

AI已經會刷LeetCode了
來源:量子位
夢晨 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
你在面試中會遇到的那種算法題,AI已經能自己解決了,比如下面這道題:
對于一個記錄論文引用次數的數組,每個元素都是非負整數。請寫出函數h_index,輸出這些論文的h指數,即至多有h篇文章被至少引用了h次。
例:
輸入: [3, 0, 6, 1, 4]
輸出: 3
AI給出的Python答案是這樣的:

除了排序沒用counts.sort(reverse = True)讓人看著血壓升高,算是順利通過測試:

來自UC伯克利的研究團隊,將上面這道題被歸為“面試級”難度(看來國外程序員面試題有點簡單)。
此外還有更簡單的“入門級”和更難的“競賽級”,總共5000道題的測試中,AI能做出15%。
另外有人聲稱,他專門用GPT-2訓練了個專門做LeetCode的AI,能完成80%。

在刷LeetCode的你,是否在顫抖?

GPT-Neo贏過GPT-3
本研究使用的題目形式是自然語言題干,不同于以往研究常用的偽代碼和代碼之間翻譯。

題目是從Codeforces、Kattis等刷題網站收集的10000道題,5000道用于訓練,另外5000道作為測試集。
題干的平均長度為293.2個單詞,在測試集中每道題平均有21.2個測試用例。

入門級難度的題不需要復雜算法,有1-2年經驗的程序員都能回答的那種,有3639個。
面試級難度的題會涉及數據結構,比如樹或者圖,或需要修改常見的算法,有5000個。
剩下的是競賽級難度,達到USACO、IOI和ACM等競賽的水平。
研究人員分別訓練了GPT-2的1億參數版和15億參數版、GPT-3以及“高仿版”GPT-Neo。
參數規模“只有”27億的GPT-Neo和更低的GPT-2在測試用例通過率上,表現卻比1750億的GPT-3還要好。

在嚴格模式下,通過所有測試用例才算完全正確,成績最好的GPT-Neo只通過了1.12%,不過這也有56道題了(反正比我強)。

GPT-Neo來自EleutherAI團隊嘗試復現GPT的開源項目。
雖然參數規模比GPT-3小得多,但訓練數據包含了更多技術網站,比如Stack OverFlow和Stack Exchange等,這可能是它在代碼生成上勝出的原因之一。
至于GPT-3為什么表現還不如GPT-2,有人猜測可能是它見過的文本太多,雖然擅長生成自然語言,但在邏輯和解題方面過擬合了。

如何評價AI“做題家”
論文一發出來,吃瓜群眾腦洞大開。
如果我沒通過面試但我寫的算法通過了會怎么樣?

有人回答他:
沒關系,你還可以當你算法的助手。
還有很多人給出下一步建議,比如不用自回歸的GPT,改用自編碼語言模型會怎樣?比如CodeTrans。

或者,再用一個GPT專門生成自己回答不出來的問題。
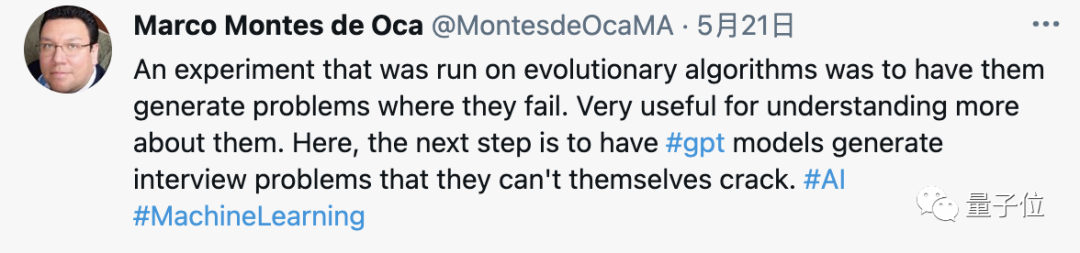 △矛盾相爭是吧
△矛盾相爭是吧樂觀的人認為這是解放了人的創造力,未來編程是關于寫更少的代碼,做更多的架構、工程。

有人暢想,只需要描述需求就能生成代碼可太爽了。
嗨IDE,用我的數據庫做一個JavaScript的增查改刪,要帶測試。
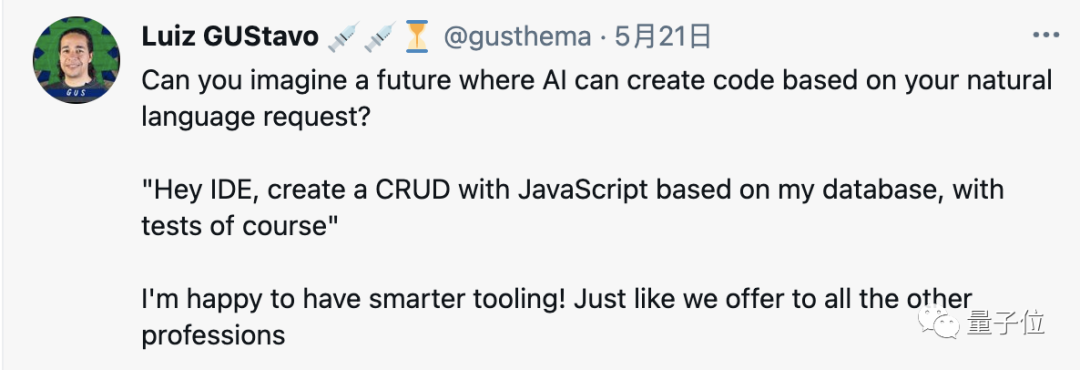 △Ruby on Rails直呼內行
△Ruby on Rails直呼內行悲觀的人卻認為,將來有一天,人類程序員只能做做維護工作和評審機器生成的代碼了。

面對AI“做題家”,你怕了嗎?
論文地址:
https://arxiv.org/abs/2105.09938
數據集地址:
https://github.com/hendrycks/apps

(聲明:本文僅代表作者觀點,不代表新浪網立場。)




