

GPT-4王者加冕!讀圖做題性能炸天,憑自己就能考上斯坦福

新智元報道
編輯:編輯部
【新智元導讀】Open AI的GPT-4在萬眾矚目中閃亮登場,多模態功能太炸裂,簡直要閃瞎人類的雙眼。李飛飛高徒、斯坦福博士Jim Fan表示,GPT4憑借如此強大的推理能力,已經可以自己考上斯坦福了!
果然,能打敗昨天的Open AI的,只有今天的Open AI。
剛剛,Open AI震撼發布了大型多模態模型GPT-4,支持圖像和文本的輸入,并生成文本結果。
號稱史上最先進的AI系統!

GPT-4不僅有了眼睛可以看懂圖片,而且在各大考試包括GRE幾乎取得了滿分成績,橫掃各種benchmark,性能指標爆棚。
Open AI 花了 6 個月的時間使用對抗性測試程序和 ChatGPT 的經驗教訓對 GPT-4 進行迭代調整 ,從而在真實性、可控性等方面取得了有史以來最好的結果。
大家都還記得,2月初時微軟和谷歌鏖戰三天,2月8日微軟發布ChatGPT版必應時,說法是必應‘基于類ChatGPT技術’。
今天,謎底終于解開了——它背后的大模型,就是GPT-4!
圖靈獎三巨頭之一Geoffrey Hinton對此贊嘆不已,‘毛蟲吸取了營養之后,就會化繭為蝶。而人類提取了數十億個理解的金塊,GPT-4,就是人類的蝴蝶。’

順便提一句,ChatGPT Plus用戶現在可以先上手了。
考試幾乎滿分,性能躍遷炸天
在隨意談話中,GPT-3.5和GPT-4之間的區別是很微妙的。只有當任務的復雜性達到足夠的閾值時,差異就出現了,GPT-4比GPT-3.5 更可靠、更有創意,并且能夠處理更細微的指令。
為了了解這兩種模型之間的差異,Open AI在各種基準測試和一些為人類設計的模擬考試上進行了測試。
GPT-4在各種考試中,有幾個測試幾乎接近了滿分:
-
USABO Semifinal 2020(美國生物奧林匹克競賽)
-
GRE Writing
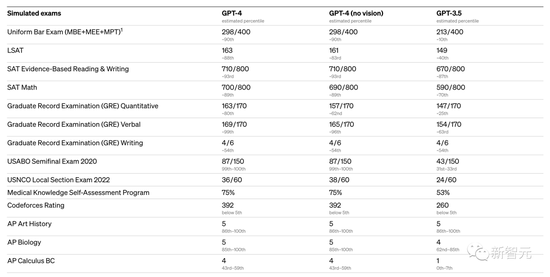
以美國 BAR律師執照統考為例,GPT3.5可以達到 10%水平,GPT4可以達到90%水平。生物奧林匹克競賽從GPT3.5的31%水平,直接飆升到 99%水平。

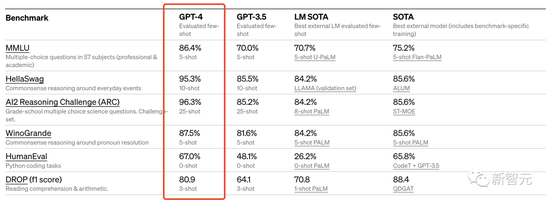
此外,Open AI 還在為機器學習模型設計的傳統基準上評估了 GPT-4。從實驗結果來看,GPT-4 大大優于現有的大型語言模型,以及大多數 SOTA 模型:
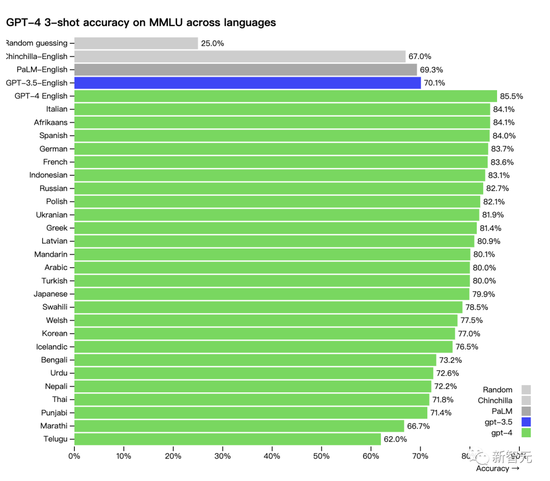
另外,GPT-4在不同語種上的能力表現:中文的準確度大概在 80% 左右,已經要優于GPT-3.5的英文表現了。
許多現有的 ML 基準測試都是用英語編寫的。為了初步了解GPT-4其他語言的能力,研究人員使用 Azure翻譯將 MMLU 基準(一套涵蓋57個主題的14000個多項選擇題)翻譯成多種語言。
在測試的 26 種語言的 24 種中,GPT-4 優于 GPT-3.5 和其他大語言模型(Chinchilla、PaLM)的英語語言性能:
Open AI表示在內部使用 GPT-4,因此也關注大型語言模型在內容生成、銷售和編程等方面的應用效果。另外,內部人員還使用它來幫助人類評估人工智能輸出。
對此,李飛飛高徒、英偉達AI科學家Jim Fan點評道:‘GPT-4最強的其實就是推理能力。它在GRE、SAT、法學院考試上的得分,幾乎和人類考生沒有區別。也就是說,GPT-4可以全靠自己考進斯坦福了。’
(Jim Fan自己就是斯坦福畢業的!)
網友:完了,GPT-4一發布,就不需要我們人類了……

