的能力,使其能全面地測試大模型的效果,又能考察模型在中文上特有任務的理解和積累,SuperCLUE從三個不同的維度評價模型的能力:基礎能力、專業能力和中文特性能力。
實際上,這些維度只是冰山一角。在評測 LLMs 的性能時,選擇合適的任務和領域對于展示大型語言模型的表現、優勢和劣勢至關重要。微軟亞洲研究院將現有的任務劃分為了7個不同的類別:
自然語言處理:包括自然語言理解、推理、自然語言生成和多語言任務;
魯棒性、倫理、偏見和真實性;
醫學應用:包括醫學問答、醫學考試、醫學教育和醫學助手;
社會科學;
自然科學與工程:包括數學、通用科學和工程;
代理應用:將 LLMs 作為代理使用;
其他應用。
縱觀當前AI領域的發展趨勢,大模型的評測基準測試不再僅僅是一個單一的技術環節,而是已經逐步成為整個上下游產業鏈中的重要配套。
正確地使用“尺子”
存在即合理。
大模型評測基準的誕生和持續優化,之所以呈現出愈演愈烈的勢頭,無疑與其所能帶來的巨大價值和業界的廣泛認同是密不可分的。
可以看到,通過深入的大模型評測基準分析,能夠更為明確和系統地揭示大模型在各種應用場景中的優勢與局限性。這種專業的評估不僅為AI領域的研發者提供了清晰的指導,同時也助力用戶最終作出更為明智的技術選擇。
在復雜的研發過程中,判斷技術方案或特定模型的優越性往往是一個挑戰。C-Eval數據集和其相關榜單,意義不僅僅是一系列的數字或排名,而是為大模型的研發者提供了一套客觀、系統的評估工具。
用C-Eval項目團隊的話來說,“我們的最重要目標是輔助模型開發”。
具體來看,研發團隊可以與企業緊密合作,將大模型評測基準整合到他們的開發和測試工作流程中。這不僅可以在實際應用環境中驗證模型的性能,還能通過雙方的深度溝通,找到在測試過程中可能遇到的技術難題和挑戰,從而實現更為高效和準確的模型優化。
正是基于這一點,多家頭部大模型廠商不僅在模型研發上持續投入,同時也在評測基準的制定與優化上下足了功夫。
譬如科大訊飛通過認知智能全國重點實驗室牽頭設計了通用認知大模型評測體系,覆蓋7大類481個細分任務類型;阿里巴巴達摩院多語言NLP團隊發布了首個多語言多模態測試基準M3Exam,共涵蓋12317道題目,等等。

不過也正如C-Eval項目團隊所強調的:對于大模型廠商,單純地追求榜單的高位排名,并不應成為其主要追求。
當廠商將榜單成績作為首要目標時,可能會為了追求高分而采用過度擬合榜單的策略,這樣就很容易損失模型的廣泛適用性。更為關鍵的是,若僅僅著眼于排名,廠商可能為了短期的成績而試圖尋找捷徑,從而違背了真正踏實的科研精神與價值觀。
再看終端用戶的視角中,大模型測評基準提供了一個全面的、結構化的參考框架,從而充分地輔助用戶在眾多技術選項中做出更為理性和明智的決策。這種評測不僅降低了技術采納的風險,也確保了用戶能夠從所選模型中獲得最佳的投資回報率。
尤其對于那些還未擁有深厚大模型研發實力的企業來說,深入了解大模型的技術邊界,并能夠針對自身需求高效地進行技術選型,是至關重要的。
綜上,不論是對于背后的研發團隊還是產品側的終端用戶,大模型評測基準都承載著不可估量的價值和意義。
劣幣來襲
吊詭的是,由于在原理核心上并不涉及復雜的技術門檻,導致目前市場上的大模型評測基準的數量,甚至已經超過了大模型本身。這其中自然有許多機構見到了可乘之機,進行各種市場操作,包括混淆視聽、誤導消費者的行為。
此前就有觀點認為,隨著AI技術的發展,大模型評測可能會被某些公司或機構用作營銷工具,通過發布其模型的高分評測結果來吸引公眾的注意力,以期提高產品的市場份額。
目前也有一些突出的現象佐證:在某些特定評測榜單中領先的廠商,放到其他不同的榜單評測中,卻未能夠維持其優勢地位。
不能排除存在著客觀原因。當前階段,對于大模型的評估機制和具體評測指標,并沒有達到一個行業共識,更遑論出現統一的的評測標準。不同的應用環境和任務標準,就會產生截然不同的評價框架和需求。
此外,大模型評測通常依賴于兩大主要方法:自動評測和人工評測。自動評測是基于精確的計算機算法和一系列預定義的指標進行,而人工評測更多強調人類專家的主觀見解、經驗和質量判定。
遇到大模型生成詩歌或短文這類任務時,人工評測的主觀性變得尤為顯著。自古“文無第一,武無第二”,不同的評審者可能會對同一作品給出不同的評價。
然而,從相關搜索結果中不難發現,大模型評測早已被某些廠商視為一個營銷的競技場。畢竟在一個競爭激烈的市場中,每一個廠商都希望自己的產品能夠脫穎而出。

因此有充分的動機去選擇那些能夠突顯自己產品優勢的評測指標,而忽略那些可能暴露弱項的指標。這種選擇性的展示,即使有機會帶來短期的市場優勢,但是對于消費者和整個行業來說,必然是有害的。
一時的誤導一旦扭曲了市場的競爭格局,可能使得真正有價值的創新被埋沒。劣幣驅逐良幣之下,那些只是為了宣傳而進行的“創新”反而會趨之若鶩。
從這個角度出發,大模型評測基準還是應該回歸其本質,即為了更好地理解和比較不同模型的性能,為研發者和終端用戶提供反饋,而不是為了產品廠商的短期利益。
既然要當裁判員,還是要盡量做到獨立、客觀、第三方。

(聲明:本文僅代表作者觀點,不代表新浪網立場。)

作者簡介