讀圖做題小case,甚至比網友還懂梗
GPT-4此次升級的亮點,當然就是多模態。
GPT-4不僅能分析匯總圖文圖標,甚至還能讀懂梗圖,解釋梗在哪里,為什么好笑。從這個意義上說,它甚至能秒殺許多人類。
Open AI稱,GPT-4比以往模型都更具創造力和協作性。它可以生成、編輯和迭代用戶進行創意和技術寫作任務,例如創作歌曲、編寫劇本或學習用戶的寫作風格。
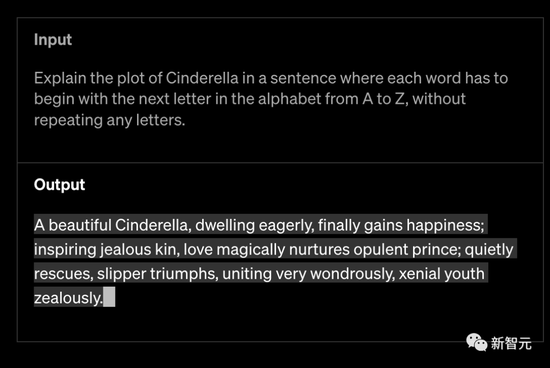
GPT-4可以將圖像作為輸入,并生成標題、分類和分析。比如給它一張食材圖,問它用這些食材能做什么。

另外,GPT-4能夠處理超過25,000字的文本,允許用長形式的內容創建、擴展會話、文檔搜索和分析。
GPT-4在其先進的推理能力方面超過了ChatGPT。如下:

梗圖識別
比如,給它看一張奇怪的梗圖,然后問圖中搞笑在哪里。
GPT-4拿到之后,會先分析一波圖片的內容,然后給出答案。
比如,逐圖分析下面這個。

GPT-4立馬反應過來:圖里的這個‘Lighting充電線’,看起來就是個又大又過氣的VGA接口,插在這個又小又現代的智能手機上,反差強烈。

再給出這么一個梗圖,問問GPT-4梗在哪里?

它流利地回答說:這個梗搞笑的地方在于‘圖文不符’。
文字明明說是從太空拍攝的地球照片,然而,圖里實際上只是一堆排列起來像地圖的雞塊。

GPT-4還能看懂漫畫:為什么要給神經網絡加層數?
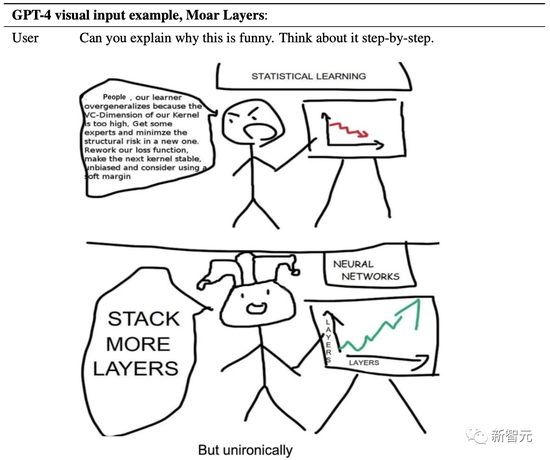
它一針見血地點出,這副漫畫諷刺了統計學習和神經網絡在提高模型性能方法上的差異。

圖表分析
格魯吉亞和西亞的平均每日肉類消費量總和是多少?在給出答案前,請提供循序漸進的推理。
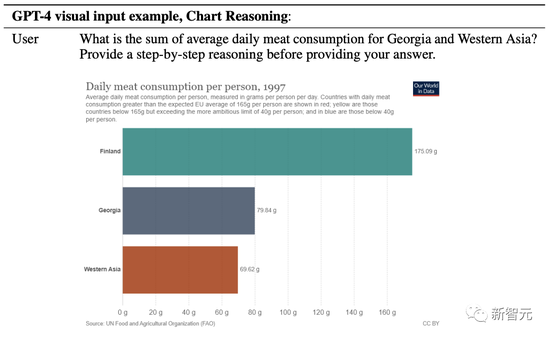
果然,GPT-4清楚地列出了自己的解題步驟——
1. 確定格魯吉亞的平均每日肉類消費量。
2. 確定西亞的平均每日肉類消費量。
3. 添加步驟1和2中的值。

做物理題
要求GPT-4解出巴黎綜合理工的一道物理題,測輻射熱計的輻射檢測原理。值得注意的是,這還是一道法語題。

GPT-4開始解題:要回答問題 I.1.a,我們需要每個點的溫度 T(x),用導電棒的橫坐標x表示。
隨后解題過程全程高能。

你以為這就是GPT-4能力的全部?
老板Greg Brockman直接上線進行了演示,通過這個視頻你可以很直觀的感受到 GPT-4的能力。
最驚艷的是,GPT-4對代碼的超強的理解能力,幫你生成代碼。
Greg直接在紙上畫了一個潦草的示意圖,拍個照,發給 GPT說,給我按照這個布局寫網頁代碼,就寫出來了。
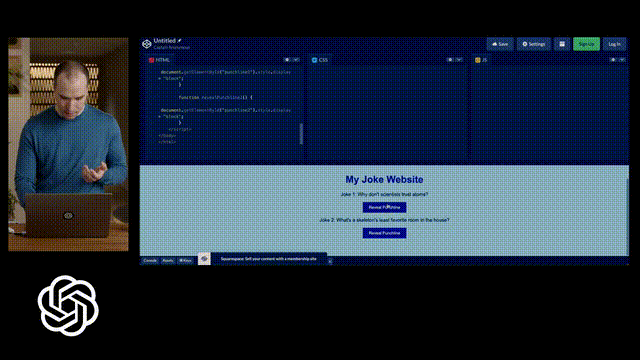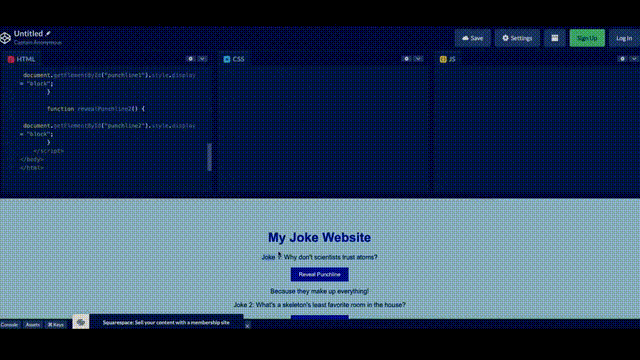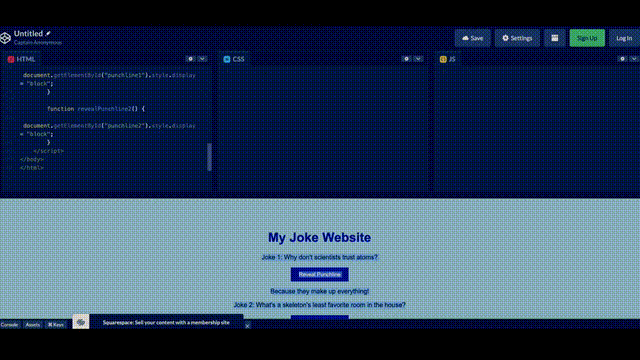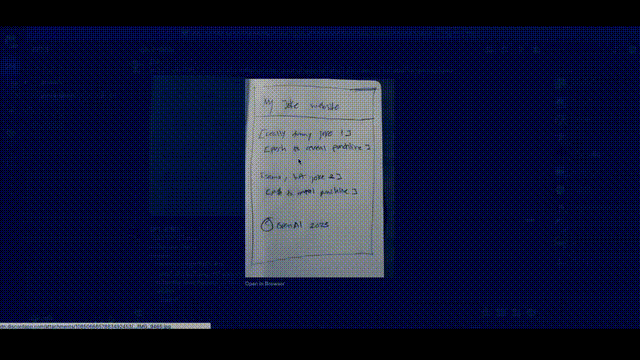
另外,如果運行出錯了把錯誤信息,甚至錯誤信息截圖,扔給GPT-4都能幫你給出相應的提示。
網友直呼:GPT-4發布會,手把手教你怎么取代程序員。

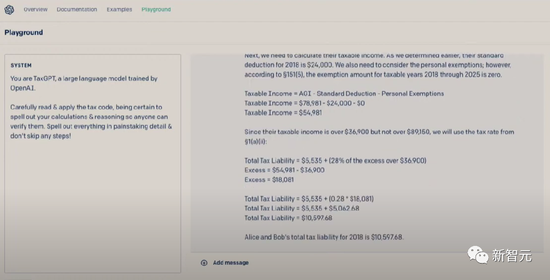
順便提一句,用GPT-4還可以進行報稅 。要知道,每年美國人要花好多時間金錢在報稅上面。
訓練過程
和以前的GPT模型一樣,GPT-4基礎模型的訓練使用的是公開的互聯網數據以及Open AI授權的數據,目的是為了預測文檔中的下一個詞。
這些數據是一個基于互聯網的語料庫,其中包括對數學問題的正確/錯誤的解決方案,薄弱/強大的推理,自相矛盾/一致的聲明,足以代表了大量的意識形態和想法。
當用戶給出提示進行提問時,基礎模型可以做出各種各樣的反應,然而答案可能與用戶的意圖相差甚遠。
因此,為了使其與用戶的意圖保持一致,Open AI使用基于人類反饋的強化學習(RLHF)對模型的行為進行了微調。
不過,模型的能力似乎主要來自于預訓練過程,RLHF并不能提高考試成績(如果不主動進行強化,它實際上會降低考試成績)。
基礎模型需要提示工程,才能知道它應該回答問題,所以說,對模型的引導主要來自于訓練后的過程。
GPT-4模型的一大重點是建立了一個可預測擴展的深度學習棧。因為對于像GPT-4這樣的大型訓練,進行廣泛的特定模型調整是不可行的。
因此,Open AI團隊開發了基礎設施和優化,在多種規模下都有可預測的行為。
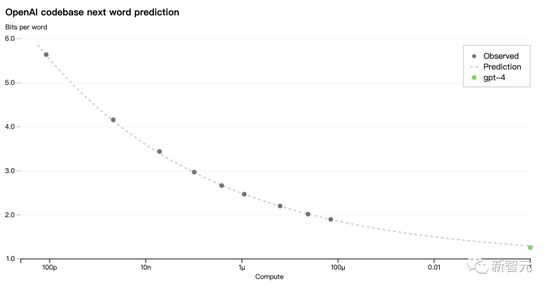
為了驗證這種可擴展性,研究人員提前準確地預測了GPT-4在內部代碼庫(不屬于訓練集)上的最終損失,方法是通過使用相同的方法訓練的模型進行推斷,但使用的計算量為1/10000。
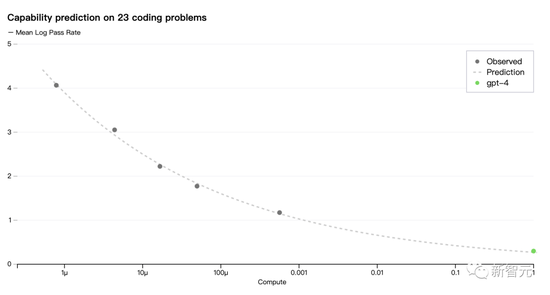
現在,Open AI 可以準確地預測在訓練過程中優化的指標損失。例如從計算量為1/1000的模型中推斷并成功地預測了HumanEval數據集的一個子集的通過率:
還有些能力仍然難以預測。比如,Inverse Scaling競賽旨在找到一個隨著模型計算量的增加而變得更糟的指標,而 hindsight neglect任務是獲勝者之一。但是GPT-4 扭轉了這一趨勢:
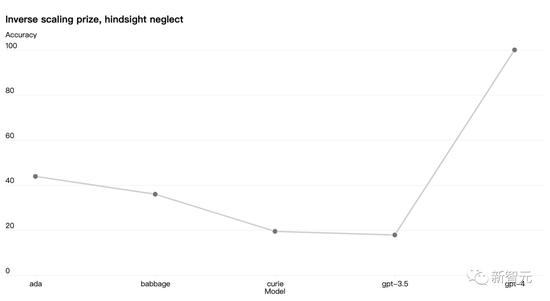
Open AI認為能夠準確預測未來的機器學習能力對于技術安全來說至關重要,但它并沒有得到足夠的重視。
而現在,Open AI正在投入更多精力開發相關方法,并呼吁業界共同努力。
貢獻名單
就在GPT-4發布的同時,Open AI還公開了GPT-4這份組織架構及人員清單。

上下滑動查看全部
北大陳寶權教授稱,
再好看的電影,最后的演職員名單也不會有人從頭看到尾。Open AI的這臺戲連這個也不走尋常路。毫無疑問這將是一份不僅最被人閱讀,也被人仔細研究的‘演職員’(貢獻者) 名單,而最大的看頭,是詳細的貢獻分類,幾乎就是一個粗略的部門設置架構了。
這個很‘大膽’的公開其實意義挺深遠的,體現了Open AI背后的核心理念,也一定程度預示了未來進步的走向。

(聲明:本文僅代表作者觀點,不代表新浪網立場。)

作者簡介




